文章出自:聽雲博客
前段時間,Oracle官方發布了MySQL 5.7的GA版本。新版本中實現了真正意義的並行復制(基於Group Commit的Group Replication),而不再是基於schema的並行復制。這一特性極大的改善了特定場景下的主從復制延遲過高的狀況。隨著MySQL成熟度的提升,越來越多的用戶選擇使用MySQL存放自家的數據,其中不乏使用MySQL來存放大量數據的。
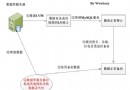
在過去的半年多時間裡,聽雲業務量呈爆發式增長,後端的數據量由去年第一季度的幾TB增長到幾十TB,業務量翻了十幾倍。後端應用及數據庫面臨的一個突出的問題就是頻繁的進行擴容來應對前端流量的增長。數據庫層面我們使用MySQL來分布式存儲業務數據,數據庫集群的架構也比較簡單,我們使用開源中間件Amoeba來實現數據的拆分和讀寫分離。Amoeba後端有幾百個數據庫的節點組,每個節點組中都包含一對主從實例。master實例負責接受write請求,slave負責接受query請求。如下圖:
正確的拆分姿勢
隨著可選擇的開源中間件越來越多,好多數據量並不是很大的使用者都會過早的考慮水平拆分數據庫。但其實過早的水平拆分未見得是一件有意義的事情。主要原因有兩個:一個方面是水平拆分會對現網的業務造成沖擊,如果系統在設計之初就沒有考慮過後續要進行拆分的話,這個沖擊就會被放大。比如業務中有大量的多表join的查詢,或者是對事務有強一致性的要求時,水平拆分就捉襟見肘了。另一方面,如果過早的進行了水平拆分,那麼到達一定程度後再想要垂直進行拆分時,代價是很大的。以聽雲app為例,當我們業務庫拆成8個分片後,有一天發現數據增長的很快,於是決定對其進行垂直拆分,將小時緯度和天緯度的數據拆分到一個新的實例上去,這時我們不得不同時部署8個節點組來將現有的8個分片上的小時緯度和天緯度的數據遷移出來。工作量相當大。如果水平拆分到了64個片,那麼這時要想再做垂直拆分,保證累的你不要不要的。
所以更合理的路線是這樣的,首先對業務數據進行垂直拆分,原本一個庫按業務單元垂直拆分成多個庫,同時應用中配置多個數據源或者使用中間件來訪問拆分後的多個庫,對應用本身來說,基本沒做什麼改動,但是後端存儲的容量和性能卻翻了好幾倍。如果某天出現瓶頸之後,再來考慮水平拆分的事情。
優雅的從n到2n
水平擴展過程中最讓人頭疼的是數據的遷移,以上圖中遷移mod(mobile_app_id,4)=2的數據為例,最開始的做法是先創建兩個新的節點組shared0_new和shared2,拿shared0的全備恢復到shared0_new和shared2,然後在shared0_new上刪除mod(mobile_app_id,4)=2的數據,在shared2上刪除mod(mobile_app_id,4)=0的數據,刪除操作完成後shared0_new、shared2與shared0做同步,同步刪除操作執行過程中的數據增量。同步追上之後,切換amoeba的路由規則,然後下線shared0。這種方式問題很多,首先時耗很高很高,delete完了之後並不能釋放存儲空間,還要optimize table,同樣也是一個漫長的過程。針對大表的delete會產生一個很大的transaction,會在系統表空間中申請很大一塊undo,delete完成後事務提交。這個undo空間並不會釋放,而是直接給其他事務復用,這無疑會浪費很多存儲空間。
後來我們想到一個便捷的辦法,就是利用mysqldump的—where參數,在備份數據的時候加一個mod(mobile_app_id,4)=2的參數,就可以單獨備份出余數為2的數據,然後拿這個邏輯備份恢復到shared2上去,高效且優雅。
數據傾斜
MySQL分布式存儲不可避免的一個問題就是數據傾斜。業務在運行一段時間之後,會發現少部分shared數據增量特別快,原因是該shared上面部分用戶的數據量較大。對於數據傾斜問題我們目前的措施是將這些shared遷移到1TB存儲上來,但這並非長久之計。因此我們目前正在做一些新的嘗試,比如對Amoeba做了一下擴展,擴展後的Amoeba支持將某一個mobile_app_id的數據單獨指向後端一個shared節點組,即一個shared只存放一個用戶的數據,同時采用ToKuDB存儲引擎來存儲這部分數據,ToKuDB能夠對數據進行有效的壓縮,除了查詢性能稍有損耗之外,基本具備InnoDB引擎所擁有的特點,而且在線表結構變更比InnoDB快好幾倍不止。這些測試基本已經進入尾聲,很快將會應用到生產環境。
分布式join
分布式join在業界仍沒有完美的解決方案,好在聽雲業務在設計之初就從業務上避免了多表的join,在業務庫中,報表中的每個緯度都會有一張表與之對應,因此查詢某個緯度直接就會查詢後端的某張表,都是在每張表上做一些操作。目前比較流行的分布式join的解決方案主要有兩種:
1、全局表的形式。舉個栗子,A表 join B表,B表分布式存儲在多個shared上,如果A表比較小,可以在所有的shared上都存一份A表的全量數據。那麼就可以很高效的做join。看起來很美好,但是限制很多,應用的場景也很有限。
2、E-R形式。舉個栗子,用戶表user(id,name)和訂單表order(id,uid,detail),按用戶id分片,order表的uid引用自user表的id。存放訂單時,首先確定該訂單對應用戶所在的shared,然後將訂單記錄插入到用戶所在的shared上去,這樣檢索某個用戶所有的訂單時,就可以避免跨庫join低效的操作。
目前的開源中間件中,MyCat對分布式join處理的是比較細膩的。阿裡的DRDS對於分布式join的處理也是這樣的思路。
MySQL擅長什麼
任何一種工具可能都只是解決某一個領域的問題,肯定不是放之四海而皆准的。正確的使用方式是讓工具做自己擅長的事情。關系型數據庫擅長的是結構化的查詢,本身並不擅長巨量數據的清洗。我們在出2015年度APP行業均值數據報表時,需要將後端所有shared上的相關數據匯總起來然後做進一步的分析,這些數據最終匯總在5張表中,每張表都有幾億條的記錄。然後對5、6個字段group by之後取某些指標的 sum值,最初嘗試在MySQL中處理這些數據,MySQL實例給出24GB的內存,結果OOM了好幾次也沒有出結果。最後把數據拉到了hadoop集群上,使用impala引擎來匯總數據,處理最大的表近7億條記錄,9min左右出結果。所以,不要有all in one的想法,要讓系統中的每個組件做自己擅長的事情。
分布式MySQL架構下的運維
MySQL分布式雖然解決了存儲和性能問題,但是在運維支持過程中卻帶來了一些痛點。
1、跨分片統計數據。中間件是無法對後端的全量數據做查詢的,類似年度APP行業均值報表這樣的跨分片的全量數據的查詢,只能使用自動化腳本從後端逐個shared上提取數據,最終再匯總。
2、DML。經常會有變更表結構的需求,這樣的操作大部分中間件是支持不了的,如果只有一個庫好說,當後端幾十個shared時,就比較頭疼了,目前我們並沒有很好的處理辦法,只能使用自動化腳本批量到後端shared上執行命令,執行完成後,運行一個校驗的腳本,人工核對校驗腳本的輸出內容。
應對這樣的情景,發型必然會稍顯凌亂,但是目前仍舊很無奈,有必要重新設計一下我們的腳本,寫一個輸出更加友好,完全自動化的工具出來。
原文鏈接:http://blog.tingyun.com/web/article/detail/386