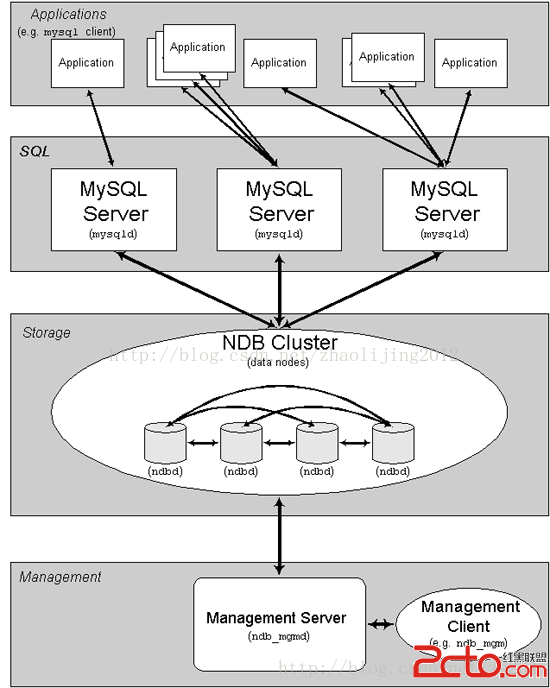
上周去參加了2016 DTCC(數據庫技術大會),會議總共持續3天,議題非常多,我這裡搜集了最新的公開的PPT內容,有興趣的同學可以下載看看,PPT合集下載鏈接為:http://pan.baidu.com/s/1i4XDESX。以下內容是我對聽的幾個議題的一點總結,並歡迎討論。
《時間序列存儲引擎》
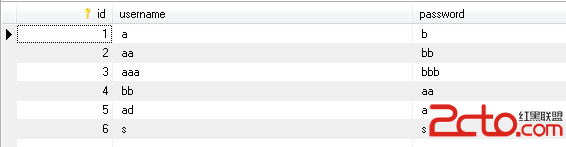
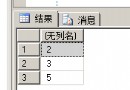
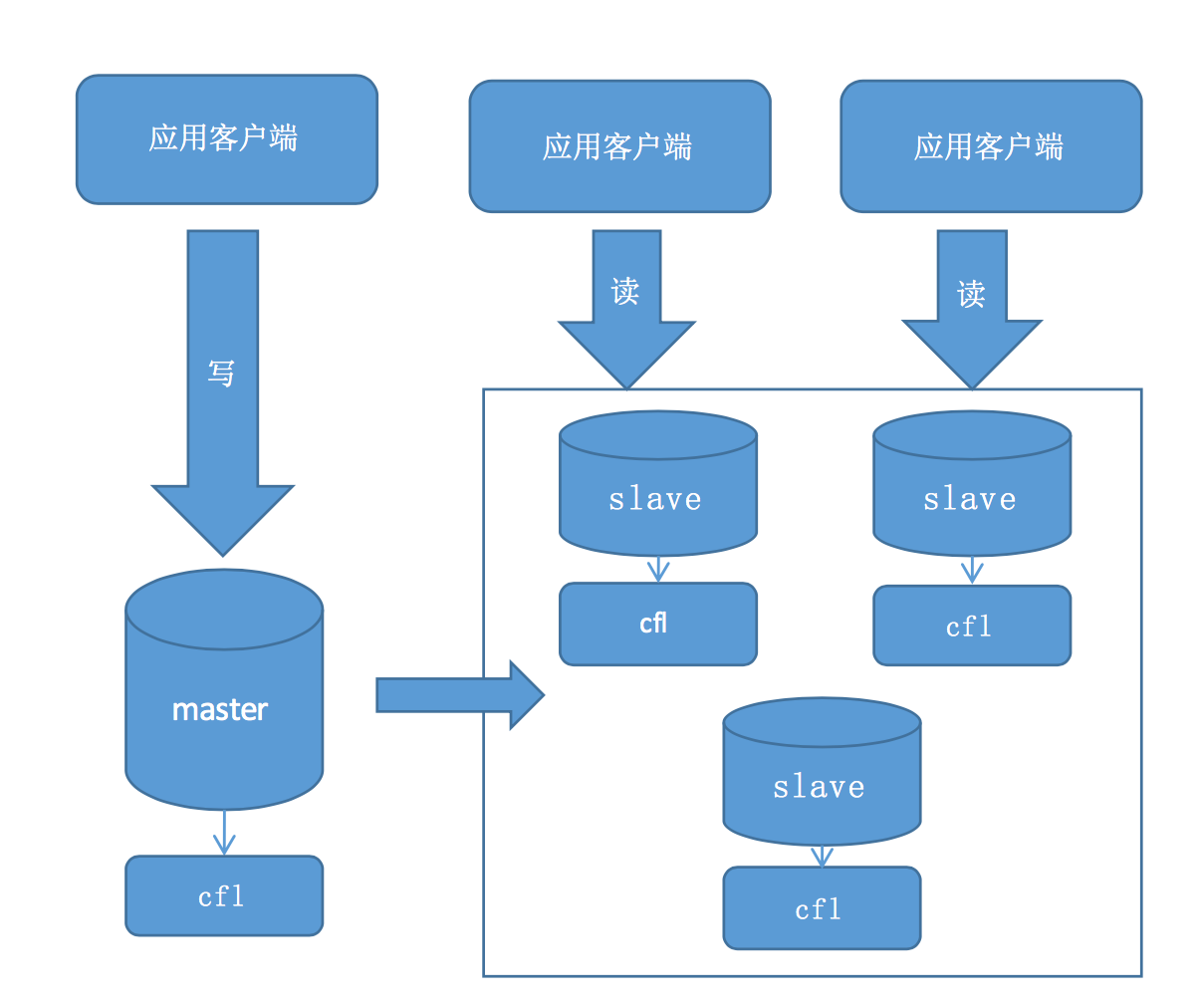
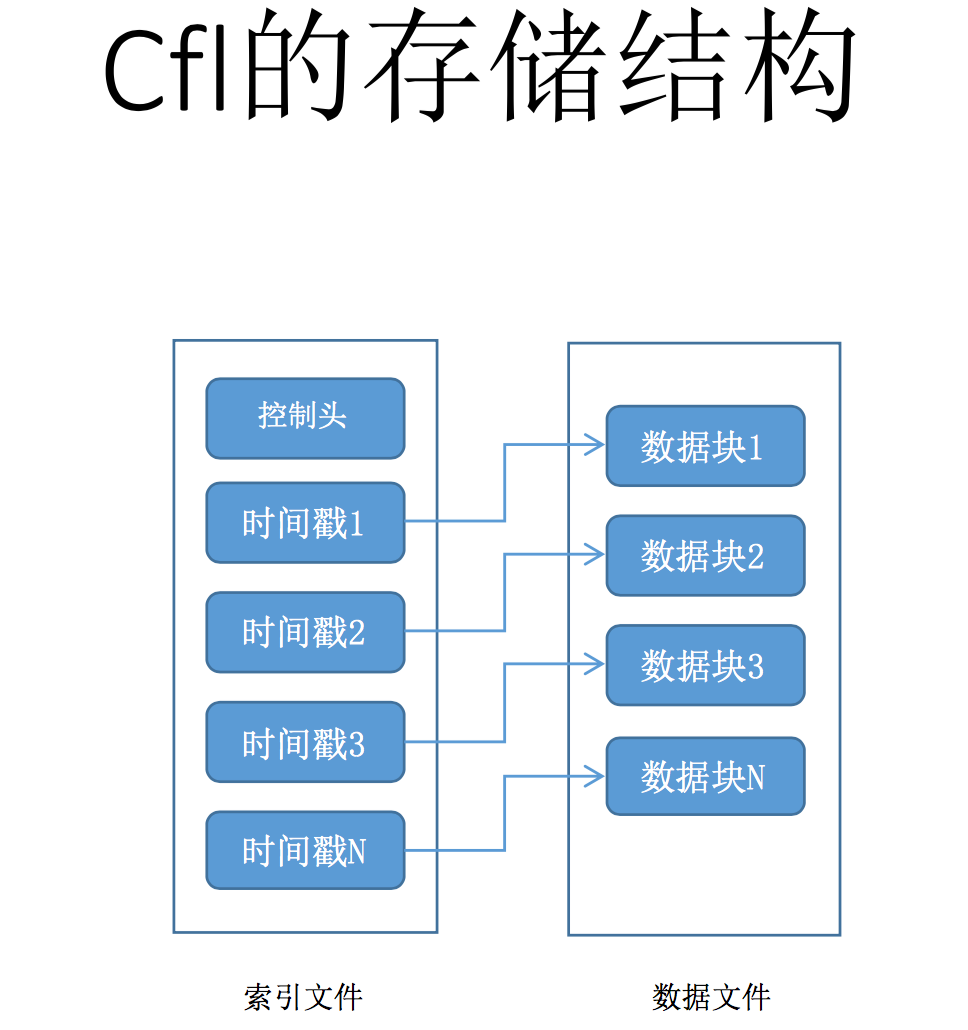
攜程的同學做了一個MySQL時序數據庫引擎(Ctrip fast logging),用於實時收集服務器的狀態信息。時序數據的特點每條信息都包含了時間戳,並且是順序追加的,而且這些信息一般不會發生變更,PPT的內容主要是講如何基於Mysql的框架實現一個存儲引擎,包括相關接口的實現。由於底層存儲格式非常簡單,只支持順序插入,相對於innodb的B+樹非常簡單,因此效率也比較高。但個人感覺既然是收集服務器狀態信息,性能不會成為瓶頸,用普通的innodb或者myisam足以滿足需求,或者對於這種流水型作業用已有方案基於Hbase的OpenTSDB也能滿足需求,我想做這個引擎的最大收益應該是積累引擎開發經驗吧。
《揭開SQL優化的蓋頭來》
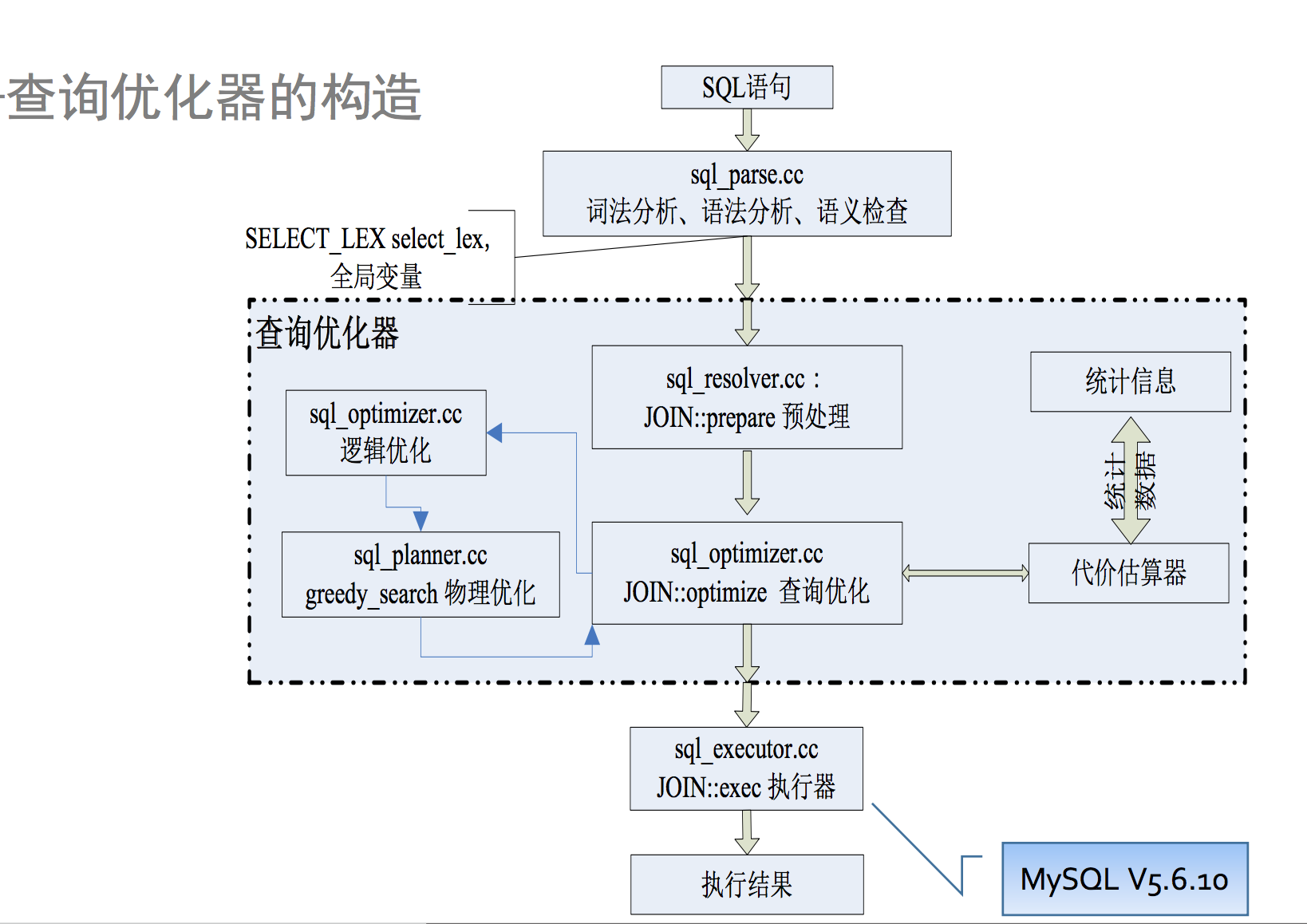
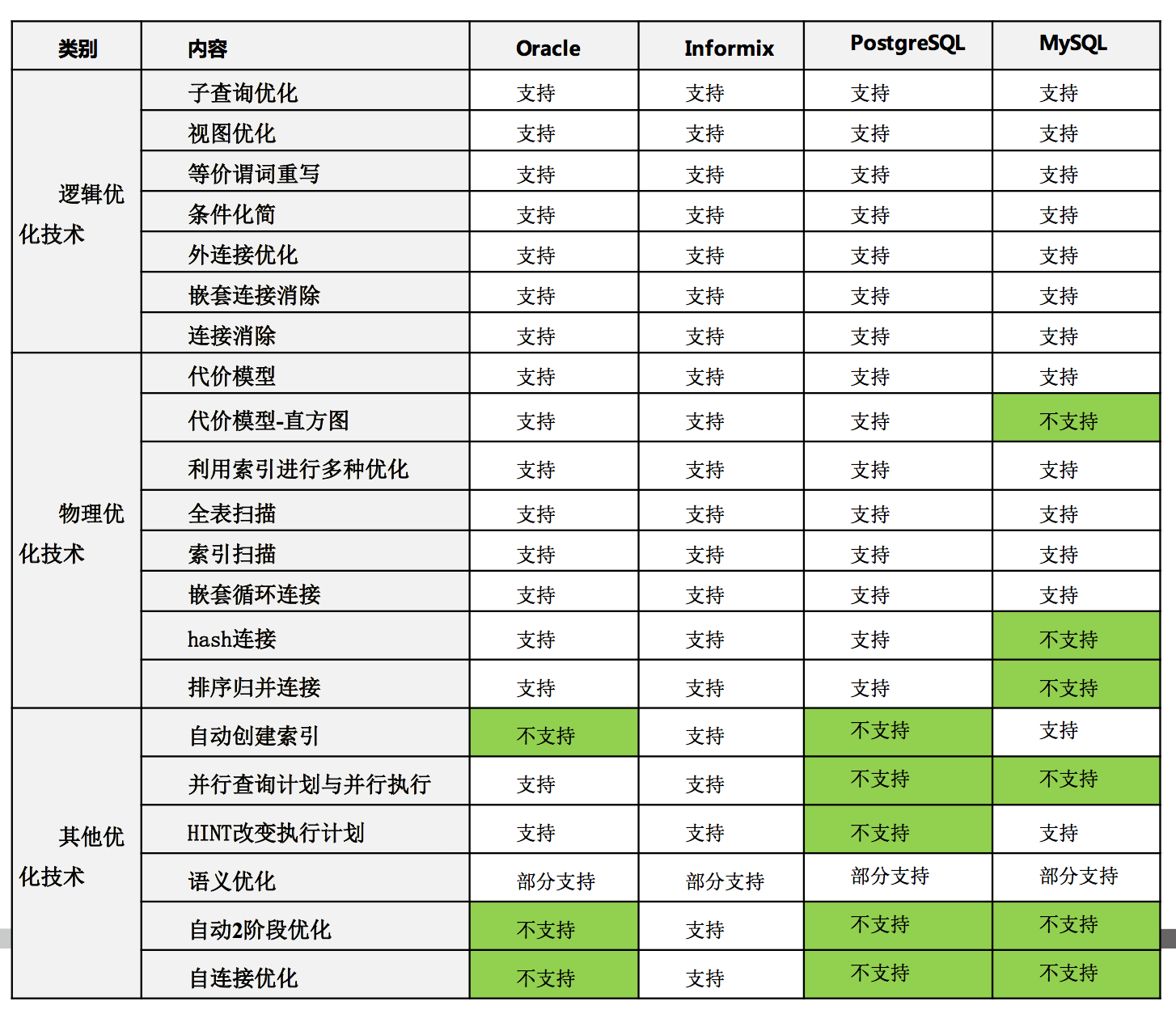
李海翔@那海藍藍老師從理論和實踐上講了一條SQL語句的編譯和優化過程,並介紹了常用的優化技術,包括邏輯優化和物理優化。邏輯優化主要包括子查詢上拉,等價謂詞重寫和外連接消除等;物理優化包括表連接時使用索引,利用索引掃描,group by利用索引,多表連接空間搜索等。最後介紹了各個常用數據庫的優化器功能對比。總體來說,PPT的質量還是很不錯的,對於DBA同學了解SQL執行原理非常有幫助。
《數據庫事務處理原理與實例剖析》
華為的同學講了事務的ACID的原理,並結合PostgreSQL介紹了MVCC機制,鎖機制和故障恢復機制,基本上講清楚了事務的原理和實現,比較偏理論,值得仔細體會。

《華泰證券數據庫分布式架構》
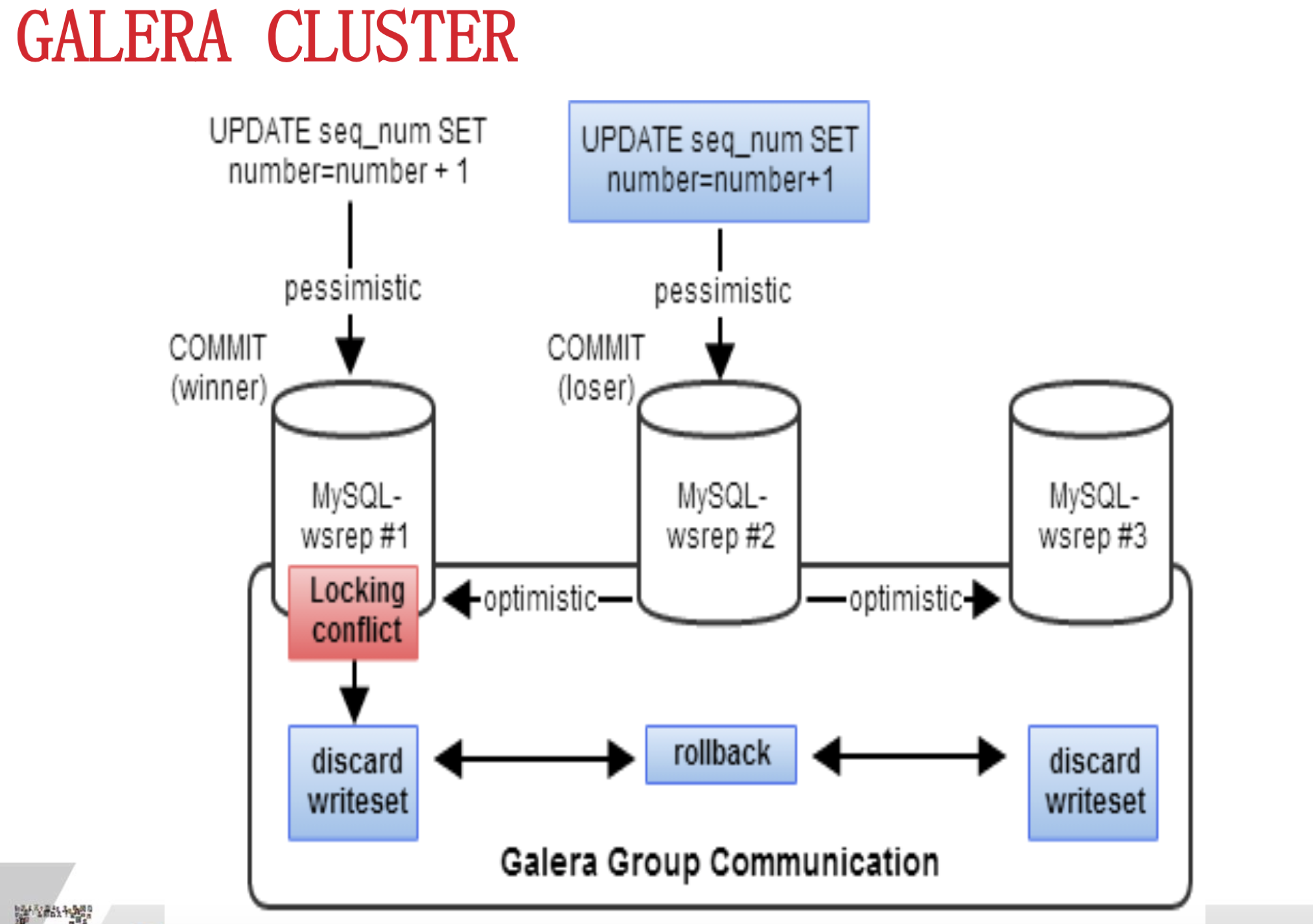
華泰的首席DBA講了他們的Oralce遷移到MySQL後的高可用方案,通過引入中間件作為路由實現分庫分表和讀寫分離,實現數據庫集群水平擴展能力。此外,它們還引入了Galara Cluter集群技術,真正的強同步,數據完全不丟失,也就是PXC(Percona XtraDB Cluster)方案,據我了解,目前去哪兒公司也在用這種架構。這種架構強依賴於網絡,所以他們的集群都是在一個機房的,對於我們同城的主備方案有參考意義,但是跨地域網絡不穩定的場景下,感覺這種方案不太合適。
《RocksDB》
facebook工程師詳細講解了RocksDB的組織結構和存儲原理,RocksDB是對LevelDB做了改進,目前作為MySQL的一個引擎(MyRocks)廣泛應用於facebook生產環境中,並且MariaDB也支持引入了MyRocks引擎。RocksDB底層數據采用LSM(Log Structed Merge) Tree,相對於傳統關系型數據庫采用的以page為單位組織的B+樹結構,更節省磁盤空間(B+樹的page中存在空洞,空間利用率有限),控制寫放大問題也更好(比如B+樹中,更新一條記錄,可能需要寫入一個或多個Page)。RocksDB支持一次獲取多個K-V,還支持Key范圍查找,架構本身對數據自動做到冷熱分離,此外RocksDB支持HDFS。個人感覺在省成本方面,RocksDB引擎是一個可以考慮的方向。MyRocks已經開源,git地址:https://github.com/MySQLOnRocksDB/mysql-5.6
《游戲雲存儲--TSpider分布式數據庫》
騰訊的同學講了他們的中間件方案,采用TSpider引擎的MySQL服務器作為代理,實現分庫分表和讀寫分離的功能。TSpider是基於開源的引擎Spider定制,對性能和穩定性做了一定的優化。由於TSpider實際是Mysql的框架的一個引擎,因此它天然具備了Mysql處理復雜SQL的功能,這個是相對於其它中間件的一個優勢。TSpider相當於中間服務層,自身不存業務數據,只存分區鍵信息和路由信息,TSpider對進行轉發,並聚合查詢結果。