.1)count
語法如下:
select count(*) from tableName; select count(column_name) from tableName; select count(DISTINCT column_name) from tableName;Note:
.2)group by
分組函數,根據一個列或者多個列多結果集進行分組,常常結合合計函數使用。
語法如下:
SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name
.3)having
sql中出現having函數的原因是where不能跟合計函數一起使用,通俗的將,having就是對where條件下查詢出來的結果進行過濾。
語法如下:
SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name HAVING aggregate_function(column_name) operator value
舉個例子,數據庫表tt中有如下數據:
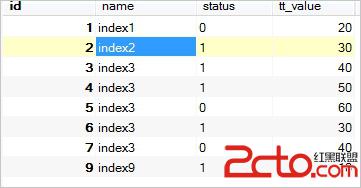
數據庫表tt2的數據如下:
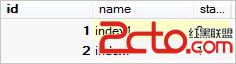
統計表tt中name下各個index的tt_value之和,且統計結果value不小於20;
select name,sum(tt_value) from tt group by name having sum(tt_value)>=20;結果集如下:
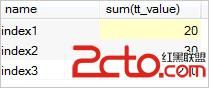
Note:
當同時含有where子句、group by 子句 、having子句及聚集函數時,執行順序如下:
(1)執行where子句查找符合條件的數據;
(2)使用group by 子句對數據進行分組;對group by 子句形成的組運行聚集函數計算每一組的值;
(3)最後用having 子句去掉不符合條件的組。
.4)avg
AVG 函數返回數值列的平均值(NULL 值不包括在計算中).
語法如下:
SELECT AVG(column_name) FROM table_name
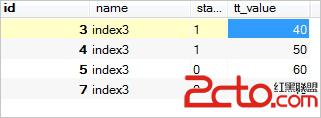
如我們tt表中大於tt_value平均值的列sql如下:
select * from tt where tt_value >(select avg(tt_value) from tt);tt_value中平均值為35,大於35的列如下:
.4)join
多張表通過表中的字段連接起來返回結果,join 有以下幾種類型:
JOIN: 如果表中有至少一個匹配,則返回行
LEFT JOIN: 即使右表中沒有匹配,也從左表返回所有的行
RIGHT JOIN: 即使左表中沒有匹配,也從右表返回所有的行
FULL JOIN: 只要其中一個表中存在匹配,就返回行
下面我們一一介紹以上幾種的用法:
(a)inner join

產生的結果是兩個表的交集。
(b)left join
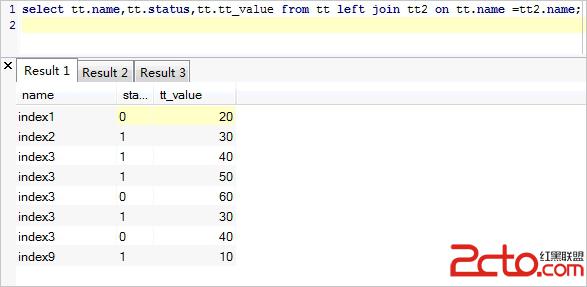
left join 關鍵字會從左表 (tt) 那裡返回所有的行,即使在右表 (tt2) 中沒有匹配的行。
(c)right join
right join 跟left join z正好相反,返回右表中所有的行,即使左標中沒有匹配的行。
(d)full join
可以理解為left join 跟right join 的集合,也就是tt表跟tt2表結果集的並集。
.5)union
將兩個sql的結果合並起來,兩個sql查詢的結果要一致,列的順序也必須一致。
語法如下:
select column1,column2 from table1 union select column1,column2 from table2
執行如下sql:
select name,status from tt union select name,status from tt2;結果集如下:
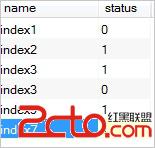
通過tt,tt2的表數據,我們來分析union後的數據結果,發現union函數將重復的記錄給刪除了,並且結果是按照name 進行排序的。
union all
union all 是將兩個sql的結果集合並起來,不會剔除重復的數據,我們執行如下sql
select name,status from tt union all select name,status from tt2;結果集如下:
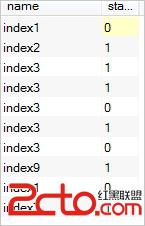
可以看出union跟union all相比,union需要排序並剔除重復的數據,所以性能上較union all要高的多。