MySQL支持幾種基本的數據庫引擎,但並非所有的引擎都支持全文本搜索。兩個最常使用的引擎為MyISAM和InnoDB,前者支持全文本搜索,後者就不支持。
在前面的學習中,我們都知道有兩種方式來匹配文本。一種是使用like關鍵字來進行匹配,另外一種就是使用正則表達式來進行匹配。
雖然使用正則表達式就可以編寫查找所需行的足夠復雜的匹配模式。但是,這些存在幾個重要的限制影響:
1、性能:通配符和正則表達式時嘗試匹配表中所有行,而這些搜索極少使用了表索引,因此,相當慢
2、明確控制:在匹配過程中,我們很少會相當的明確的知道我們想匹配什麼,不匹配什麼。
3、具有優先級的結果:在使用通配符和正則表達式進行匹配時,只是返回包含該匹配條件的結果,而不區分匹配程度(多個匹配和單個匹配的區別,在前面就匹配和在後面匹配的區別)。
上面提到的這些限制,都可以利用全文本搜索來進行解決。
為了進行全文本搜索,必須索引被搜索的列,而且要隨著數據的改變不斷地重新索引。
在對表進行適當的設計之後,MySQL會自動進行所有的索引和重新索引。
在索引之後,select可與match() 和against()一起使用以實際執行索引。
那麼,在建表的時候,如何啟用全文本搜索支持呢???
如下:

上面就這樣通過fulltext 為指定行建立的相應的索引,如果,想指定多個列,將多個列都放入fulltext裡面即可。
在定義之後,MySQL會自動維護該索引。無論是在增加、更新還是刪除,索引也會隨之更新。
上面在建表後此表就有了全文本搜索的能力了,下面我們開始嘗試下全文本搜索。
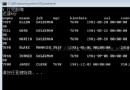
在索引之前,我為test_text表增加了如下內容:

當我們想利用全文本搜索得到 包含MySQL內容的數據。
如下:
select * from test_text where match(content) against('MySQL');
上面語句中 match(content) 指示MySQL針對指定的列進行搜索,注意:傳遞給match()的值必須與fulltext()定義中的相同。against(‘MySQL’)指定詞MySQL作為搜索文本。

從結果可以看出,我們得到了兩行包括MySQL字符串的數據。
上面的搜索利用我們學過的Like也可以完成,如下:

這兩種方法的結果是一樣的。次序也一樣,理論上來說,利用全文本搜索會對出來的結果按照優先級來進行排序輸出,但是從結果可以看出,在第一條語句中MySQL出現的位置相比第二條語句中的MySQL的位置還要滯後,為什麼會出現在前面呢??,與MySQL必知必會上面介紹的有一點出入
為了驗證上面出現的問題,我們可以查下結果的優先級。在查看優先級之前,我又加入了一個以MySQL開頭的行數據。下面舉來看下優先級。
select id,content,match(content) against('MySQL') from test_text ;

從結果可以看出,確實是id=7的行的優先級大於id=8的優先級,原因在於優先級並不至於出現的先後位置有關系,還與諸如文本長度等因素也有關系。
在增加了一行以MySQL開頭的行數據之後,我們來一起觀察下上面這兩種方法的結果。


從上面兩圖可以明顯看出,確實,利用全文本搜索對搜索到的內容進行一定的排序,而通配符卻沒有進行排序。至於全文本搜索對搜索到的內容進行排序由很多因素來進行決定,比如:出現的位置、出現的次數、文本自身的長度等等。
等級越高,出現的位置就越靠前,在我們生活中使用的搜索引擎(例如百度、google等)進行搜索東西的時候,我相信也是按照這樣的邏輯來出現結果,當然除了百度公司收了別人錢把不匹配的內容人為的放在更前面。
前面介紹的只是普通的全文本搜索。
但是,我們在生活中常常有更嚴格的要求,例如,我希望搜索 的內容包括MySQL字符串,你還想得到與MySQL相關的內容(即使沒有出現MySQL字眼),應該怎麼來做呢??
這就需要我們使用查詢擴展了。
用法 :在against(關鍵字 with query expansion) 即可

從結果可以看出,當我們使用了查詢擴展之後,就得到了更多相關的內容,即使這些內容不包括MySQL字眼。
至於MySQL是如何根據MySQL來得到與之相關的關鍵字,目前我還不清楚。
MySQL支持全文本搜索的另外一種形式,稱為布爾方式。以布爾方式,可以提供如下內容的細節:
要匹配的詞; 要排斥的詞、 排列提示(指定某些詞比其他詞更重要,更重要的詞等級更高) 表達式分組。
要說明的是:即使沒有fulltext索引也可以使用,只是速度相當相當的慢。
為顯示 in boolean mode的作用,以一個簡單的例子來進行說明。
select * from test_text where match(content) against('MySQL -interesting' in boolean mode);//返回必須包含MySQL不能包含interesting內容的數據。

關於全文本布爾操作符,見下表(來源於:《MySQL必知必會》這本書)

關於全文本布爾操作符的具體使用實例,與上面的例子類似,這裡不在進行具體介紹。
1、MySQL帶有一個內建的非用詞列表。這些詞在索引全文本數據時總是被忽略。如果需要,可以覆蓋這個列表。
2、許多詞出現的頻率很高,搜索他們沒有用處(因為返回太多的結果)。因此,MySQL規定了一條50%規則,如果一個詞出現在50%以上的行中,則將它作為一個非用詞忽略。50%規則不用於in boolean mode.
3、如果表中的數據的行數小於3行,則全文本搜索不返回結果。因此每個詞要麼不出現,出現就至少為50%。
4、忽略詞中的單引號。例如:don’t 索引為dont。
關於全文本搜索就到這裡就介紹完了,給我的一個感受就是:自己看《MySQL必知必會》這本書的這一節的時候花了10來分鐘就看完了,然而跟著這一節實踐下來加上寫博客的時間,卻花了2個小時之久,雖然花了這麼多時間,但是收獲還是有的,比只看書的理解要更多了一些,以及對match/against的使用要更熟悉的一些。就是因為如此,才有了我一直跟著這本書來了解MySQL的動力,到目前為止,自己跟著這本書已經跟到了18章,前前後後花了將近2周了吧,以前一直以為自己對數據庫的知識還是了解一些的,現在看來以前的自己只懂的數據庫中的”增刪改查”這幾個簡單的步驟。