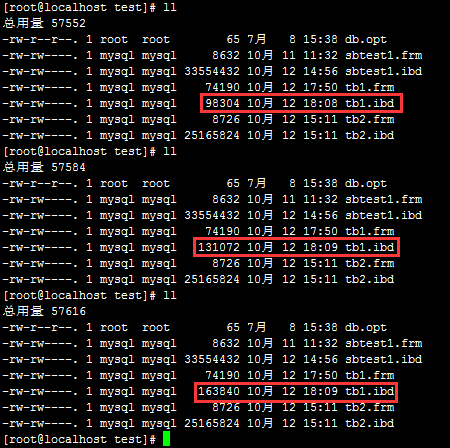
1、什麼是數據的存儲引擎?
存儲引擎就是如何存儲數據、如何為存儲的數據建立索引和如何更新、查詢數據等技術的實現方法。因為在關系數據庫中數據的存儲是以表的形式存儲的,所以存儲引擎也可以稱為表類型(即存儲和操作該表的類型),在Oracle和SQL Server等數據庫中只有一種存儲引擎,所有數據存儲管理機制都是一樣的。而MySQL數據庫提供了多種存儲引擎。用戶可以根據不同的需求為數據表選擇不同的存儲引擎,用戶也可以根據自己的需求編寫自己的存儲引擎。 MySql中有哪些存儲引擎?在實際工作中,選擇一個合適的存儲引擎是一個很復雜的問題。每種存儲引擎都有各自的優勢,不能籠統的說誰比誰更好。下面將詳解不同環境經常用到的存儲引擎和針對各個存儲引擎的特點進行對比,給出不同的選擇建議。
InnoDB是Mysql數據庫的一種存儲引擎。InnoDB給Mysql的表提供了 事務、回滾、崩潰修復能力、多版本並發控制的事務安全、間隙鎖(可以有效的防止幻讀的出現)、支持輔助索引、聚簇索引、自適應hash索引、支持熱備、行級鎖。還有InnoDB是Mysql上唯一一個提供了外鍵約束的引擎。
InnoDB存儲引擎中,創建的表的表結構是單獨存儲的並且存儲在.frm文件中。數據和索引存儲在一起的並且存儲在表空間中。但是默認情況下mysql會將數據庫的所有InnoDB表存儲在一個表空間中的。其實這種方式管理起來非常的不方便而且還不支持高級功能所以建議每個表存儲為一個表空間實現方式為:使用服務器變量innodb_file_per_table = 1。
如果需要頻繁的進行更新、刪除操作的數據庫也可選擇InnoDB存儲引擎。因為該存儲引擎可以實現事務提交和回滾。
MyISAM存儲引擎是Mysql中常見的存儲引擎,MyISAM存儲引擎是基於ISAM存儲引擎發展起來的。MyISAM支持全文索引、壓縮存放、空間索引(空間函數)、表級鎖、延遲更新索引鍵。但是MyISAM不支持事務、行級鎖、更無法忍受的是崩潰後不能保證完全恢復(只能手動修復)。
MyISAM存儲引擎的表存儲成3個文件。文件的名字和表的名字相同。擴展名包含frm、MYD、MYI。其中frm為擴展名的文件存儲表的結構;MYD為擴展名的文件存儲數據,其是MYData的縮寫;MYI為擴展名的文件存儲索引,其為MYIndex的縮寫。
MyISAM存儲引擎的插入數據很快,空間和內存使用比較低。如果表主要是用於插入新記錄和讀出記錄,那麼選擇MyISAM存儲引擎能夠實現處理的高效率。如果應用的完整性、並發性要求很低,也可以選擇MyISAM存儲引擎。
ARCHIVE,見名之意可看出是歸檔,所以歸檔之後很多的高級功能就不再支持了僅支持插入(insert)和查詢(select)兩種功能, ARCHIVE存儲引擎之前還不支持索引(在Mysql5.5以後開始支持索引了),但是它擁有很好的壓縮機制。通常用於做倉庫使用。
ARCHIVE存儲引擎適用於存儲日志信息或其他按時間序列實現的數據采集類的應用場景中。
CSV是將數據文件保存為CSV格式的的文件的,可以方便的導入到其他數據庫中去(例如:excel表格,SQLserver等等),由此需要在數據庫間自由共享數據時才偶爾建議使用此存儲引擎。並且它也不支持索引;個人認為僅適用於數據交換。
BLACKHOLE叫做黑洞,也就是說沒有存儲機制,任何數據都會被丟棄,但是會記錄二進制日志。一般在Mysql復制(中繼服務器)中經常用到,這個在Mysql復制博客中將詳細介紹,敬請關注。
FEDERATED可以實現跨服務器整理表,簡單說就是它可以訪問遠程服務器上數據的存儲引擎,所以說它不再本地創建數據只會自動的建立一個連接到其他服務器上鏈接,有點類似於代理的功能,默認都是禁用的。
MEMORY存儲引擎是Mysql中的一類特殊的存儲引擎。其使用存儲在內存中的內存來創建表,而且所有數據保存在內存中。數據安全性很低,但是查找和插入速度很快。如果內存出現異常就會影響到數據的完整性,如果重啟或關機,表中的所有數據就會丟失,因此基於MEMORY存儲引擎的表的生命周期很短,一般都是一次性的。適用於某些特殊場景像查找和映射,緩存周期性的聚合數據等等。
MRG_MYISAM存儲引擎是合並MyISAM表的,就是將多個MyISAM合並為一個(在用戶看來是一個進行工作,其實是多個底層物理文件在運行工作)。
*修改存儲引擎,可以用命令Alter table tableName engine =engineName
假如,若需要將表user的存儲引擎修改為archive類型,則可使用命令alter table user engine=archive。
*創建數據庫表時設置存儲存儲引擎的基本語法是:
Create table tableName(
columnName(列名1) type(數據類型) attri(屬性設置),
columnName(列名2) type(數據類型) attri(屬性設置),
……..) engine = engineName
事物:
何為數據庫事務 “一榮俱榮,一損俱損”這句話很能體現事務的思想,很多復雜的事物要分步進行,但它們組成一個整體,要麼整體生效,要麼整體失效。這種思想反映到數據庫上,就是多個SQL語句,要麼所有執行成功,要麼所有執行失敗。 數據庫事務有嚴格的定義,它必須同時滿足四個特性:原子性(Atomic)、一致性(Consistency)、隔離性(Isolation)和持久性(Durabiliy),簡稱為ACID。下面是對每個特性的說明: 1. 原子性:表示組成一個事務的多個數據庫操作是一個不可分隔的原子單元,只有所有的操作執行成功,整個事務才提交,事務中任何一個數據庫操作失敗,已經執行的任何操作都必須撤銷,讓數據庫返回到初始狀態; 2. 一致性:事務操作成功後,數據庫所處的狀態和它的業務規則是一致的,即數據不會被破壞。如從A賬戶轉賬100元到B賬戶,不管操作成功與否,A和B的存款總額是不變的; 3. 隔離性:在並發數據操作時,不同的事務擁有各自數據空間,它們的操作不會對對方產生干擾。准確的說,並非要求做到完全無干擾,數據庫規定了多種事務隔離級別,不同隔離級別對應不同的干擾程度,隔離級別越高,數據一致性越好,但並發性越弱; 4. 持久性:一旦事務提交成功後,事務中所有的數據操作都必須被持久化到數據庫中,即使提交事務後,數據庫馬上崩潰,在數據庫重啟時,也必須能保證能夠通過某種機制恢復數據。
在這些事務特性中,數據“一致性”是最終目標,其它的特性都是為達到這個目標的措施、要求或手段。 數據庫管理系統一般采用重執行日志保證原子性、一致性和持久性,重執行日志記錄了數據庫變化的每一個動作,數據庫在一個事務中執行一部分操作後發生錯誤退出,數據庫即可以根據重執行日志撤銷已經執行的操作。此外,對於已經提交的事務,即使數據庫崩潰,在重啟數據庫時也能夠根據日志對尚未持久化的數據進行相應的重執行操作。
和Java程序采用對象鎖機制進行線程同步類似,數據庫管理系統采用數據庫鎖機制保證事務的隔離性。當多個事務試圖對相同的數據進行操作時,只有持有鎖的事務才能操作數據,直到前一個事務完成後,後面的事務才有機會對數據進行操作。Oracle數據庫還使用了數據版本的機制,在回滾段為數據的每個變化都保存一個版本,使數據的更改不影響數據的讀取。
數據並發的問題 一個數據庫可能擁有多個訪問客戶端,這些客戶端都可以並發方式訪問數據庫。數據庫中的相同數據可能同時被多個事務訪問,如果沒有采取必要的隔離措施,就會導致各種並發問題,破壞數據的完整性。這些問題可以歸結為5類,包括3類數據讀問題(髒讀、幻象讀和不可重復讀)以及2類數據更新問題(第一類丟失更新和第二類丟失更新)。下面,我們分別通過實例講解引發問題的場景。
髒讀(dirty read) 在講解髒讀前,我們先講一個笑話:一個有結巴的人在飲料店櫃台前轉悠,老板很熱情地迎上來:“喝一瓶?”,結巴連忙說:“我…喝…喝…”,老板麻利地打開易拉罐遞給結巴,結巴終於憋出了他的那句話:“我…喝…喝…喝不起啊!”。在這個笑話中,飲料店老板就對結巴進行了髒讀。 A事務讀取B事務尚未提交的更改數據,並在這個數據的基礎上操作。如果恰巧B事務回滾,那麼A事務讀到的數據根本是不被承認的。來看取款事務和轉賬事務並發時引發的髒讀場景:
時間 轉賬事務A 取款事務B T1 開始事務 T2 開始事務 T3 查詢賬戶余額為1000元 T4 取出500元把余額改為500元 T5 查詢賬戶余額為500元(髒讀) T6 撤銷事務余額恢復為1000元 T7 匯入100元把余額改為600元 T8 提交事務在這個場景中,B希望取款500元而後又撤銷了動作,而A往相同的賬戶中轉賬100元,就因為A事務讀取了B事務尚未提交的數據,因而造成賬戶白白丟失了500元。在Oracle數據庫中,不會發生髒讀的情況。
不可重復讀(unrepeatable read) 不可重復讀是指A事務讀取了B事務已經提交的更改數據。假設A在取款事務的過程中,B往該賬戶轉賬100元,A兩次讀取賬戶的余額發生不一致:
時間 取款事務A 轉賬事務B T1 開始事務 T2 開始事務 T3 查詢賬戶余額為1000元 T4 查詢賬戶余額為1000元 T5 取出100元把余額改為900元 T6 提交事務 T7 查詢賬戶余額為900元(和T4讀取的不一致)
在同一事務中,T4時間點和T7時間點讀取賬戶存款余額不一樣。
幻象讀(phantom read) A事務讀取B事務提交的新增數據,這時A事務將出現幻象讀的問題。幻象讀一般發生在計算統計數據的事務中,舉一個例子,假設銀行系統在同一個事務中,兩次統計存款賬戶的總金額,在兩次統計過程中,剛好新增了一個存款賬戶,並存入100元,這時,兩次統計的總金額將不一致: 如果新增數據剛好滿足事務的查詢條件,這個新數據就進入了事務的視野,因而產生了兩個統計不一致的情況。
幻象讀和不可重復讀是兩個容易混淆的概念,前者是指讀到了其它已經提交事務的新增數據,而後者是指讀到了已經提交事務的更改數據(更改或刪除),為了避免這兩種情況,采取的對策是不同的,防止讀取到更改數據,只需要對操作的數據添加行級鎖,阻止操作中的數據發生變化,而防止讀取到新增數據,則往往需要添加表級鎖——將整個表鎖定,防止新增數據(Oracle使用多版本數據的方式實現)。 第一類丟失更新 A事務撤銷時,把已經提交的B事務的更新數據覆蓋了。這種錯誤可能造成很嚴重的問題,通過下面的賬戶取款轉賬就可以看出來:
時間 取款事務A 轉賬事務B T1 開始事務 T2 開始事務 T3 查詢賬戶余額為1000元 T4 查詢賬戶余額為1000元 T5 匯入100元把余額改為1100元 T6 提交事務 T7 取出100元把余額改為900元 T8 撤銷事務 T9 余額恢復為1000元(丟失更新)A事務在撤銷時,“不小心”將B事務已經轉入賬戶的金額給抹去了。
第二類丟失更新 A事務覆蓋B事務已經提交的數據,造成B事務所做操作丟失:
時間 轉賬事務A 取款事務B T1 開始事務 T2 開始事務 T3 查詢賬戶余額為1000元 T4 查詢賬戶余額為1000元 T5 取出100元把余額改為900元 T6 提交事務 T7 匯入100元 T8 提交事務 T9 把余額改為1100元(丟失更新)上面的例子裡由於支票轉賬事務覆蓋了取款事務對存款余額所做的更新,導致銀行最後損失了100元,相反如果轉賬事務先提交,那麼用戶賬戶將損失100元。
數據庫鎖機制 數據並發會引發很多問題,在一些場合下有些問題是允許的,但在另外一些場合下可能卻是致命的。數據庫通過鎖的機制解決並發訪問的問題,雖然不同的數據庫在實現細節上存在差別,但原理基本上是一樣的。 按鎖定的對象的不同,一般可以分為表鎖定和行鎖定,前者對整個表進行鎖定,而後者對表中特定行進行鎖定。從並發事務鎖定的關系上看,可以分為共享鎖定和獨占鎖定。共享鎖定會防止獨占鎖定,但允許其它的共享鎖定。而獨占鎖定既防止其它的獨占鎖定,也防止其它的共享鎖定。為了更改數據,數據庫必須在進行更改的行上施加行獨占鎖定,INSERT、UPDATE、DELETE和SELECT FOR UPDATE語句都會隱式采用必要的行鎖定。下面我們介紹一下ORACLE數據庫常用的5種鎖定: l 行共享鎖定:一般通過SELECT FOR UPDATE語句隱式獲得行共享鎖定,在Oracle中你也可以通過LOCK TABLE IN ROW SHARE MODE語句顯式獲得行共享鎖定。行共享鎖定並不防止對數據行進行更改的操作,但是可以防止其它會話獲取獨占性數據表鎖定。允許進行多個並發的行共享和行獨占性鎖定,還允許進行數據表的共享或者采用共享行獨占鎖定; l 行獨占鎖定:通過一條INSERT、UPDATE或DELETE語句隱式獲取,或者通過一條LOCK TABLE IN ROW EXCLUSIVE MODE語句顯式獲取。這個鎖定可以防止其它會話獲取一個共享鎖定、共享行獨占鎖定或獨占鎖定; l 表共享鎖定:通過LOCK TABLE IN SHARE MODE語句顯式獲得。這種鎖定可以防止其它會話獲取行獨占鎖定(INSERT、UPDATE或DELETE),或者防止其它表共享行獨占鎖定或表獨占鎖定,它允許在表中擁有多個行共享和表共享鎖定。該鎖定可以讓會話具有對表事務級一致性訪問,因為其它會話在你提交或者回溯該事務並釋放對該表的鎖定之前不能更改這個被鎖定的表; l 表共享行獨占:通過LOCK TABLE IN SHARE ROW EXCLUSIVE MODE語句顯式獲得。這種鎖定可以防止其它會話獲取一個表共享、行獨占或者表獨占鎖定,它允許其它行共享鎖定。這種鎖定類似於表共享鎖定,只是一次只能對一個表放置一個表共享行獨占鎖定。如果A會話擁有該鎖定,則B會話可以執行SELECT FOR UPDATE操作,但如果B會話試圖更新選擇的行,則需要等待; l 表獨占:通過LOCK TABLE IN EXCLUSIVE MODE顯式獲得。這個鎖定防止其它會話對該表的任何其它鎖定。
事務隔離級別 盡管數據庫為用戶提供了鎖的DML操作方式,但直接使用鎖管理是非常麻煩的,因此數據庫為用戶提供了自動鎖機制。只要用戶指定會話的事務隔離級別,數據庫就會分析事務中的SQL語句,然後自動為事務操作的數據資源添加上適合的鎖。此外數據庫還會維護這些鎖,當一個資源上的鎖數目太多時,自動進行鎖升級以提高系統的運行性能,而這一過程對用戶來說完全是透明的。 ANSI/ISO SQL 92標准定義了4個等級的事務隔離級別,在相同數據環境下,使用相同的輸入,執行相同的工作,根據不同的隔離級別,可以導致不同的結果。不同事務隔離級別能夠解決的數據並發問題的能力是不同的。 表 1 事務隔離級別對並發問題的解決情況
事務的隔離級別和數據庫並發性是對立的,兩者此增彼長。一般來說,使用READ UNCOMMITED隔離級別的數據庫擁有最高的並發性和吞吐量,而使用SERIALIZABLE隔離級別的數據庫並發性最低。
SQL 92定義READ UNCOMMITED主要是為了提供非阻塞讀的能力,Oracle雖然也支持READ UNCOMMITED,但它不支持髒讀,因為Oracle使用多版本機制徹底解決了在非阻塞讀時讀到髒數據的問題並保證讀的一致性,所以,Oracle的READ COMMITTED隔離級別就已經滿足了SQL 92標准的REPEATABLE READ隔離級別。
SQL 92推薦使用REPEATABLE READ以保證數據的讀一致性,不過用戶可以根據應用的需要選擇適合的隔離等級。 JDBC對事務的支持 並不是所有的數據庫都支持事務,即使支持事務的數據庫也並非支持所有的事務隔離級別,你可以通過Connection# getMetaData()方法獲取DatabaseMetaData對象,並通過該對象的supportsTransactions()、supportsTransactionIsolationLevel(int level)方法查看底層數據庫的事務支持情況。Connection默認情況下是自動提交的,也即每條執行的SQL都對應一個事務,為了能夠將多條SQL當成一個事務執行,必須先通過Connection#setAutoCommit(false)阻止Connection自動提交,並可通過Connection#setTransactionIsolation()設置事務的隔離級別,Connection中定義了對應SQL 92標准4個事務隔離級別的常量。通過Connection#commit()提交事務,通過Connection#rollback()回滾事務。下面是典型的JDBC事務數據操作的代碼: 代碼清單 1 JDBC事務代碼
在JDBC 2.0中,事務最終只能有兩個操作:要麼提交要麼回滾。但是,有些應用可能需要對事務進行更多的控制,而不是簡單地提交或回滾。JDBC 3.0(JDK 1.4及以後的版本)引入了一個全新的保存點特性,Savepoint 接口允許你將事務分割為多個階段,你可以指定回滾到事務的特定保存點,而非象JDBC 2.0一樣只回滾到開始事務的點,如圖 1所示:
 圖 1 帶Savepoint的事務
圖 1 帶Savepoint的事務
下面的代碼使用了保存點的功能,在發生特定問題時,回滾到指定的保存點,則非回滾整個事務,如代碼清單 2所示: 代碼清單 2使用保存點的事務代碼
… Statement stmt = conn.createStatement(); int rows = stmt.executeUpdate( "INSERT INTO t_topic VALUES(1,’tom’) " ); Savepoint svpt = conn.setSavepoint("savePoint1");①設置一個保存點 rows = stmt.executeUpdate( "UPDATE t_user set topic_nums = topic_nums +1 "+"WHERE user_id = 1"); … conn.rollback(svpt); ②回滾到①處的savePoint1,①之前的SQL操作,在整個事務提交後依然提交,但①到②之間的SQL操作被撤銷了 … conn.commit();③提交事務 並非所有數據庫都支持保存點功能,你可以通過DatabaseMetaData#supportsSavepoints()方法查看是否支持。
小結 數據一致性和訪問的並發性兩者之間的最佳平衡永遠是數據庫應用程序開發所追求的終極目錄。數據事務是保證數據訪問一致性的不二法門,使用API進行數據庫事務應用開發時,必須深刻了解事務控制屬性對應用性能和數據一致性兩者的影響,並根據項目實際需要進行合理的設置。

 存儲過程通過call來調用。
什麼叫存儲引擎:
MySQL可以講數據以不同的技術存儲在文件或內存中,這種技術就叫存儲引擎。每一種存儲引擎數用不同的存儲機制,索引技巧,鎖定水平,最終提供廣泛切不同的功能。
並發控制:當多個連接對記錄進行操作時保證數據的一致性和完整性。
鎖(是為了解決並發問題)
共享鎖(讀鎖):在同一時間段內,多個用戶可以讀取同一個資源,讀取過程中數據不會發生任何變化。
排他鎖(寫鎖):在任何時候只能有一個用戶寫入資源,當進行寫鎖時會阻塞其他的讀鎖或者寫鎖操作。
鎖的力度(即所得顆粒)
---表鎖,是一種開銷最小的鎖策略。當用戶針對數據表操作時,用戶獲得了這張表的寫鎖權限,寫鎖會禁止其他用戶對這張表的讀寫操作。
---行鎖,是一種開銷最大的鎖策略。也是支持最大並發處理的一種策略。(對數據表的每一行都加鎖,所以它的開銷最大)
索引:是對數據表中一列或多列的值進行排序的一種結構。可快速定位。就相當於書的目錄。
存儲過程通過call來調用。
什麼叫存儲引擎:
MySQL可以講數據以不同的技術存儲在文件或內存中,這種技術就叫存儲引擎。每一種存儲引擎數用不同的存儲機制,索引技巧,鎖定水平,最終提供廣泛切不同的功能。
並發控制:當多個連接對記錄進行操作時保證數據的一致性和完整性。
鎖(是為了解決並發問題)
共享鎖(讀鎖):在同一時間段內,多個用戶可以讀取同一個資源,讀取過程中數據不會發生任何變化。
排他鎖(寫鎖):在任何時候只能有一個用戶寫入資源,當進行寫鎖時會阻塞其他的讀鎖或者寫鎖操作。
鎖的力度(即所得顆粒)
---表鎖,是一種開銷最小的鎖策略。當用戶針對數據表操作時,用戶獲得了這張表的寫鎖權限,寫鎖會禁止其他用戶對這張表的讀寫操作。
---行鎖,是一種開銷最大的鎖策略。也是支持最大並發處理的一種策略。(對數據表的每一行都加鎖,所以它的開銷最大)
索引:是對數據表中一列或多列的值進行排序的一種結構。可快速定位。就相當於書的目錄。
 修改存儲引擎的方法:
1. 通過修改MySQL配置文件實現,在MySQL5.5中默認的存儲引擎是innoDB.
2. 通過創建數據表命令實現:
--create table table_name(
、、、
)ENGINE=engine;
3.通過修改數據表命令實現
--alter table table_name ENGINE[=] engine_name;
MySQL數據庫的優化:
數據庫優化的目的:
1、避免出現頁面訪問錯誤(
由於數據庫連接timeout產生的5XX錯誤
由於慢查詢造成頁面無法加載
由於阻塞造成數據無法提交)
2、 增加數據庫的穩定性(很多數據庫問題都是由於低低效查詢引起的)
3、優化用戶體驗(
流暢頁面的訪問速度
良好的網站功能體)
可以從以下幾個方面進行優化:SQL及索引,數據表結構,系統配置,硬件。其中SQL及索引最重要,首先我們要根據我們的需求寫出結構良好的SQL,另外要根據SQL在表中建立有效的索引,但是如果我們的索引過多,不但會影響我們寫入的效率,同時還會影響我們查詢的效率,所以索引建立要適量有效。但是如果表結構設計不合理,我們就很難寫出結構良好的SQL,所以要建立簡潔明了的表結構,所以說在設計表結構的時候,我們要考慮怎樣對表結構進行查詢,怎樣的表結構的設計才是有利於表結構的查詢,然後是系統配置的優化,但是當前我們大多數的MySQL都是在lnuix系統上,但是系統上是有一些本身的限制,比如說:TCP/IP連接數的限制,打開文件數的限制和一些安全上的限制,因為MySQL查詢是基於文件的,沒查詢一個表就要打開一個文件,如果文件數達到一定的限制,這個文件就無法打開。硬件優化,就是我們要選擇更適合數據庫的CPU,更快的IO,以及更多的內存,數據庫數據要放在內存中查詢修改,所以內存越大,對我們數據庫的性能就越好,但CPU卻不是這樣的,CPU越大,不見得對數據庫性能越好,因為SQL會對CPU的可數有限制,比如說他並不會用到太多的核數,有的查詢他只用於單核,所以說CUP也對數據庫有影響,並不是核數越多越好,而IO,目前由於多新型IO設備,如 ssd,,但它並不能減少數據庫鎖的機制,因為鎖是數據庫保存完整性的一種機制,雖然IO很快,但它並不能減少阻塞,所以我們說硬件上的優化是成本最高但效果最差的,所以說如果慢查詢很多,阻塞很多,那麼並發量就會上去,導致應用響應緩慢。
1.SQL及索引的優化:
對Max(),Count()函數的優化,子查詢的優化,group by 的優化(目的是減少IO),limit優化(使用有索引的列或主鍵進行orderby操作以避免IO)
a. 如何選擇合適的列建立索引:
在where從句,group by, order by,on從句中出現的列建立索引;索引字段越小越好;離散度大的列放到聯合索引的前面。
b.索引的維護及優化------重復及冗余索引和對不用索引的刪除
2.數據庫結構的優化
a.選擇合適的數據類型,數據類型的選擇,重點在於合適,
修改存儲引擎的方法:
1. 通過修改MySQL配置文件實現,在MySQL5.5中默認的存儲引擎是innoDB.
2. 通過創建數據表命令實現:
--create table table_name(
、、、
)ENGINE=engine;
3.通過修改數據表命令實現
--alter table table_name ENGINE[=] engine_name;
MySQL數據庫的優化:
數據庫優化的目的:
1、避免出現頁面訪問錯誤(
由於數據庫連接timeout產生的5XX錯誤
由於慢查詢造成頁面無法加載
由於阻塞造成數據無法提交)
2、 增加數據庫的穩定性(很多數據庫問題都是由於低低效查詢引起的)
3、優化用戶體驗(
流暢頁面的訪問速度
良好的網站功能體)
可以從以下幾個方面進行優化:SQL及索引,數據表結構,系統配置,硬件。其中SQL及索引最重要,首先我們要根據我們的需求寫出結構良好的SQL,另外要根據SQL在表中建立有效的索引,但是如果我們的索引過多,不但會影響我們寫入的效率,同時還會影響我們查詢的效率,所以索引建立要適量有效。但是如果表結構設計不合理,我們就很難寫出結構良好的SQL,所以要建立簡潔明了的表結構,所以說在設計表結構的時候,我們要考慮怎樣對表結構進行查詢,怎樣的表結構的設計才是有利於表結構的查詢,然後是系統配置的優化,但是當前我們大多數的MySQL都是在lnuix系統上,但是系統上是有一些本身的限制,比如說:TCP/IP連接數的限制,打開文件數的限制和一些安全上的限制,因為MySQL查詢是基於文件的,沒查詢一個表就要打開一個文件,如果文件數達到一定的限制,這個文件就無法打開。硬件優化,就是我們要選擇更適合數據庫的CPU,更快的IO,以及更多的內存,數據庫數據要放在內存中查詢修改,所以內存越大,對我們數據庫的性能就越好,但CPU卻不是這樣的,CPU越大,不見得對數據庫性能越好,因為SQL會對CPU的可數有限制,比如說他並不會用到太多的核數,有的查詢他只用於單核,所以說CUP也對數據庫有影響,並不是核數越多越好,而IO,目前由於多新型IO設備,如 ssd,,但它並不能減少數據庫鎖的機制,因為鎖是數據庫保存完整性的一種機制,雖然IO很快,但它並不能減少阻塞,所以我們說硬件上的優化是成本最高但效果最差的,所以說如果慢查詢很多,阻塞很多,那麼並發量就會上去,導致應用響應緩慢。
1.SQL及索引的優化:
對Max(),Count()函數的優化,子查詢的優化,group by 的優化(目的是減少IO),limit優化(使用有索引的列或主鍵進行orderby操作以避免IO)
a. 如何選擇合適的列建立索引:
在where從句,group by, order by,on從句中出現的列建立索引;索引字段越小越好;離散度大的列放到聯合索引的前面。
b.索引的維護及優化------重復及冗余索引和對不用索引的刪除
2.數據庫結構的優化
a.選擇合適的數據類型,數據類型的選擇,重點在於合適,
 b.表的范式化和反范式化(范式化指的是表設計的規則)
反范式化是指為了查詢效率的考慮把原本符合第三范式的表適當的增加冗余,已達到優化效率的目的,反范式化是以空間換時間的做法。
c.表的垂直拆分,解決了表的寬度問題。將不常用的字段拆分出來。
d.表的水平拆分,解決表的數據量過大的問題。
3.系統配置的優化。及MySQL配置文件的優化
SQL語句;
查找:select
b.表的范式化和反范式化(范式化指的是表設計的規則)
反范式化是指為了查詢效率的考慮把原本符合第三范式的表適當的增加冗余,已達到優化效率的目的,反范式化是以空間換時間的做法。
c.表的垂直拆分,解決了表的寬度問題。將不常用的字段拆分出來。
d.表的水平拆分,解決表的數據量過大的問題。
3.系統配置的優化。及MySQL配置文件的優化
SQL語句;
查找:select
 別名:AS
select id AS userId,username AS uname From users;
查詢結果分組:group by
select sex from users group by sex;
分組條件:HAVING +聚合函數、或者是having後的字段出現在select後面。
select age,sex from users group by sex HAVING age>2;
對分組結果進行排序:order by DESC 表示降序 默認為ASC升序
select * from users order by id DESC;
限制查詢結果返回的數量:limit
select * from users LIMIT 2;/LIMIT 2,2 (指的是從第三條開始,限制2條)
插入insert:
insert test(username) select username from users where age>27;
更新:update
子查詢:(not)in,(not)exists
向單表插入:insert table_user1(username) select age from table_user2 group by age;
連接類型:inner join,內連接
在MySQL中,join,cross join 和 inner join 是等價的。
left [outer] join,左外連接
right [outer] join,右外連接
select username,age,sex
inner join user2;
函數:
select CONCAT(username,age) AS u FROM user;//字符串鏈接
聚合函數:Avg(),Count(),Max(),Min(),Sum()
加密函數:MD5(),Password()
別名:AS
select id AS userId,username AS uname From users;
查詢結果分組:group by
select sex from users group by sex;
分組條件:HAVING +聚合函數、或者是having後的字段出現在select後面。
select age,sex from users group by sex HAVING age>2;
對分組結果進行排序:order by DESC 表示降序 默認為ASC升序
select * from users order by id DESC;
限制查詢結果返回的數量:limit
select * from users LIMIT 2;/LIMIT 2,2 (指的是從第三條開始,限制2條)
插入insert:
insert test(username) select username from users where age>27;
更新:update
子查詢:(not)in,(not)exists
向單表插入:insert table_user1(username) select age from table_user2 group by age;
連接類型:inner join,內連接
在MySQL中,join,cross join 和 inner join 是等價的。
left [outer] join,左外連接
right [outer] join,右外連接
select username,age,sex
inner join user2;
函數:
select CONCAT(username,age) AS u FROM user;//字符串鏈接
聚合函數:Avg(),Count(),Max(),Min(),Sum()
加密函數:MD5(),Password()