上文介紹了Sphinx的工作原理,關於如何安裝的文章在網上有很多,筆者就不再復述了,現在繼續講解Sphinx的配置文件,讓Sphinx工作起來。
先來看一份數據源的配置文件示例:
1 source test
2 {
3 type = mysql
4
5 sql_host = 127.0.0.1
6 sql_user = root
7 sql_pass = root
8 sql_db = test
9 sql_port = 3306 # optional, default is 3306
10
11 sql_query_pre = SET NAMES utf8
12 sql_query = SELECT id, name, add_time FROM tbl_test
13
14 sql_attr_timestamp = add_time
15
16 sql_query_info_pre = SET NAMES utf8
17 sql_query_info = SELECT * FROM tbl_test WHERE id=$id
18 }
其中
source後面跟著的是數據源的名字,後面做索引的時候會用到;
type:數據源類型,可以為MySQL,PostreSQL,Oracle等等;
sql_host、sql_user、sql_pass、sql_db、sql_port是連接數據庫的認證信息;
sql_query_pre:定義查詢時的編碼
sql_query:數據源配置核心語句,sphinx使用此語句從數據庫中拉取數據;
sql_attr_*:索引屬性,附加在每個文檔上的額外的信息(值),可以在搜索的時候用於過濾和排序。設置了屬性之後,在調用Sphinx搜索API時,Sphinx會返回已設置了的屬性;
sql_query_info_pre:設置查詢編碼,如果在命令行下調試出現問號亂碼時,可以設置此項;
sql_query_info:設置命令行下返回的信息。
1 index test_index
2 {
3 source = test
4 path = /usr/local/coreseek/var/data/test
5 docinfo = extern
6 charset_dictpath = /usr/local/mmseg3/etc/
7 charset_type = zh_cn.utf-8
8 ngram_len = 1
9 ngram_chars = U+3000..U+2FA1F
10 }
其中
index後面跟的test_index是索引名稱
source:數據源名稱;
path:索引文件基本名,indexer程序會將這個路徑作為前綴生成出索引文件名。例如,屬性集會存在/usr/local/sphinx/data/test1.spa中,等等。
docinfo:索引文檔屬性值存儲模式;
charset_dictpath:中文分詞時啟用詞典文件的目錄,該目錄下必須要有uni.lib詞典文件存在;
charset_type:數據編碼類型;
ngram_len:分詞長度;
ngram_chars:要進行一元字符切分模式認可的有效字符集。
1 charset_type = utf8 2 3 ngram_len = 1 4 5 ngram_chars = U+3000..U+2FA1F
1 charset_type = utf8 2 3 charset_dictpath = /usr/local/mmseg3/etc/ 4 5 ngram_len = 0
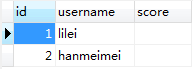
數據庫數據
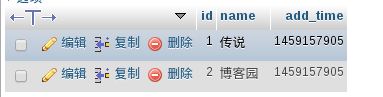
使用indexer程序做索引
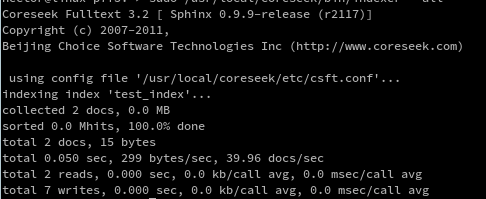
查詢
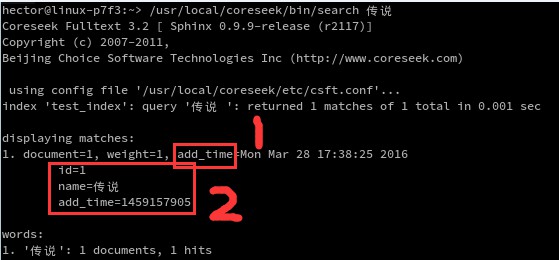
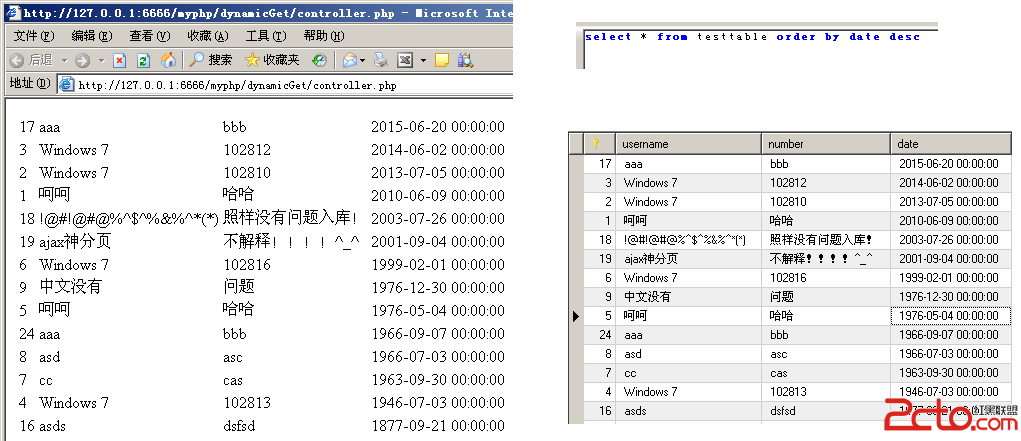
可以看到,配置文件中的add_time被返回了,如上圖的1所示。而sql_query_info返回的信息如上圖的2所示。
Sphinx的配置不是很靈活,此處根據上文的工作流程給出各部分的配置,更多的高級配置可以在使用時查閱文檔。
原創文章,文筆有限,才疏學淺,文中若有不正之處,萬望告知。
如果本文對你有幫助,請點下推薦,寫文章不容易。