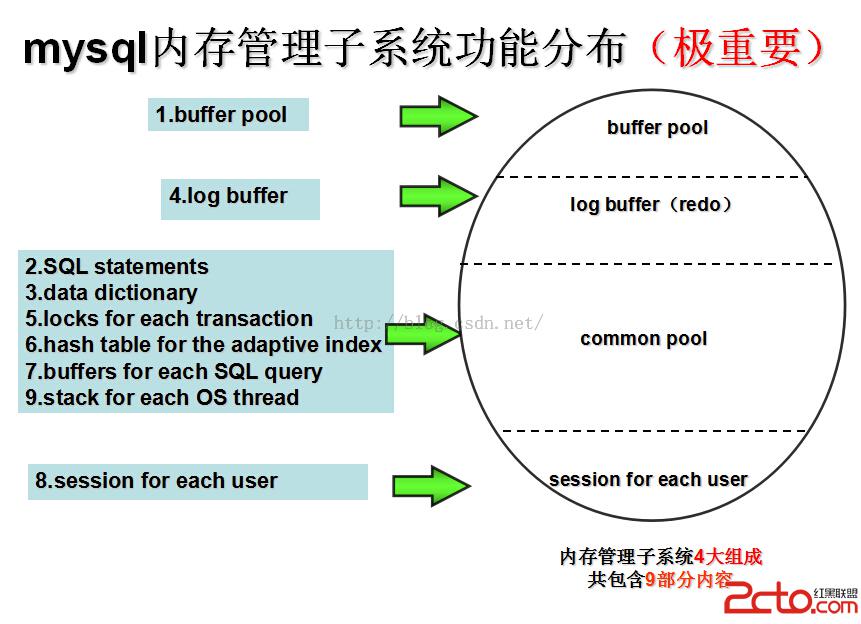
mysql的內存管理龐大而先進,這在mem0pool.c文件的開頭注釋中都有說明,粗略的可以分成四部分,包含9大塊:
buffer pool,
parsed andoptimized SQL statements,
data dictionarycache,
log buffer,
locks for eachtransaction,
hash table forthe adaptive index,
state andbuffers for each SQL query currently being executed,
session foreach user, and
stack for eachOS thread.
9大塊通過4部分進行管理
A solution tothe memory management:
1. the bufferpool size is set separately;
2. log buffersize is set separately;
3. the commonpool size for all the other entries, except 8, is set separately.
也就是緩沖池,redo日志緩沖,普通池和8(用戶session信息,可看做一部分)
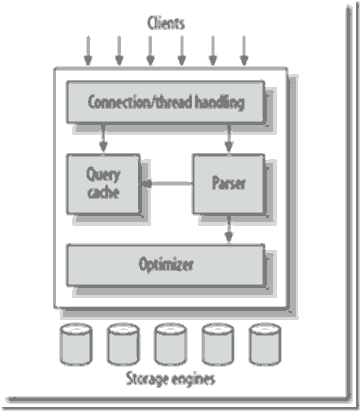
redo日志緩沖由redo部分單獨管理,bufferpool也就是緩沖池是一個復雜的部分,內容很多,普通池上面說了,除了8,和1,2.其余的都歸它管。上面這個結構就是mysql內存子系統的完整圖景。如圖所示:
本篇從緩沖池(buf pool)講起,然後會講解common pool和插入緩存。
在做完整、全面而詳細的緩沖池構架分析之前,必須先要窮舉所涉及到的全部bufpool子系統組件和重點,內容非常之多。
(1)Buf pool五大組成模塊
首先,bufpool子系統可以分成最基本的五個模塊組件。
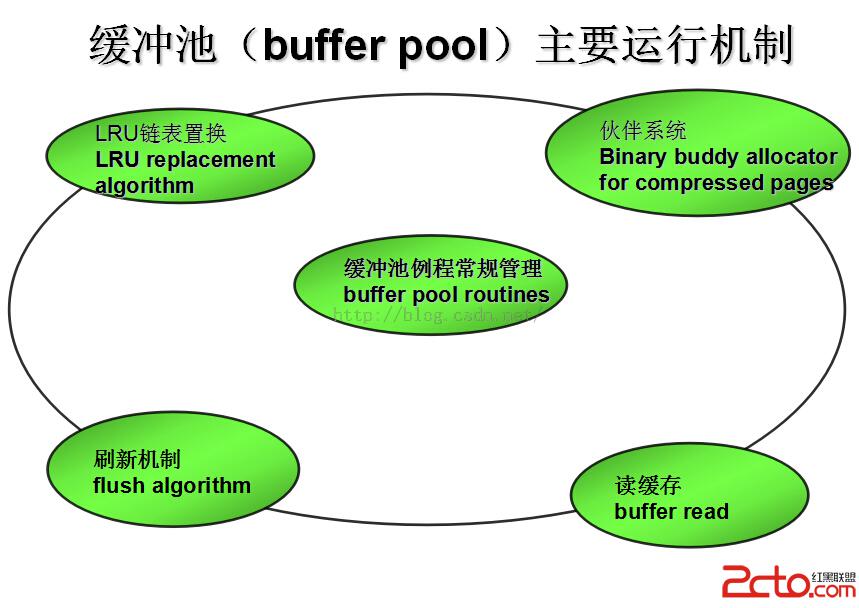
緩沖池例程常規管理(buffer pool routines),進行buf pool(多)實例管理,協調另外四模塊進行運行,對存儲、事務、redo日志、系統主線程等外部子系統等提供調用函數接口,是五個模塊的核心。
LRU鏈表管理(LRU replacement algorithm),buf pool中基礎控制存儲單元(下文即將詳細介紹)如buf_block_struct和buf_page_struct,都需要在對應的非壓縮與壓縮LRU鏈表中進行管理,從設計思想上需要實現加入LRU鏈表節點、刪除LRU鏈表節點兩個基本點,進而需要實現分配塊、釋放塊兩個高級功能,由此衍生出15個可以被外部模塊調用的重要主函數;另外,雖然不為外部接口調用,但與主函數關聯的仍舊有14個重要輔助函數(主函數的全部實現與嵌套細節),這兩部分相當於LRU全部43個函數中的60%以上。
刷新機制(flush algorithm),bufpool部分與底層IO交互最緊密的模塊,直接完成刷新動作,提供的各種刷新接口分別被子系統之內的所有模塊調用。
用刷新方式可以分為:通過LRU鏈表刷新的方式(BUF_FLUSH_LRU)和通過flush鏈表刷新的方式(BUF_FLUSH_LIST)。從功能來說,flush模塊也必然包含flush鏈表的管理功能,實現鏈表節點的插入,刪除,進而實現單塊刷新、臨近頁刷新、doublewrite組件刷新這三個主要功能,並實現外部接口,供事務部分(和mini事務部分)commit動作中實現flush鏈表髒塊的插入。
伙伴系統(Binary buddy allocator for compressed pages),在bufpool裡面,伙伴系統並不是實現統一內存分配管理的單元,它的作用僅僅限於分配buf控制塊(buf_page_struct)所需壓縮頁內存分配動作,但仍具有不可小視的巨大作用。Bufpool最終的目標是為實現各種供文件存儲系統、事務管理、主進程調度單元等使用的外部接口,而這些部分基本都需要或多或少的對buf控制塊中所管理的頁中的數據記錄(buf_block_struct->buf_page_struct.zip.data)進行讀寫操作,在伙伴管理分配內存之後,底層還要根據系統運行需要,進行壓縮頁到非壓縮頁的轉換,可以說是極端重要的一個組件。
讀緩存(buffer read),實現的功能簡單直接,單頁異步讀、隨機讀、線性預讀,運行這些功能的同時也存在著根據不同情況,進行的LRU鏈表(LRU和unzip_LRU)對讀取到的頁的控制塊(buf_block_struct或buf_page_struct)進行節點插入、刪除、置於鏈表末尾等操作,有LRU操作的地方自然也可能存在flush鏈表的刷新動作。
(2)四個重要結構體
其次,在子系統五大組件運行的過程中,涉及到四個重要的結構體,
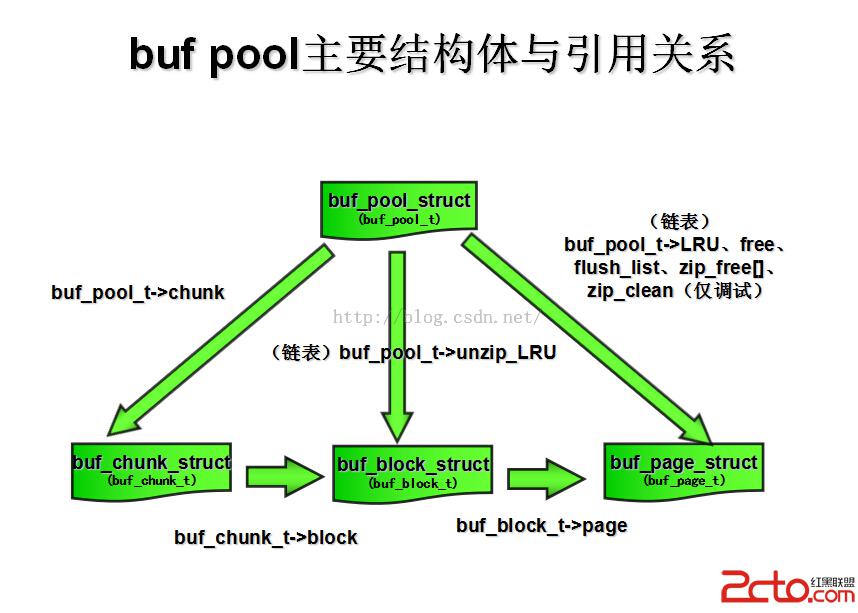
緩沖池控制實例(buf_pool_struct),實現bufpool實例管理的核心數據結構,包含上文提到下文會詳細描述的6大鏈表表頭(UT_LIST_BASE_NODE_T),包含異步IO刷新條件變量(os_event_t)、LRU和flush鏈表互斥體、壓縮與非壓縮頁hash表,上面這些僅僅是最重要部分。
struct buf_pool_struct{
。。。。。。
ulint LRU_old_ratio;
mutex_t LRU_list_mutex;
rw_lock_t page_hash_latch;
mutex_t free_list_mutex;
。。。。。。
hash_table_t* page_hash;
。。。。。。
UT_LIST_BASE_NODE_T(buf_page_t)flush_list;
。。。。。。
UT_LIST_BASE_NODE_T(buf_page_t)free;
。。。。。。
UT_LIST_BASE_NODE_T(buf_page_t)LRU;
。。。。。。
};//結構體的內容難以一時盡述,下文會在每個模塊中需要用到的部分時逐步引用並逐一加以解釋。
底層內存分配單元(buf_chunk_struct),在無數的5.5以上版本mysql內核分析文章中,這個結構體都是最容易被人忽視的部分,但從某個意義上說是極其重要的,因為它最貼近bufpool的底層—OS內存分配,所有的buf控制塊(buf_block_struct),都是掛載到6大鏈表中並可以直接通過的(buf_pool_struct)進行管理,但是這些結構體最初的內存分配動作,都是在(buf_chunk_struct)結構體的初始化階段完成的,(buf_chunk_struct)又是(buf_pool_struct)的最基礎最底層的內存分配單元。雖然這部分在代碼量級上可說是“無足輕重”,但就重要性來講絕對不能無視。
struct buf_chunk_struct{
ulint mem_size; /*!< allocated size of the chunk */
ulint size; /*!< size of frames[] and blocks[] */
void* mem; /*!
wasallocated for the frames */
buf_block_t* blocks; /*!
};//chunk結構體內容較少,此處已經列舉全部內容,下文會根據模塊引用做說明。
非壓縮頁控制塊(buf_block_struct),在網易老姜所著的《mysql內核 innodb存儲引擎卷1》中對此結構體做過描述,隨著版本的變遷和mysql功能的遞進,頁控制塊也進化了,非壓縮頁控制塊(buf_block_struct)的管理與壓縮頁控制塊(buf_page_struct)單獨分開,前者包含後者的結構體引用、物理頁幀地址、unzip_LRU鏈表節點(UT_LIST_NODE_T)、讀寫鎖、互斥體等重要對象,是實現bufpool各種核心接口功能的最關鍵控制單元。
struct buf_block_struct{
buf_page_t page; /*!
bethe first field, so that
buf_pool->page_hashcan point
tobuf_page_t or buf_block_t */
byte* frame; /*!< pointer to buffer frame which
isof size UNIV_PAGE_SIZE, and
alignedto an address divisible by
UNIV_PAGE_SIZE*/
。。。。。。
};//本結構體中其他的部分都先不做任何的列舉,但請一定記住上面這兩個,page非壓縮頁結構體引用壓縮頁結構體的重要句柄,同時也是在一個重要函數中進行強制轉換操作((buf_block_t*) bpage)最關鍵的部分!至於frame則是bufpool部門真正服務的核心所在,這是非壓縮頁(數據頁,undo頁,特殊頁。。。。。。)的頁幀地址。一旦某頁記錄讀入通過read模塊讀入鏈表進行管理之後,那麼它的所有modify操作等同於都是針對這個頁幀裡面做內存修改,至於寫回磁盤是異步(同步)IO需要考慮的事情(詳解文件存儲子系統的時候會對IO機制作出完整說明)。
壓縮頁控制塊(buf_page_struct),理論上講,全部的非壓縮頁只是壓縮頁的子集(實際情況有待本人進一步驗證),因為在進行核心操作的時候,都是在非壓縮頁中進行,因此壓縮頁控制塊(buf_page_struct)並不包含互斥體,但是為了保證與(buf_block_struct)的一致,需要進行鎖計數器的實現,另外,它還包含對應物理頁的表空間id、表空間內頁的偏移量、頁狀態、刷新類型(上文介紹過BUF_FLUSH_LRU和BUF_FLUSH_LIST)、壓縮頁對應引用、所在hash表、5大鏈表(unzip_LRU在非壓縮頁結構體對象(buf_block_struct)所以此處才是剩下的5個鏈表)的子節點(UT_LIST_NODE_T)、以及是否處於OLD_LRU端(LRU鏈表結構old部分)是否崩潰頁初次訪問時間等細節,這些也僅僅是列舉出的最重要結構體對象而已,不是全部。
struct buf_page_struct{
unsigned space:32; /*!
bybuf_pool->mutex. */
unsigned offset:32; /*!
bybuf_pool->mutex. */
。。。。。。
unsigned flush_type:2; /*!< if this block is currently being
flushedto disk, this tells the
flush_type.
@seeenum buf_flush */
unsigned io_fix:2; /*!
alsoprotected by buf_pool->mutex
@seeenum buf_io_fix */
unsigned buf_fix_count:19;/*!< count of howmanyfold this block
iscurrently bufferfixed */
。。。。。。
UT_LIST_NODE_T(buf_page_t)free;
UT_LIST_NODE_T(buf_page_t)flush_list;
UT_LIST_NODE_T(buf_page_t)zip_list;
。。。。。。
};
(3)六個重要鏈表
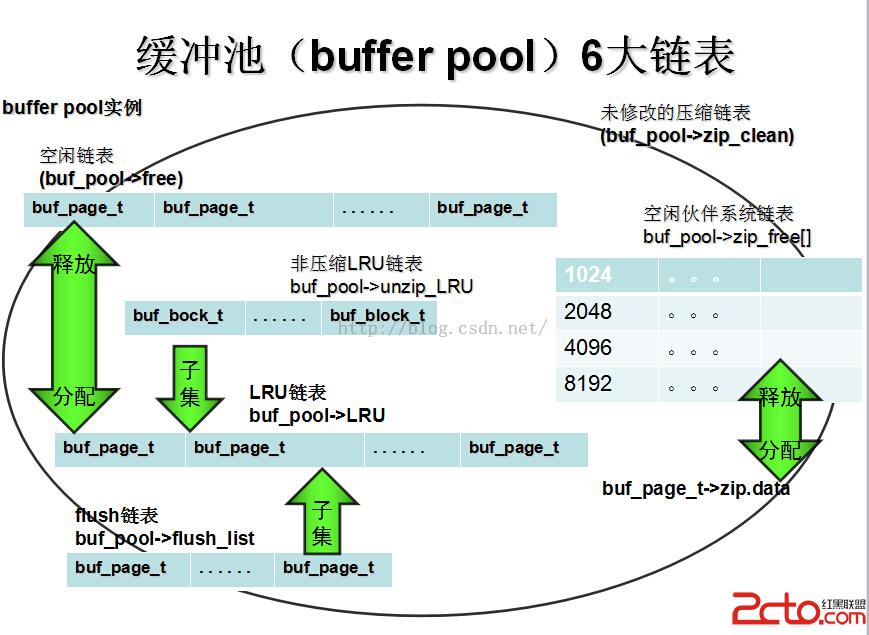
再次,子系統組件與基礎控制結構體運作的過程要實現各種復雜功能,必然無法脫離6個重要的鏈表,
空閒鏈表(buf_pool->free),bufpool最重要的三個鏈表之一,上文已經多次提到LRU和flush等鏈表,但未提到空閒鏈表,實際上它是在系統初始化階段bufpool進行初始化後唯一顯式調用鏈表初始化函數進行init操作的唯一bufpool鏈表。系統內的第一個LRU鏈表塊,必然是從free鏈表中獲取到的,當flush模塊髒頁刷新完成,LRU鏈表節點就會被清除或者移動到LRU鏈表結尾等待清除,清除LRU之後的節點仍舊是回歸到free鏈表內。
LRU鏈表(buf_pool->LRU),bufpool最重要的三個鏈表之二,當有LRU鏈表為空時,必然從free鏈表獲取空閒節點,並進行異步IO讀將頁讀入bufpool,並加入LRU鏈表,LRU鏈表長度過大的情況下,會進行尾部刷新,刷新失敗會進行更徹底的直接通過LRU進行髒頁刷新(BUF_FLUSH_LRU方式),flush鏈表節點得到釋放髒頁完成刷新,並同時把LRU鏈表的髒塊也完成移除。可以說LRU和free、flush三個鏈表、5個模塊有之間有著千絲萬縷的聯系。
非壓縮LRU鏈表(buf_pool->unzip_LRU),本鏈表實際是LRU鏈表的一個子集,在壓縮頁控制塊(buf_page_struct)中的壓縮頁需要進行解壓縮以進行各種記錄級讀寫操作時,該鏈表將發揮作用,因此可以說,插入到了unzip_LRU鏈表就一定頁在LRU鏈表中,反之則未必。
髒塊鏈表(buf_pool->flush_list),bufpool最重要的三個鏈表之二,實際上也是LRU鏈表的子集,所以讀入bufpool的頁都通過壓縮的或者非壓縮的控制塊進行管理,最初一定是在LRU鏈表中,當事務部分(和mini事務部分)完成commit操作時候,實際上就意味著內存寫的成功,髒頁必然要加入flush鏈表,並等待異步IO線程(系統主線程子系統組成之一)進行刷新操作(linux原生異步IO和作者Heikki Tuuri自己用條件變量實現的模擬異步IO,buf_pool_struct提到過,存儲部分會做詳細說明)動作。
未修改壓縮塊鏈表(buf_pool->zip_clean),本鏈表以目前的源代碼來看僅用於調試功能。
伙伴系統空閒鏈表(buf_pool->zip_free[]),bufpool6大鏈表中最特殊的一個,鏈表的根節點可以看做“是一個指針數組”,伙伴系統的精髓就在於按照2的倍數進行緊鄰內存塊的合並和拆分,進而達到高效管理、代碼復雜度低的效果。這個指針數組按照塊大小實際包含4層,1024,2048,4096和8192,每一層基結點只管理同類大小的塊。
關於bufpool部分的整體概述,暫時告一段落,後續還會陸續添加新的內容,並作進一步整理。老劉會堅持把這個分析一直做下去。
下一部分會將LRU進行詳解。如發現文章中的任何錯誤歡迎朋友們指正。