15. 其他存儲引擎... 1
15.1 設置存儲引擎... 3
15.2 MyISAM存儲引擎... 4
15.2.1 MyISAM啟動選項... 5
15.2.2 Key的空間要求... 5
15.2.3 MyISAM表存儲格式... 5
15.2.3.1 靜態表特性... 5
15.2.3.2 動態表特性... 6
15.2.3.3 壓縮表特性... 6
15.2.4 MyISAM表問題... 7
15.2.4.1 MyISAM表損壞... 7
15.2.4.2 表沒有被正確關閉... 7
15.3 MEMORY存儲引擎... 8
15.3.1 性能特點... 9
15.3.2 MEMORY表的物理特性... 9
15.2.3 MEMORY的DDL操作... 9
15.2.4 索引... 9
15.2.5 用戶創建和臨時表... 10
15.2.6 導入數據... 10
15.2.7 MEMORY表和復制... 10
15.2.8 管理內存使用... 10
15.3 CSV存儲引擎... 11
15.3.1 CSV表的檢查和修復... 11
15.3.2 CSV的限制... 11
15.4 ARCHIVE存儲引擎... 12
15.5 BLACKHOLE 存儲引擎... 13
15.7 MERGE存儲引擎... 14
15.7.1 MERGE表的優缺點... 16
15.7.2 MERGE表問題... 16
15.8 FEDERATED存儲引擎... 17
15.8.1 FEDERATED存儲引擎概述... 17
15.8.2 如何創建FEDERATED表... 18
15.8.2.1 使用CONNECTION創建FEDERATED.. 18
15.8.2.2 創建FEDERATED表使用CREATE SERVER. 19
15.8.3 FEDERATED存儲引擎注意點... 20
15.8.4 FEDERATED存儲引擎資源... 21
15.9 EXAMPLE存儲引擎... 21
15.10 其他存儲引擎... 21
15.11 MySQL存儲引擎概述... 21
15.11.1 插件是存儲引擎結構... 21
存儲引擎是MySQL組件,用來控制不同表類型的SQL操作。InnoDB是默認而且是最常用的存儲引擎,Oracle推薦使用,除非是特別的使用場景。
MySQL Server使用可插入的存儲引擎結構可以讓正在運行MySQL的存儲引擎load,unload。
可以使用SHOW ENGINES語句來決定引擎是不是可以使用。Support字段說明引擎是不是被支持。
MySQL 5.6支持的存儲引擎
InnoDB:MySQL 5.6默認的存儲引擎。InnoDB是事務安全的存儲引擎,有commit,rollback,crash-recovery功能來保護用戶數據。InnoDB行級鎖和Oracle樣式的一致性無鎖讀,增加多用戶並發和性能。InnoDB以聚集索引方式存儲用戶數據,對主鍵查詢,可以減少IO。InnoDB也支持外鍵約束。
MyISAM:這些表footprint比較小,表級鎖定限制了讀寫性能,一般用於只讀或者讀多寫少的應用。
Memory:所有的數據都存放在RAM內,能夠快速的訪問數據。這個引擎就是以前的HEAP引擎。
CSV:這個表實際上是文本文件使用了逗號分隔值。CSV表一般用於導入導出,數據線存放在InnoDB,在需要導入導出的時候轉為CSV表。
Archive:這個是緊密的非索引表,用來存儲和獲取大量數據。
Blackhole:這個引擎其實不保存數據,和linux的/dev/null一樣。查詢結果都是為空,這些表可以復制,DML語句會傳到Slave,但是master不保存數據。
Merge:可以讓DBA和開發邏輯的把一些MyISAM表當成一個對象。
Federated:連接到獨立的MySQL服務,在這個邏輯數據庫上為很多歌物理服務創建對象。
Example:這個是MySQL的例子,如何開始編寫新的存儲引擎。。
以下是不同存儲引擎的基本特點:
Feature
MyISAM
Memory
InnoDB
Archive
NDB
Storage limits
256TB
RAM
64TB
None
384EB
Transactions
No
No
Yes
No
Yes
Locking granularity
Table
Table
Row
Row
Row
MVCC
No
No
Yes
No
No
Geospatial data type support
Yes
No
Yes
Yes
Yes
Geospatial indexing support
Yes
No
Yes[a]
No
No
B-tree indexes
Yes
Yes
Yes
No
No
T-tree indexes
No
No
No
No
Yes
Hash indexes
No
Yes
No[b]
No
Yes
Full-text search indexes
Yes
No
Yes[c]
No
No
Clustered indexes
No
No
Yes
No
No
Data caches
No
N/A
Yes
No
Yes
Index caches
Yes
N/A
Yes
No
Yes
Compressed data
Yes[d]
No
Yes[e]
Yes
No
Encrypted data[f]
Yes
Yes
Yes
Yes
Yes
Cluster database support
No
No
No
No
Yes
Replication support[g]
Yes
Yes
Yes
Yes
Yes
Foreign key support
No
No
Yes
No
No
Backup / point-in-time recovery[h]
Yes
Yes
Yes
Yes
Yes
Query cache support
Yes
Yes
Yes
Yes
Yes
Update statistics for data dictionary
Yes
Yes
Yes
Yes
Yes
[a] InnoDB support for geospatial indexing is available in MySQL 5.7.5 and higher.
[b] InnoDB utilizes hash indexes internally for its Adaptive Hash Index feature.
[c] InnoDB support for FULLTEXT indexes is available in MySQL 5.6.4 and higher.
[d] Compressed MyISAM tables are supported only when using the compressed row format. Tables using the compressed row format with MyISAM are read only.
[e] Compressed InnoDB tables require the InnoDB Barracuda file format.
[f] Implemented in the server (via encryption functions), rather than in the storage engine.
[g] Implemented in the server, rather than in the storage engine.
[h] Implemented in the server, rather than in the storage engine.
當你創建新表,你會指定存儲引擎,在ENGINE選項上。
-- ENGINE=INNODB not needed unless you have set a different
-- default storage engine.
CREATE TABLE t1 (i INT) ENGINE = INNODB;
-- Simple table definitions can be switched from one to another.
CREATE TABLE t2 (i INT) ENGINE = CSV;
CREATE TABLE t3 (i INT) ENGINE = MEMORY;
當你忽略ENGINE選項,就是用默認存儲引擎。目前默認存儲引擎是InnoDB。你可以 指定默認存儲引擎通過—default-storage-engine啟動參數,或者配置文件中指定default-storage-engine。也可以在runtime設置使用set命令設置變量:
SET default_storage_engine=NDBCLUSTER;
臨時表的存儲引擎,通過create temporary table來創建,默認存儲引擎通過default_tmp_storage_engine在啟動前或者runtime設置。
可以使用alter table語句來轉化表的存儲引擎
ALTER TABLE t ENGINE = InnoDB;
如果指定的存儲引擎沒有被編譯或者已經編譯了但是沒有激活,MySQL會使用默認存儲引擎來代替。為了防止被魔火,可以啟動NO_ENGINE_SUBSTITUTUIN SQL模式。如果指定的引擎不可用,會產生一個錯誤,而不是一個警告,表不會被創建。
對於新表,frm文件用來保存表和列的定義。表的索引和數據可能被存放在其他一個或者多個文件中,根據存儲引擎決定。
MyISAM的基本特性:
Storage limits
256TB
Transactions
No
Locking granularity
Table
MVCC
No
Geospatial data type support
Yes
Geospatial indexing support
Yes
B-tree indexes
Yes
T-tree indexes
No
Hash indexes
No
Full-text search indexes
Yes
Clustered indexes
No
Data caches
No
Index caches
Yes
Compressed data
Yes[a]
Encrypted data[b]
Yes
Cluster database support
No
Replication support[c]
Yes
Foreign key support
No
Backup / point-in-time recovery[d]
Yes
Query cache support
Yes
Update statistics for data dictionary
Yes
每個MyISAM表被存儲在3個文件。文件以表名開頭,並且有一個擴展名。Frm文件保存了表格式。Myd文件包村了數據文件,myi保存了索引文件。
可以通過mysqlcheck客戶端,或者myisamchk工具,來檢查和修復myisam表。也可以使用myisampack來壓縮myisam表。
MyISAM主要由以下幾個特點:
1.所有數據低字節先存。
2.所有數值類型高字節先存。
3.可以支持large files,最大63bit文件長度。
4.MyISAM最大行數2^32^2
5.每個MyISAM表64個索引,每個列最多16個索引
6.最大key為1000個字節。
7.當行被順序插入,比如使用了auto_increment列,提高空間使用率。
8.支持一個表一個auto_increment列。
9.動態行大小,減少碎片。
10.MyISAM支持並發插入,如果表沒有空閒的blocks你可以插入一個新行的同事,其他表讀取表。
11.可以把數據文件目錄和索引文件目錄放在不同的目錄上,在create table的時候指定data directory和index directory。
12.BLOB,TEXT可以被索引。
13.NULL值可以在所有列中
14.每個字符列可以有不同的字符集
15.每個MyISAM的索引文件有個標記表示表是否給關閉。
16.myisamchk標記呗檢查過的表,如果使用了update-state選項。如果使用—fast選項不會被標記
17.myisamchk –analyze保存了部分可以的統計信息
18.myisampack可以壓縮blob和varchar列
其他支持的特性:
1.支持varchar類型
2.varchar列可能固定或者動態行大小
3.varchar,char的長度最多為64KB。
4.任意長度的unique約束
具體看:http://dev.mysql.com/doc/refman/5.7/en/myisam-start.html
MyISAM表使用B樹索引。你初略的計算index文件的大小,(key_length+4)*0.67,覆蓋所有key。不壓縮的key評估的大小。
String索引空間可以被壓縮。如果索引的第一個部分是string,也會使用前綴壓縮。索引壓縮會讓索引文件變小。
在MyISAM表你可以前綴壓縮個數通過PACK_KEYS=1來指定,在創建表的時候。個數代表錢幾個字節。
靜態表也就是固定行長度的表。沒有可變長字段。每個行使用固定長度字節。
靜態格式是最簡單,醉漢全的模式。也是最快的,因為可以快速的定位到某一行。通過行號乘以行的長度。
如果電腦crash但是mysql還在運行。Myisamchk可以簡單的發現那個是行的開始和結束,所以通常可以全部回收上除非被部分寫入。
靜態表的一些特性:
1.char和varchar使用空白填充。Binary和varbinary使用0x00填充。
2.快速
3.cache簡單
4.crash重構很簡單,因為行位置是固定的。
5.不需要重組除非刪除了大量的行需要歸還空間給OS。
6.空間比動態表消耗的多。
動態表是表中包含了可變長的列,或者表使用ROW_FORMATE_DYNAMIC創建。
動態格式比靜態的有一點復雜,每個行的頭都包含了行的長度。行也可以被碎片化。因為沒有連續的空間存放。
你可以使用OPTIMIZE_TABLE或者myisamchk –r來整理表的碎片。如果是固定長度的列也包含了可變長的列。那麼如果把變長列移動到其他地方那麼固定長度的就不需要整理了。
動態格式有以下特性:
1.所有的字符創都是動態的,除非長度超過4
2.每個行前面都有一個bitmap,用來表示那些列時空字符串或者是0。但是不包含為null的值。如果字符串列的長度是0,或者數值型值是0,空間被刪除只是在bitmap上面標記。
3.空間比靜態的少。
4.每個行只用要求的空間。如果行變大,會分為很多碎片,比如,你更行了一行行變長了,但是變得碎片。
5.和靜態表不同,crash之後要重組,因為行是碎片的,可能會丟失。
6.行長度計算公式如下:
3
+ (number of columns + 7) / 8
+ (number of char columns)
+ (packed size of numeric
columns)
+ (length of strings)
+ (number of NULL columns + 7) / 8
可以使用myisamchk –ed查看連接碎片的連接,這些連接可以通過optimize table或者myisamchk –r移除。
標錯存儲米歐式是只讀的,使用myisampack工具生成。亞水表可以使用myisampack解壓。
壓縮表有以下特性:
1.壓縮表空間占用少。
2.每行獨立的被壓縮,行頭被壓縮成1到3個字節,根據表中的最大行來決定。每個列壓縮也不同。壓縮類型:
a.後綴壓縮
b.前綴壓縮
c.數值列使用bit來代替0
d.如果int型,使用最小的長度來存儲值。比如bigint的列,如果值在-128到127 可以使用smallint。
e.如果表只有很少的值,表類型就會被轉為ENUM。
f.列可以使用很多上面組合的壓縮類型。
3.可以是靜態表或者動態表。
出現以下情況MyISAM表就有可能被損壞:
1.mysqld在寫入時被kill
2.異常的電腦關閉。
3.硬件錯誤。
3.使用外部程序比如myisamchk來修改表,但是服務也同時在修改。
4.軟件bug,可能是mysql的或者是MyISAM的
通常表損壞的症狀:
1.可能會在select數據的時候出現以下錯誤。
Incorrect key file for table: '...'. Try to repair it
2.查詢沒有完成,返回了一個未完成錯誤。
你可以通過CHECK TABLE檢查MyISAM的表,並且聽過REPAIR TABLE修復損壞的MyISAM表。當服務沒有啟動可以通過myisamchk來修復和檢查損壞表。
如果表損壞很頻繁,你可以嘗試確定為什麼會出現。最重要的損壞是服務crash。你可以通過error log的restarted mysqld信息來驗證,是否頻繁crash。如果不是crash那麼就有可能是bug。
每個MyISAM表包含索引文件,上面有個計數器用來檢查表是否被正確關閉。如果在check table或者myisamchk的時候有以下信息:
clients are using or haven't closed the table properly
這個信息表示表已經損壞,至少要檢查該表。
計數器工作如下:
1.第一次表被MySQL更新,計數器自增1
2.在被更新的時候,計數器不變化。
3.當表的最後一個實例被關閉,計數器自減。
4.當你修復表或者檢查表並且發現是沒問題的,計數器會被重置為0.
5.為了避免問題,和其他操作交互的時候會檢查表,如果計數器是0就不會被減。
也就是說,計數器只有在以下條件會變不正確:
1.MyISAM表被復制沒有使用LOCK TABLES並且FLUSH TABLES.
2.MySQL在update和最後關閉之前crash。
3.表使用myisamchk –recover或者myisam –update-state和mysqld同時運行。
4.多個mysqld服務使用了這個表並且一個服務商在執行REPAIR TABLE或者CHECK TABLE,另外一份服務在運行。CHECK TABLE是安全的,你可以沖其他服務上得到警告。但是REPAIR TABLE應該避免因為當一個服務覆蓋了數據文件,另外一個服務是不知道的。
一般不使用多個服務共享數據文件。
MEMORY存儲引擎創建特別目的的表,表內容是存放在內存中的。用戶只能用來做臨時的工作區或者只讀cache。MEMORY存儲引擎特性。
Storage limits
RAM
Transactions
No
Locking granularity
Table
MVCC
No
Geospatial data type support
No
Geospatial indexing support
No
B-tree indexes
Yes
T-tree indexes
No
Hash indexes
Yes
Full-text search indexes
No
Clustered indexes
No
Data caches
N/A
Index caches
N/A
Compressed data
No
Encrypted data[a]
Yes
Cluster database support
No
Replication support[b]
Yes
Foreign key support
No
Backup / point-in-time recovery[c]
Yes
Query cache support
Yes
Update statistics for data dictionary
Yes
[a] Implemented in the server (via encryption functions), rather than in the storage engine.
[b] Implemented in the server, rather than in the storage engine.
[c] Implemented in the server, rather than in the storage engine.
什麼時候使用MEMORY或者MySQL Cluster。開發想要部署使用了MEMORY的應用程序,高可用或者頻繁更新數據要考慮MySQL Cluster是不是最好的選擇。通常使用MEMORY涉及到以下特性:
1.操作相關的短暫的,非重要數據的管理或者cache。當MySQL服務夯住或者重啟,MEMORY表的數據就會丟失。
2.內存存儲訪問快速,並且延遲低。數據可以填充到內存不會導致操作系統swap到虛擬內存。
3.只讀或者讀多的數據訪問模式。
MySQL Cluster提供和MEMORY相似的功能提高性能,提供額外的特性MEMORY不支持的:
1.行級鎖並且多線程操作,client減低爭用。
2.可擴展性,甚至語句和寫入混合。
3.數據持久性的後台操作
4.shared-nothing的結構,多host操作不會有單點錯誤。
5.自動數據分布,應用程序不需要參與用戶sharding或者分區解決方案。
6.支持可變長字段,MEMORY不支持。
MEMORY性能受限於單線程執行結果和更新的時候表鎖。當實例負荷增加,語句混合了寫入會限制可擴展性。
盡管MEMORY表,可能沒有InnoDB速度快,對於繁忙的系統。特殊情況下,更新的表級鎖可能會影響其他線程對MEMORY表的操作。
根據查詢的不同,你可以創建索引,比如默認的hash數據結構,或者b樹結構。
MEMORY存儲引擎都有個相關的磁盤文件,用來保存表定義。表名.frm。
MEMORY表有以下幾個特性:
1.MEMORY表使用小的block,表使用動態hash存儲,沒有一處或者額外的key空間。刪除行把空間放到一個鏈表。當你插入的時候會重新使用。MEMORY表在插入和刪除混合沒有什麼問題。
2.內存表固定長度。可變長度類型比如varchar也以固定長度保存。
3.內存表不能包含BLOB,TEXT裂隙
4.MEMORY支持AUTO_INCREMENT列
5.沒有零食內存表可以被所有客戶端共享,可其他臨時表一樣。
創建MEMORY表只要指定ENGINE=MEMORY。表被存放在內存,默認使用hash所有,hash索引可以讓單個值更快的被查找,可以創建零食表。當服務關閉,所有MEMORY中的數據就會丟失。表會一直存在,因為表定義文件是存放在磁盤的。
MEMORY表的由系統變量,max_heap_table_size決定,默認是16MB,強制不同的大小,可以修改這個變量。這個值可以在CREATE TABLE,ALTER TABLE,TRUNCATE TABLE上被定義。服務重啟也可以設置MEMORY表的最大大小到max_heap_table_size。
MEMORY存儲引擎支持hash和b樹索引。你可以通過using子句來設置:
CREATE TABLE lookup
(id INT, INDEX USING HASH (id))
ENGINE = MEMORY;
CREATE TABLE lookup
(id INT, INDEX USING BTREE (id))
ENGINE = MEMORY;
MEMORY表最多可以有64個索引,每個索引16個列。最多key長度為3072個字節。
如果MEMORY表hash索引的列包含在很多索引中,yodate表影響字段的值會影響性能。性能影響和被幾個索引引用有關。你可以使用b樹索引來避免問題。
MEMORY表可以是非唯一的key。
索引列的值可以是null
MEMORY表內容存儲在內存中,這個是MEMORY表共享內部臨時表的目的。有2種表類型不同,MEMORY表的目的不是為了存數據方便,但是內部臨時表卻是:
1.內部臨時表變的太大,服務自動會轉化為磁盤表。
2.用戶創建的MEMORY表不會存到磁盤。
為了MEMORY表,當服務啟動你可以使用—init-file。你也可以使用INSERT INTO … SELECT或者LOAD DATA INFILE到文件沖持久性表裡面導入數據。
當服務的MEMORY表在shutdown的時候就丟失。如果服務是master,slave不會在意這些表是不是變空了,所以可以從slave中看到以前的數據。為了同步master和slave,當master使用memory表,先使用delete語句刪除所有記錄,這樣slave也會刪除所有記錄。Slave在master重啟和第一次使用表之間還是會有過期數據。因此為了避免可以在master上使用—init-file選項。
服務需要有足夠的內存來維護所有MEMORY表。
內存並不會因為刪除個別的行而使用減少,內存只有在整個表刪除的時候才會釋放。刪除行的內存會被新增的行重用。為了縮放所有的內存你可以執行delete或者truncate table來刪除所有的行。或者直接drop table。為了釋放刪除行的內存,可以通過alter table engine=memory來重建表。
每行的內存使用公式如下:
SUM_OVER_ALL_BTREE_KEYS(max_length_of_key + sizeof(char*) * 4)
+ SUM_OVER_ALL_HASH_KEYS(sizeof(char*) * 2)
+ ALIGN(length_of_row+1, sizeof(char*))
ALIGN()表示向上取證,因為sizeof(char*) 在32位是4個字節,在64位是8個字節。
Max_heap_table_size表示最大的MEMORY表的大小。在創建表的時候。可以設置session的值,如,以下腳本創建了2個MEMEORY表,一個是1MB一個是2MB。
mysql> SET max_heap_table_size = 1024*1024;
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE TABLE t1 (id INT, UNIQUE(id)) ENGINE = MEMORY;
Query OK, 0 rows affected (0.01 sec)
mysql> SET max_heap_table_size = 1024*1024*2;
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE TABLE t2 (id INT, UNIQUE(id)) ENGINE = MEMORY;
Query OK, 0 rows affected (0.00 sec)
如果服務重啟後,2個表都是從全局的max_heap_table_size裡面獲取最大值。
你也可以在創建MEMORY的表上設置max_rows。
CSV存儲引擎支持CHECK,REPAIR語句來檢查和修復損壞的CSV表。
當運行CHECK語句,CSV文件會檢查字段的分隔符是否正確。發現一個不可用的行就會報錯。檢查表如下:
mysql> check table csvtest;
+--------------+-------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+--------------+-------+----------+----------+
| test.csvtest | check | status | OK |
+--------------+-------+----------+----------+
1 row in set (0.00 sec)
如果檢查錯誤,表會被標記為crashed。一旦表被標記為損壞,當你check或者執行select 的時候會自動修復。相關的錯誤狀態和形狀帶會在運行check的時候被顯示:
mysql> check table csvtest;
+--------------+-------+----------+----------------------------+
| Table | Op | Msg_type | Msg_text |
+--------------+-------+----------+----------------------------+
| test.csvtest | check | warning | Table is marked as crashed |
| test.csvtest | check | status | OK |
+--------------+-------+----------+----------------------------+
2 rows in set (0.08 sec)
為了修復表可以運行REPAIR,這個副本盡量復制所有存在的數據,並且替換現在的CSV文件。損壞的記錄就會被丟失。
CSV存儲引擎不能定義索引。
分區也不支持。
使用CSV創建的表必須要有not null屬性。如果用了之前的MySQL創建的nullable列可以繼續使用。
ARCHIVE存儲引擎是特殊目的的,用來保存大量的非索引數據。
ARCHIVE特性如下:
Storage limits
None
Transactions
No
Locking granularity
Row
MVCC
No
Geospatial data type support
Yes
Geospatial indexing support
No
B-tree indexes
No
T-tree indexes
No
Hash indexes
No
Full-text search indexes
No
Clustered indexes
No
Data caches
No
Index caches
No
Compressed data
Yes
Encrypted data[a]
Yes
Cluster database support
No
Replication support[b]
Yes
Foreign key support
No
Backup / point-in-time recovery[c]
Yes
Query cache support
Yes
Update statistics for data dictionary
Yes
[a] Implemented in the server (via encryption functions), rather than in the storage engine.
[b] Implemented in the server, rather than in the storage engine.
[c] Implemented in the server, rather than in the storage engine.
ARCHIVE存儲引擎包含MySQL binary發布中。如果是源代碼安裝,為了啟動ARCHIVE存儲引擎,可以使用CMake –DWITH_ARCHIVE_STORAGE_ENGINE選項。
可以在storage/archive查看ARCHIVE源代碼。
當創建一個ARCHIVE表,服務創建一個表的定義在數據庫目錄。文件名為表名.frm。存儲引擎創建其他文件,所有的都是以表名開頭。數據文件的擴展名是ARZ,ARN文件會在優化操作的時候會出現。
ARCHIVE存儲引擎,包括insert,select,但是沒有delete,replace,update操作。使用order by排序,BLOB字段和其他所有基礎類型但是不能排序spatial數據類型。
ARCHIVE存儲引擎自持AUTO_INCREMENT類型屬性。自增類型可以是唯一或者不唯一的索引。
試圖在其他字段上創建創建索引都會報錯。ARCHIVE存儲引擎也支持對自增字段在創建表的時候設置初始化值。或者reset已經有的自增字段。
ARCHIVE不支持插入到自增字段小於當前字段最大值。如果嘗試,就報鍵重復錯誤。
如果不需要BLOB字段在讀取的時候會被忽略掉。
存儲:行被壓縮插入,ARCHIVE存儲引擎使用zlib無損壓縮方式。你可以使用OPTIMIZE TABLE來分析白哦並且打包到更小的格式。存儲引擎也支持CHECK TABLE 。有一些被使用的類型:
1.INSERT語句只是把行存到壓縮buffer中,buffer根據需要被刷新。Insert到buffer被鎖保護。Select會強制buffer刷新。
2.bulk insert只有在完成後才可見,除非其他插入同時發生,可以部分可見。Select不會導致bulk insert刷新,除非正常的插入也同時發生。
獲取:為了獲取,行被解壓。沒有行cache。Select操作在壓縮表上掃描:當select發生,查找有多上行會被讀取。Select執行讀一致性操作。大量在插入的時候有select語句會惡化,除非只有bulk或者延遲插入被使用。為了歸檔更好的壓縮,你可以使用OPTIMIZE TABLE或者REPAIR TABLE。Show table status可以查看archive表的行數。
BLACKHOLE存儲引擎就是black hole,接受數據,但是不保存。獲取總是為空。
mysql> CREATE TABLE test(i INT, c CHAR(10)) ENGINE = BLACKHOLE;
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO test VALUES(1,'record one'),(2,'record two');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM test;
Empty set (0.00 sec)
如果要使用BLACKHOLE存儲引擎,在編譯源代碼的時候,調用CMAKE –DWITH_BLACKHOLE_STORAGE_ENGINE。參數。
為了檢查BLACKHOLE的源代碼,可以在sql目錄先查看發布的源代碼。
當你創建BLACKHOLE表,服務創建一個表類型文件。表名.frm沒有其他的文件。
BLACKHOLE存儲引擎支持所有類型的索引。你可以在表定義的時候包含索引定義。
你可以使用show engine查看BLACKHOLE存儲引擎是否可用。
插入到BLACKHOLE表,不保存任何數據,但是binlog會生成,SQL語句會被發送到slave上。
假設你的程序需要slave段的過濾,如果傳輸所有bin log數據傳輸量太大。這個時候可以使用假的master host,默認存儲引擎是BLACKHOLE,描述如下:
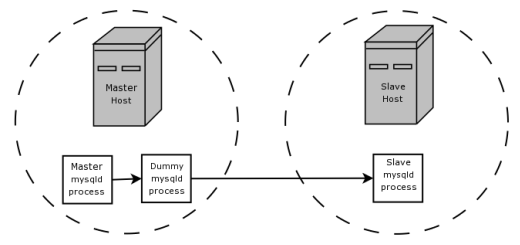
Master寫入bin log。假的mysqld進程就是slave,使用根據replicae-do-*,replicate-ignore-*規則寫入一個新的過濾的binary log。被過濾的binary log提供給slave。
假進程並不提供任何數據存儲,所以進程負荷幾乎沒有。
BLACKHOLE的INSERT觸發器是一個例外,因為BLACKHOLE不保存任何數據,UPDATE和DELETE觸發器沒有被激活:FOR EACH ROW定義不會起作用因為沒有數據。
其他可能使用BLACKHOLE的場景:
1.驗證dump文件格式。
2.測量binary log 的負荷,通過使用BLACKHOLE不啟動binary log的進行比較。
3.BLACKHOLE本質是no-op存儲引擎,所以可以用來查找和存儲引擎無關的性能問題。
BLACKHOLE存儲引擎是事務的,提交事務被雪茹到binary log並且rollback並不會寫入。
Blackhole存儲引擎和自增字段
Blackhole是no-op引擎。任何表上的操作都沒有響應。引擎並不會自動增加自增字段的值,也不會保留自增字段的狀態。
考慮一下復制場景:
1.在master上,有一個blackhole表有一個自增字段並且是主鍵。
2.slave上有個一樣表名的myisam表
3.插入操作執行沒有顯示的分配自增值。
在這個場景下復制就會報錯,重復鍵錯誤。
基於語句的復制,自增值在context事件都是一樣的。復制會因此報錯。基於行的復制,每次插入的值都是一樣的。也會報重復鍵錯誤。
列過濾
當使用基於行的binlog,slave少了最後一列是被支持的。具體可以看:
Section 17.4.1.10, “Replication with Differing Table Definitions on Master and Slave”.
過濾工作在slave段,列在過濾之前就被復制到slave。至少有2種情況需要過濾:
1.數據機密,所以slave不能訪問。
2.master有很多slave,在發送前過濾可以減少網絡負荷。
Master列過濾可以使用BLACKHOLE存儲引擎。和master表的過濾類似,使用BLACKHOLE引擎和—replicate-do-table或者—replicate-ignore-table。
Master的部署:
CREATE TABLE t1 (public_col_1, ..., public_col_N,
secret_col_1, ..., secret_col_M) ENGINE=MyISAM;
信任slave部署:
CREATE TABLE t1 (public_col_1, ..., public_col_N) ENGINE=BLACKHOLE;
不信任slave部署:
CREATE TABLE t1 (public_col_1, ..., public_col_N) ENGINE=MyISAM;
MERGE存儲引擎也就是MRG_MyISAM存儲引擎,可以把一組一致的MyISAM表當成一個表。一致的意思是表結構和索引信息都一樣。如果列順序不同也不行。替代MERGE的方法是使用分區表,把單個表的不同分區存放在不同的文件上。分區可以讓一些操作更加高效,不會受MyISAM存儲引擎限制。
當你創建了MERGE表,MySQL創建2個文件在磁盤上。.frm和.mrg文件。
你可以使用select,delete,update,insert在MERGE表中。你必須有在MyISAM表上的select,delete,update權限。
使用DROP TABLE,只會刪除MERGE設置,並不會影響底層表。
為了創建MERGE你必須指定,UNION操作說明那些MyISAM表被使用。你可以使用INSERT_METHOD選項來控制如何插入到MERGE表。使用FIRST或者LAST來決定插入到第一個表還是最後一個表。如果沒有指定INSERT_METHOD或者指定了NO,插入MERGE不被允許操作,會報錯。
創建MERGE的例子:
mysql> CREATE TABLE t1 (
-> a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> message CHAR(20)) ENGINE=MyISAM;
mysql> CREATE TABLE t2 (
-> a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> message CHAR(20)) ENGINE=MyISAM;
mysql> INSERT INTO t1 (message) VALUES ('Testing'),('table'),('t1');
mysql> INSERT INTO t2 (message) VALUES ('Testing'),('table'),('t2');
mysql> CREATE TABLE total (
-> a INT NOT NULL AUTO_INCREMENT,
-> message CHAR(20), INDEX(a))
-> ENGINE=MERGE UNION=(t1,t2) INSERT_METHOD=LAST;
在底層MyISAM表上,指定了主鍵,但是沒有再MERGE表上,因為MERGE不能強制底層表的唯一性。
創建之後,你可以使用查詢MERGE表:
重新映射MERGE表的底層表:
1.刪除重新創建。
2.使用alter table tbl_name union=(…)來修改。也可以使用alter table tbl_name union()來刪除所有底層表。這樣表就是空的,插入就會失敗,因為沒有底層表。
低沉表定義和索引必須和MERGE一直。當表被打開的時候進行一致性檢查。如果任意表一致性檢查失敗,觸發打開表的操作就會失敗。也就是說當MERGE被訪問的時候修改MERGE內表的定義就會導致訪問失敗。一致性檢查會應用到所有表:
1.底層表和MERGE表必須列個數一樣
2.底層表和MERGE表列順序必須一樣。
3.列類型必須一致。
4.類長度必須一致
5.列可以為null
6.底層表索引個數至少和MERGE一樣多。底層表可以更多但是不能少於MERGE表。
每個索引必須滿足一下條件:
1.索引類型必須一樣。
2.index part必須一樣。
3.對於每個索引,index part一樣,類型一樣,語言一樣,檢查index part是否可以為null。
如果MERGE不能被打開或者使用因為底層表的問題,CHECK TABLE檢查什麼表的問題。
MERGE表優點:
1.簡單管理日志表,比如你可以把不同的月份的數據放在不同的表上,使用myisampacl壓縮。然後創建MERGE來使用它們。
2.獲取更快的速度。你可以根據一些關鍵點拆分大的只讀表,然後分開的多個表中,並且位於不同的磁盤。MERGE表結構可以比使用單個大表速度更快。
3.執行查詢更加高效。如果你准確的知道你要獲取什麼,你可以在底層表執行查詢,然後多其他表使用merge。在一組表上可以有很多個merge。
4.修復更加有效。修復小表比修復單個達標速度更快。
5.及時的把表映射到一個。MERGE表不需要維護所有因為索引屬於個別的表。MERGE可以快速的創建或者重新映射。
6.如果有一組表,你先要創建一個大表,現在可以使用MERGE表來代替。
7.可以超過系統限制的文件大小,因為MERGE由多個表組成。
8.你可以創建一個別名,通過映射到MERGE表
MERGE缺點:
1.只能使用MyISAM作為底層表。
2.一些MyISAM表的 特性不可用。比如不能創建全文索引。
3.如果MERGE表不是臨時的,所有低沉MyISAM表必須是非臨時的。如果MERGE表是臨時的,底層表可以是臨時的也可以不是臨時的。
4.MERGE表比MyISAM的文件描述多。如果10個客戶端使用MERGE表映射了10個MyISAM表。服務使用(10*10)+10個文件描述。
5.索引讀取很慢。當你讀取索引,MERGE存儲引擎需要在所有底層表上執行一個讀來檢查那個最匹配給定的index值。為了讀取下一個值,MERGE存儲引擎需要查詢read buffer來查找下一個值。MERGE索引在eq_ref上很慢,但是在ref上並不慢。
1.直到MySQL 5.1.23 為止都可以使用非臨時的MyISAM創建臨時MERGE表。
2.如果使用ALTER TABLE來修改MERGE到另外一個存儲引擎,底層表消失,底層表的行被復制到alter table表上,使用了指定存儲引擎。
3.INSERT_METHOD表選項表示那個MyISAM表用於MERGE的insert into。如果底層表使用了自增字段,insert into MERGE表不會有反應
4.MERGE表不能維護唯一約束。
5.因為MERGE存儲引擎不能強制唯一性約束,REPLIACE就不可能和預期的一樣運行。主要有2個方面:
a.REPLACE只有在底層表的寫入上才能發現唯一性沖突。
b.如果REPLACE發現唯一性沖突,只能改變寫入的底層表。
6.MERGE表不支持分區。
7.你不能使用ANALYZE TABLE,REPAIR TABLE,OPTIMIZE TABLE,ALTER TABLE,DROP TABLE,DELETE沒有where子句的。
8.DROP table在MERGE 表上在windows 上不起作用因為MERGE表被映射在底層表上。Windows不允許打開的文件被刪除。所以你先要flush 所有merge表。
9.當文芳表的時候會檢查MERGE和MyISAM表的定義。
10.MERGE表的索引順序要和底層表一樣。
11.如果發生錯誤比如Error 1017不能查看文件。通常表示底層表沒有使用MyISAM存儲引擎。
12.MERGE表最大的行數是2^64,就算映射的表在多也無法比這個行數多。
13.底層MyISAM表和MERGE表不同就會報錯。
14.當LOCK tables的時候,不能修改union list。
15.不能通過create select創建MERGE表。
16.在一些情況下不同的PACK_KEYS表選項會導致一些想不到的問題。
FEDERATED存儲引擎可以讓你訪問遠程數據不需要通過復制或者集群技術。查詢本地FEDERATED表自動從遠程獲取數據。本地不保存數據。
為了有FEDERATED存儲引擎,可以在編譯的時候CMake –DWITH_FEDERATED_STORAGE_ENGINE選項。
FEDERATED存儲引擎默認不啟動,可以通過-federated選項來啟動。存儲引擎源代碼在storage/federated目錄下。
當你創建表使用了標准的存儲引擎(如,MyISAM,CSV,Innodb)表由表定義和相關數據組成。當你創建FEDERATED表,表定義是一樣的,但是數據存儲是在遠程的。
FEDERATED表由以下2個要素組成:
1.遠程服務的數據庫表,包含了表定義,和相關數據。
2.本地服務的表,表定義和遠程服務的要一樣。表定義保存在frm文件,但是沒有數據文件,只是有一個連接字符串指向遠程表。
當在FEDERATED表執行查詢和語句,草錯可以正常執行,insert,update,delete都會被發送到遠程去執行,或者從遠程返回行。
FEDERATED結構如下:
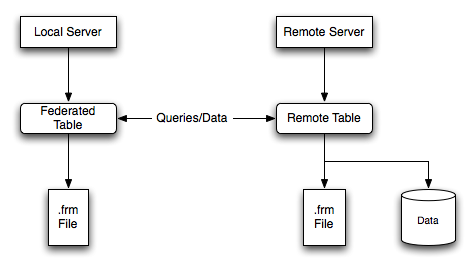
當客戶端執行SQL語句引用了FEDERATED表,客戶端和服務間的信息流如下:
1.存儲引擎查看,FEDERATED表相關的每個列,構建合適的SQL發送到遠程表。
2.語句通過MySQL Client API發送到遠程
3.遠程服務處理語句並且本地服務獲取語句處理的結果。
4.如果語句生成的結果,每個列都被轉化為FEDERATED要的內部存儲過程格式。並且結果發送到語句發生的最初地方。
本地服務和遠程服務通過MySQL Client API交互使用mysql_real_query()發送語句,mysql_store_result()來獲取結果,使用mysql_fetch_row()一次獲取一行。
你可以使用以下步驟創建FEDERATED表:
1.在遠程服務商創建表,如果表已經存在,使用show create table獲取語句。
2.在本地創建表定義,添加鏈接信息到遠程。
創建本地表關聯到遠程,有2個可用的選項。要不創建一個本地表並且制定連接字符串,或者使用已經存在的連接,通過create server創建的連接。
使用第一種方法創建,你必須指定CONNECTION選項,例如:
CREATE TABLE federated_table (
id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
INDEX name (name),
INDEX other_key (other)
)
ENGINE=FEDERATED
DEFAULT CHARSET=latin1
CONNECTION='mysql://fed_user@remote_host:9306/federated/test_table';
CONNECTION字符串包含了連接到遠程服務的信息包括存儲數據的物理表。連接支付穿指定了服務名,登錄憑據,端口,數據庫/表名。格式如下:
scheme://user_name[:password]@host_name[:port_num]/db_name/tbl_name
schema:表示可以識別的協議,mysql是唯一支持的協議。
User_name:連接的用戶名,用戶名必須在remote上被創建,並且有正確的權限。
Password:可選用戶名對應的密碼
Host_name:遠程服務的主機名或者ip地址
Port_num:可選,遠程服務的端口
Db_name:數據庫名
Tbl_name:遠程的表名。
如:
CONNECTION='mysql://username:password@hostname:port/database/tablename'
CONNECTION='mysql://username@hostname/database/tablename'
CONNECTION='mysql://username:password@hostname/database/tablename'
如果你創建一批FEDERATED表,你可以先使用create server創建,如:
CREATE SERVER server_name
FOREIGN DATA WRAPPER wrapper_name
OPTIONS (option [, option] ...)
如:
CREATE SERVER fedlink
FOREIGN DATA WRAPPER mysql
OPTIONS (USER 'fed_user', HOST 'remote_host', PORT 9306, DATABASE 'federated');
創建FEDERATED表的使用,如下:
CREATE TABLE test_table (
id INT(20) NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL DEFAULT '',
other INT(20) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
INDEX name (name),
INDEX other_key (other)
)
ENGINE=FEDERATED
DEFAULT CHARSET=latin1
CONNECTION='fedlink/test_table';
這個CONNECTION中包含了fedlink就是之前創建的server。
Description
CONNECTION string
CREATE SERVER option
mysql.servers column
Connection scheme
scheme
wrapper_name
Wrapper
Remote user
user_name
USER
Username
Remote password
password
PASSWORD
Password
Remote host
host_name
HOST
Host
Remote port
port_num
PORT
Port
Remote database
db_name
DATABASE
Db
在使用FEDERATED的時候要注意:
1.FEDERATED表可能被復制到其他slave,但是你必須保證slave服務的可以使用用戶密碼訪問遠程服務,根據connection的定義。
後面是FEDERATED表支持的或不支持的特性:
1.遠程服務必須是MySQL
2.遠程表在訪問前必須存在
3.很有可能一個FEDERATED表指向到另外一個FEDERATED表,但是注意不能創建出一個循環。
4.通常意義上FEDERATED表不支持索引,因為訪問表數據是在遠程被處理的,司機遠程表是使用索引的。也就是說一個查詢不能使用任何索引並且要表掃描,服務從遠程獲取所有記錄並且過濾。不管使用了任何where,limit子句,這些子句都是在本地被使用的。
如果使用索引失敗,或導致性能問題和網絡負荷問題。另外會導致內存短缺。
5.注意當創建FEDERATED表因為和其他表一樣的索引定義可能不被支持。比如在varchar,text,blob上創建前綴索引就會失敗。
如:
CREATE TABLE `T1`(`A`
VARCHAR(100),UNIQUE KEY(`A`(30))) ENGINE=FEDERATED
CONNECTION='MYSQL://127.0.0.1:3306/TEST/T1';
6.內部實現, select,insert,update,但是沒有實現handle
7.FEDERATED存儲引擎支持,select,insert,update,delete,truncate table和索引。但是不支持alter table或者任何其他DDL語句除了drop table。
8.FEDERATED使用insert … on duplicate key update語句,但是如果出現重復鍵錯誤,語句錯誤。
9.FEDERATED表在bulk insert的時候比其他表類型要慢,因為每個查詢行都被分為獨立的insert,insert到FEDERATED。
10.不支持事務。
11.FEDERATED執行bulk-insert處理多行被批量發送到遠程表,性能得到提高並且遠程的執行性能提高。如果遠程是事務的,可以讓遠程引擎在錯誤發生的時候回滾:
a.行的大小不能超過服務器間的包大小,如果超過,就會被分為多個包。並且回滾就會出錯。
b.bulk insert不支持insert
… on duplicate key update。
12.FEDERATED無法知道遠程表是不是被修改。因為文件必須和數據文件一樣運行不能被其他服務寫入。如果任何修改遠程數據庫本地表的一致性就可能會被破壞。
13.當使用CONNECTION連接的時候,不能在密碼中使用@。但是在create server中可以使用。
14.insert_id和timestamp不能傳播到data provider上。
15.任何drop table語句在FEDERATED表上只會刪除本地表,不會刪除遠程表。
16.FEDERATED表不能使用query cache。
17.FEDERATED不支持用戶定義分區。
其他的資源: http://forums.mysql.com/list.php?105.
EXAMPLE存儲引擎是為了給開發存儲引擎的使用的例子,略。
具體看:http://dev.mysql.com/doc/refman/5.7/en/storage-engines-other.html
MySQL插件式存儲引擎體系結構,可以讓數據庫根據不同的程序選擇不同的存儲引擎。MySQL服務體系結構隔離了應用程序和DBA對底層存儲的實現細節,提供一致的簡單的程序模型和API。因此盡管不同的存儲引擎能力不同,這些不同對應用程序不可見。
插件式存儲引擎結構提供了標准的服務管理和支持。存儲引擎自己是數據庫服務的組件實現了數據庫底層的數據保存。
有效的和模塊化的體系結構提供了大量的好處,可以為程序定制不同的存儲。比如數據長褲,事務處理和高可用。
MySQL服務使用插入是存儲引擎結構體系可以讓存儲引擎加載和卸載。
加載存儲引擎:
在存儲引擎被使用前,存儲引擎的共享library必須被加載到MySQL,使用INSTALL PLUGIN語句。比如:example存儲引擎plugin稱為example,shard library是ha_example。so.
mysql> INSTALL PLUGIN example SONAME 'ha_example.so';
為了能夠加載存儲引擎,插件文件的路徑必須在MySQL plugin目錄,並且執行INSTALL PLUGIN用戶要有對mysql.plugin表有插入權限。
Shared library目錄可以查看plugin_dir。
卸載存儲引擎
為了卸載存儲引擎可以使用UNINSTALL PLUGIN語句:
mysql> UNINSTALL PLUGIN example;
如果被卸載的存儲引擎已經有表存在,那麼這些表就不能被訪問了,但是依然存在在磁盤上。保證在卸載之前已經沒有表使用這個存儲過程了。