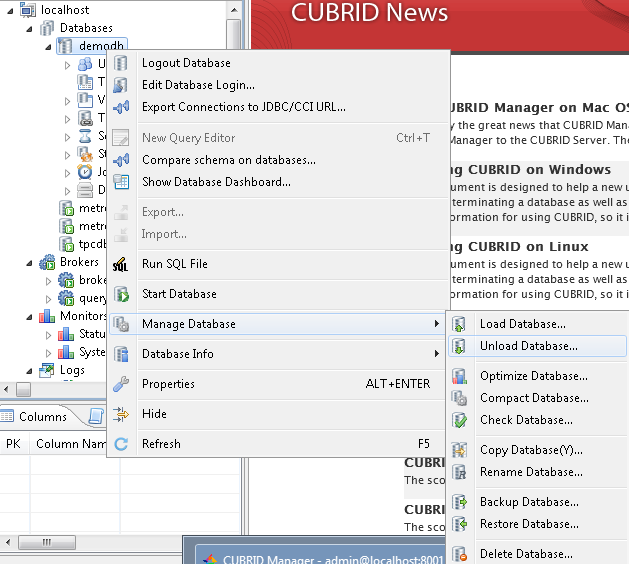
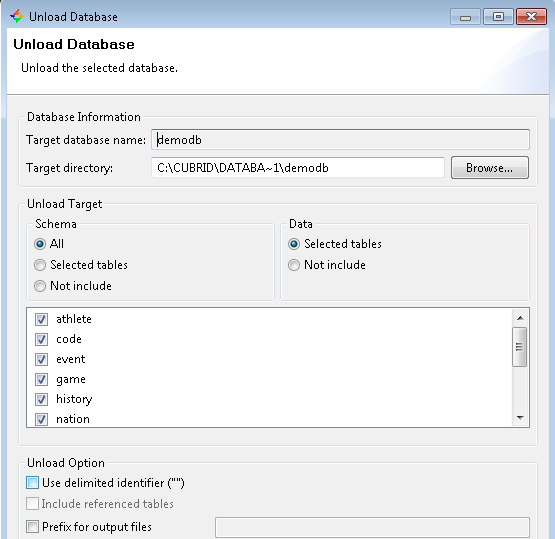
1 export database 類似sqlserver的分離數據庫
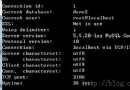
cubrid unloaddb demodb
分離後生成三個文件 demodb_objects, demodb_indexes and demodb_schema .一個保存數據,一個保存索引,一個保存規范定義.
2 創建新的數據庫
cubrid createdb testdb
因為創建的數據庫會在當前目錄. 所以確認你運行命令行的路徑是要存放數據庫的路徑.
3 加載分離的數據庫文件
cubrid loaddb testdb -d demodb_objects -i demodb_indexes -s demodb_schema -u dba
首先確認新建的testdb數據庫沒有運行.
如果你運行的是linux版本,要注意文件的權限.
linux我不懂 看原文http://www.cubrid.org/wiki_tutorials/entry/copy-clone-database
4 啟動數據庫
cubrid server start testdb
歡迎轉載 ,轉載時請保留作者信息。本文版權歸本人所有,如有任何問題,請與我聯系[email protected] 。 過錯
這種方式不保證數據有效性.但是非常快,不是嗎?
這是問題的討論.http://www.cubrid.org/forum/425888
遷移會出現一些垃圾數據. 是排序引起的. 如果是單個數據庫,應該不會有這問題吧.
排序的問題可以通過排序解決.你懂的.
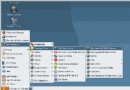
下面是在管理器中 下載數據庫 很簡單 ,看圖就行了