Sphinx是一個全文檢索引擎。
遇到一個類似這樣的需求:用戶可以通過文章標題和文章搜索到一片文章的內容,而文章的標題和文章的內容分別保存在不同的庫,而且是跨機房的。
A、直接在數據庫實現跨庫LIKE查詢
優點:簡單操作
缺點:效率較低,會造成較大的網絡開銷
B、結合Sphinx中文分詞搜索引擎
優點:效率較高,具有較高的擴展性
缺點:不負責數據存儲
使用Sphinx搜索引擎對數據做索引,數據一次性加載進來,然後做了所以之後保存在內存。這樣用戶進行搜索的時候就只需要在Sphinx服務器上檢索數據即可。而且,Sphinx沒有MySQL的伴隨機磁盤I/O的缺陷,性能更佳。
1、快速、高效、可擴展和核心的全文檢索
2、高效地使用WHERE子句和LIMIT字句
當在多個WHERE條件做SELECT查詢時,索引選擇性較差或者根本沒有索引支持的字段,性能較差。sphinx可以對關鍵字做索引。區別是,MySQL中,是內部引擎決定使用索引還是全掃描,而sphinx是讓你自己選擇使用哪一種訪問方法。因為sphinx是把數據保存到RAM中,所以sphinx不會做太多的I/O操作。而mysql有一種叫半隨機I/O磁盤讀,把記錄一行一行地讀到排序緩沖區裡,然後再進行排序,最後丟棄其中的絕大多數行。所以sphinx使用了更少的內存和磁盤I/O。
3、優化GROUP BY查詢
在sphinx中的排序和分組都是用固定的內存,它的效率比類似數據集全部可以放在RAM的MySQL查詢要稍微高些。
4、並行地產生結果集
sphinx可以讓你從相同數據中同時產生幾份結果,同樣是使用固定量的內存。作為對比,傳統SQL方法要麼運行兩個查詢,要麼對每個搜索結果集創建一個臨時表。而sphinx用一個multi-query機制來完成這項任務。不是一個接一個地發起查詢,而是把幾個查詢做成一個批處理,然後在一個請求裡提交。
5、向上擴展和向外擴展
6、聚合分片數據
適合用在將數據分布在不同物理MySQL服務器間的情況。
例子:有一個1TB大小的表,其中有10億篇文章,通過用戶ID分片到10個MySQL服務器上,在單個用戶的查詢下當然很快,如果需要實現一個歸檔分頁功能,展示某個用戶的所有朋友發表的文章。那麼就要同事訪問多台MySQL服務器了。這樣會很慢。而sphinx只需要創建幾個實例,在每個表裡映射出經常訪問的文章屬性,然後就可以進行分頁查詢了,總共就三行代碼的配置。
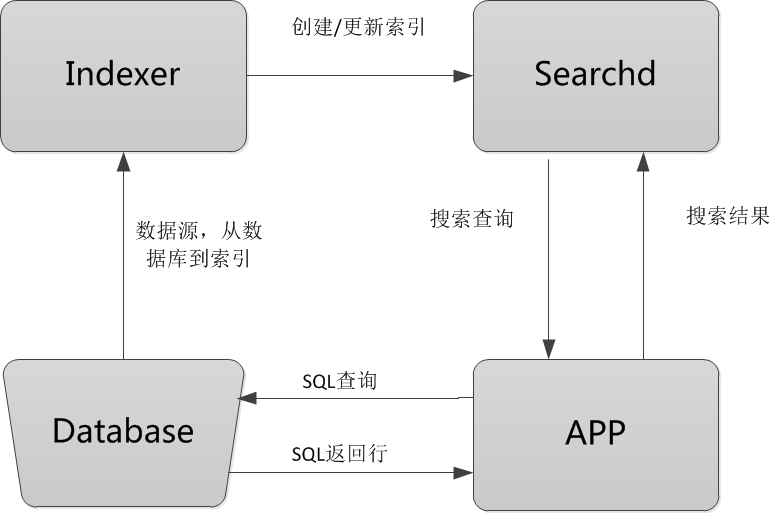
Database:數據源,是Sphinx做索引的數據來源。因為Sphinx是無關存儲引擎、數據庫的,所以數據源可以是MySQL、PostgreSQL、XML等數據。
Indexer:索引程序,從數據源中獲取數據,並將數據生成全文索引。可以根據需求,定期運行Indexer達到定時更新索引的需求。
Searchd:Searchd直接與客戶端程序進行對話,並使用Indexer程序構建好的索引來快速地處理搜索查詢。
APP:客戶端程序。接收來自用戶輸入的搜索字符串,發送查詢給Searchd程序並顯示返回結果。
Sphinx的整個工作流程就是Indexer程序到數據庫裡面提取數據,對數據進行分詞,然後根據生成的分詞生成單個或多個索引,並將它們傳遞給searchd程序。然後客戶端可以通過API調用進行搜索。