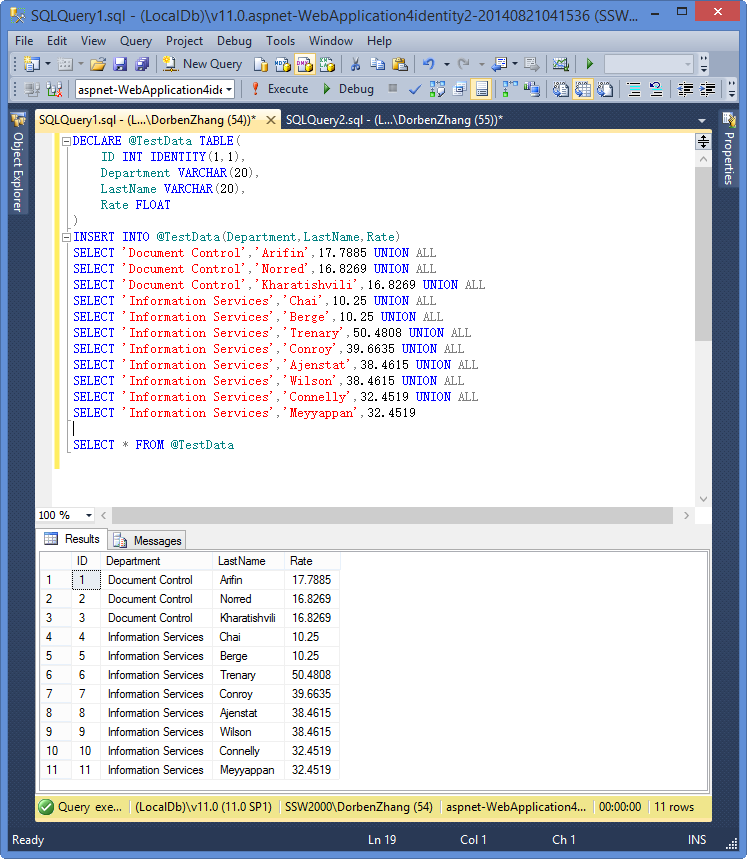
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
注意: 1. RANGE分區的返回值必須為整數。 2. PARTITION p3 VALUES LESS THAN MAXVALUE 是非必需的。 RANGE COLUMNS分區 RANGE COLUMNS是RANGE分區的一種特殊類型,它與RANGE分區的區別如下: 1. RANGE COLUMNS不接受表達式,只能是列名。而RANGE分區則要求分區的對象是整數。 2. RANGE COLUMNS允許多個列,在底層實現上,它比較的是元祖(多個列值組成的列表),而RANGE比較的是標量,即數值的大小。 3. RANGE COLUMNS不限於整數對象,date,datetime,string都可作為分區列。 格式如下:
CREATE TABLE rcx (
a INT,
b INT,
c CHAR(3),
d INT
)
PARTITION BY RANGE COLUMNS(a,d,c) (
PARTITION p0 VALUES LESS THAN (5,10,'ggg'),
PARTITION p1 VALUES LESS THAN (10,20,'mmmm'),
PARTITION p2 VALUES LESS THAN (15,30,'sss'),
PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE,MAXVALUE)
);
同RANGE分區類似,它的區間范圍必須是遞增的,有時候,列涉及的太多,不好判斷區間的大小,可采用下面的方式進行判斷: mysql> SELECT (5,10) < (5,12), (5,11) < (5,12), (5,12) < (5,12); +-----------------+-----------------+-----------------+ | (5,10) < (5,12) | (5,11) < (5,12) | (5,12) < (5,12) | +-----------------+-----------------+-----------------+ | 1 | 1 | 0 | +-----------------+-----------------+-----------------+ 1 row in set (0.07 sec) LIST分區 LIST即列表分區。 格式如下:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LIST(store_id) (
PARTITION pNorth VALUES IN (3,5,6,9,17),
PARTITION pEast VALUES IN (1,2,10,11,19,20),
PARTITION pWest VALUES IN (4,12,13,14,18),
PARTITION pCentral VALUES IN (7,8,15,16)
);
LIST COLUMNS分區 LIST COLUMNS分區同樣是LIST分區的一種特殊類型,它和RANGE COLUMNS分區較為相似,同樣不接受表達式,同樣支持多個列支持string,date和datetime類型。 格式如下:
CREATE TABLE customers_1 (
first_name VARCHAR(25),
last_name VARCHAR(25),
street_1 VARCHAR(30),
street_2 VARCHAR(30),
city VARCHAR(15),
renewal DATE
)
PARTITION BY LIST COLUMNS(renewal) (
PARTITION pWeek_1 VALUES IN('2010-02-01', '2010-02-02', '2010-02-03',
'2010-02-04', '2010-02-05', '2010-02-06', '2010-02-07'),
PARTITION pWeek_2 VALUES IN('2010-02-08', '2010-02-09', '2010-02-10',
'2010-02-11', '2010-02-12', '2010-02-13', '2010-02-14'),
PARTITION pWeek_3 VALUES IN('2010-02-15', '2010-02-16', '2010-02-17',
'2010-02-18', '2010-02-19', '2010-02-20', '2010-02-21'),
PARTITION pWeek_4 VALUES IN('2010-02-22', '2010-02-23', '2010-02-24',
'2010-02-25', '2010-02-26', '2010-02-27', '2010-02-28')
);
多列格式如下:
CREATE TABLE customers_2 (
first_name VARCHAR(25),
last_name VARCHAR(25),
street_1 VARCHAR(30),
street_2 VARCHAR(30),
city VARCHAR(15),
renewal DATE
)
PARTITION BY LIST COLUMNS(city,last_name,first_name) (
PARTITION pRegion_1 VALUES IN (('Oskarshamn', 'Högsby', 'Mönsterås'),('Nässjö', 'Eksjö', 'Vetlanda')),
PARTITION pRegion_2 VALUES IN(('Vimmerby', 'Hultsfred', 'Västervik'),('Uppvidinge', 'Alvesta', 'Växjo'))
);
HASH分區 和RANGE,LIST分區不同的是,HASH分區無需定義分區的條件。只需要指明分區數即可。 格式如下:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY HASH(store_id)
PARTITIONS 4;
注意: 1. HASH分區可以不用指定PARTITIONS子句,如上文中的PARTITIONS 4,則默認分區數為1。 2. 不允許只寫PARTITIONS,而不指定分區數。 3. 同RANGE分區和LIST分區一樣,PARTITION BY HASH (expr)子句中的expr返回的必須是整數值。 4. HASH分區的底層實現其實是基於MOD函數。譬如,對於下表 CREATE TABLE t1 (col1 INT, col2 CHAR(5), col3 DATE) PARTITION BY HASH( YEAR(col3) ) PARTITIONS 4; 如果你要插入一個col3為“2005-09-15”的記錄,則分區的選擇是根據以下值決定的: MOD(YEAR('2005-09-01'),4) = MOD(2005,4) = 1 LINEAR HASH分區 LINEAR HASH分區是HASH分區的一種特殊類型,與HASH分區是基於MOD函數不同的是,它基於的是另外一種算法。 格式如下:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LINEAR HASH( YEAR(hired) )
PARTITIONS 4;
說明: 1. 它的優點是在數據量大的場景,譬如TB級,增加、刪除、合並和拆分分區會更快,缺點是,相對於HASH分區,它數據分布不均勻的概率更大。 2. 具體算法,可參考MySQL的官方文檔 KEY分區 KEY分區其實跟HASH分區差不多,不同點如下: 1. KEY分區允許多列,而HASH分區只允許一列。 2. 如果在有主鍵或者唯一鍵的情況下,key中分區列可不指定,默認為主鍵或者唯一鍵,如果沒有,則必須顯性指定列。 3. KEY分區對象必須為列,而不能是基於列的表達式。 4. KEY分區和HASH分區的算法不一樣,PARTITION BY HASH (expr),MOD取值的對象是expr返回的值,而PARTITION BY KEY (column_list),基於的是列的MD5值。 格式如下:
CREATE TABLE k1 (
id INT NOT NULL PRIMARY KEY,
name VARCHAR(20)
)
PARTITION BY KEY()
PARTITIONS 2;
在沒有主鍵或者唯一鍵的情況下,格式如下:
CREATE TABLE tm1 (
s1 CHAR(32)
)
PARTITION BY KEY(s1)
PARTITIONS 10;
LINEAR KEY分區 同LINEAR HASH分區類似。 格式如下:
CREATE TABLE tk (
col1 INT NOT NULL,
col2 CHAR(5),
col3 DATE
)
PARTITION BY LINEAR KEY (col1)
PARTITIONS 3;
總結:
1. MySQL分區中如果存在主鍵或唯一鍵,則分區列必須包含在其中。
2. 對於原生的RANGE分區,LIST分區,HASH分區,分區對象返回的只能是整數值。
3. RANGE COLUMNS,LIST COLUMNS,KEY,LINEAR KEY分區對象只能是列,不能是基於列的表達式。