Mysql查詢緩存
與朋友或同事談到mysql查詢緩存功能的時候,個人喜歡把Query Cache比作荔枝, 是非常營養的東西,但是一次性吃太多了,就容易導致上火而流鼻血,雖然不是特別恰當的比喻,但是有很多相似的地方,另外Query Cache有其特殊的業務場景,也不像其他數據庫產品,緩存查詢語句的執行計劃等信息,而是直接緩存查詢語句的記錄集和對應的SQL語句。本文就給大家介 紹下查詢緩存的相關知識,希望可以引導大家正確地使用Query Cache這個獨門武器。
對mysql查詢緩存從五個角度進行詳細的分析:Query Cache的工作原理、如何配置、如何維護、如何判斷查詢緩存的性能、適合的業務場景分析。
工作原理
查詢緩存的工作原理,基本上可以用二句話概括:
緩存SELECT操作或預處理查詢(注釋:5.1.17開始支持)的結果集和SQL語句;
新的SELECT語句或預處理查詢語句,先去查詢緩存,判斷是否存在可用的記錄集,判斷標准:與緩存的SQL語句,是否完全一樣,區分大小寫;
查詢緩存對什麼樣的查詢語句,無法緩存其記錄集,大致有以下幾類:
查詢語句中加了SQL_NO_CACHE參數;
查詢語句中含有獲得值的函數,包涵自定義函數,如:CURDATE()、GET_LOCK()、RAND()、CONVERT_TZ等;
對系統數據庫的查詢:mysql、information_schema
查詢語句中使用SESSION級別變量或存儲過程中的局部變量;
查詢語句中使用了LOCK IN SHARE MODE、FOR UPDATE的語句
查詢語句中類似SELECT …INTO 導出數據的語句;
事務隔離級別為:Serializable情況下,所有查詢語句都不能緩存;
對臨時表的查詢操作;
存在警告信息的查詢語句;
不涉及任何表或視圖的查詢語句;
某用戶只有列級別權限的查詢語句;
查詢緩存的優缺點:
不需要對SQL語句做任何解析和執行,當然語法解析必須通過在先,直接從Query Cache中獲得查詢結果;
查詢緩存的判斷規則,不夠智能,也即提高了查詢緩存的使用門檻,降低其效率;
Query Cache的起用,會增加檢查和清理Query Cache中記錄集的開銷,而且存在SQL語句緩存的表,每一張表都只有一個對應的全局鎖;
配置
是否啟用mysql查詢緩存,可以通過2個參數:query_cache_type和query_cache_size,其中任何一個參數設置為0都意味著關閉查詢緩存功能,但是正確的設置推薦query_cache_type=0。
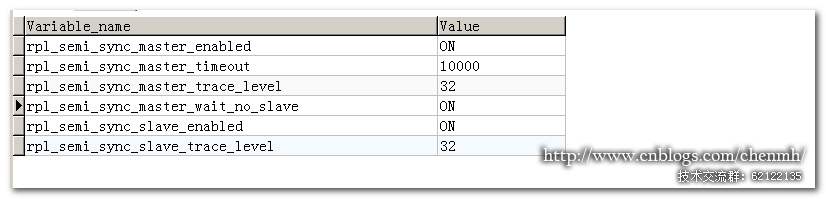
query_cache_type
值域為:0 -– 不啟用查詢緩存;
值域為:1 -– 啟用查詢緩存,只要符合查詢緩存的要求,客戶端的查詢語句和記錄集斗可以緩存起來,共其他客戶端使用;
值域為:2 -– 啟用查詢緩存,只要查詢語句中添加了參數:sql_cache,且符合查詢緩存的要求,客戶端的查詢語句和記錄集,則可以緩存起來,共其他客戶端使用;
query_cache_size
允許設置query_cache_size的值最小為40K,對於最大值則可以幾乎認為無限制,實際生產環境的應用經驗告訴我們,該值並不是越大, 查詢緩存的命中率就越高,也不是對服務器負載下降貢獻大,反而可能抵消其帶來的好處,甚至增加服務器的負載,至於該如何設置,下面的章節講述,推薦設置 為:64M;
query_cache_limit
限制查詢緩存區最大能緩存的查詢記錄集,可以避免一個大的查詢記錄集占去大量的內存區域,而且往往小查詢記錄集是最有效的緩存記錄集,默認設置為1M,建議修改為16k~1024k之間的值域,不過最重要的是根據自己應用的實際情況進行分析、預估來設置;
query_cache_min_res_unit
設置查詢緩存分配內存的最小單位,要適當地設置此參數,可以做到為減少內存塊的申請和分配次數,但是設置過大可能導致內存碎片數值上升。默認值為4K,建議設置為1k~16K
query_cache_wlock_invalidate
該參數主要涉及MyISAM引擎,若一個客戶端對某表加了寫鎖,其他客戶端發起的查詢請求,且查詢語句有對應的查詢緩存記錄,是否允許直接讀取查詢緩存的記錄集信息,還是等待寫鎖的釋放。默認設置為0,也即允許;
維護
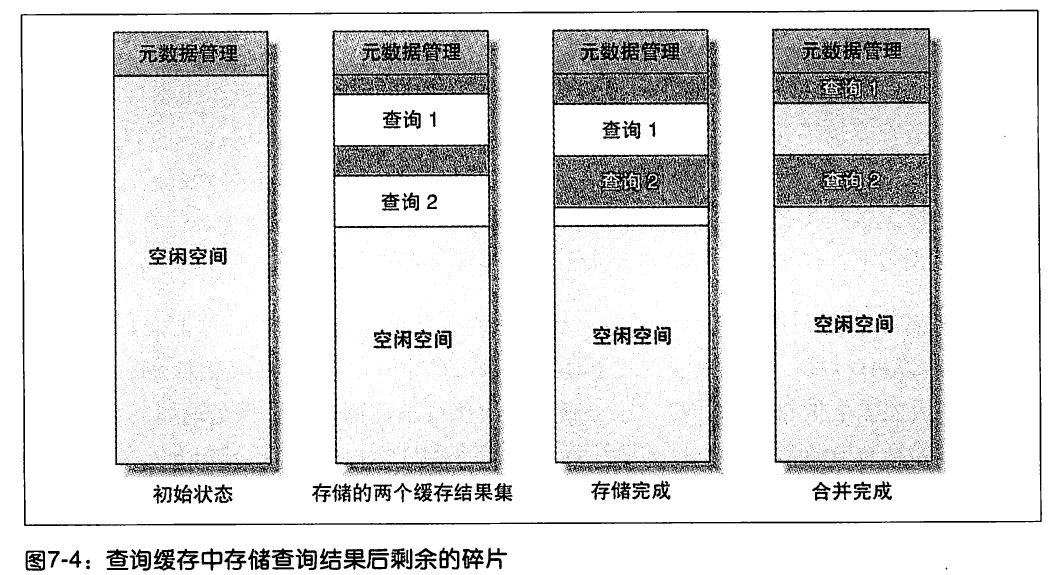
查詢緩存區的碎片整理
查詢緩存使用一段時間之後,一般都會出現內存碎片,為此需要監控相關狀態值,並且定期進行內存碎片的整理,碎片整理的操作語句:FLUSH QUERY CACHE;
清空查詢緩存的數據
那些操作操作可能觸發查詢緩存,把所有緩存的信息清空,以避免觸發或需要的時候,知道如何做,二類可觸發查詢緩存數據全部清空的命令:
(1). RESET QUERY CACHE;
(2). FLUSH TABLES;
性能監控
碎片率
查詢緩存內存碎片率=Qcache_free_blocks / Qcache_total_blocks * 100%
命中率
查詢緩存命中率=(Qcache_hits – Qcache_inserts) / Qcache_hits * 100%
內存使用率
查詢緩存內存使用率=(query_cache_size – Qcache_free_memory) / query_cache_size * 100%
Qcache_lowmem_prunes
該參數值對於檢測查詢緩存區的內存大小設置是否,有非常關鍵性的作用,其代表的意義為:查詢緩存去因內存不足而不得不從查詢緩存區刪除的查詢緩存信息,刪除算法為LRU;
query_cache_min_res_unit
內存塊分配的最小單元非常重要,設置過大可能增加內存碎片的概率發生,太小又可能增加內存分配的消耗,為此在系統平穩運行一個階段性後,可參考公式的計算值:
查詢緩存最小內存塊 = (query_cache_size – Qcache_free_memory) / Qcache_queries_in_cache
query_cache_size
我們如何判斷query_cache_size是否設置過小,依然也只有先預設置一個值,推薦為:32M~128M之間的區域,待系統平穩運行一個時間段(至少1周),並且觀察這周內的相關狀態值:
(1). Qcache_lowmem_prunes;
(2). 命中率;
(3). 內存使用率;
若整個平穩運行期監控獲得的信息,為命中率高於80%,內存使用率超過80%,並且Qcache_lowmem_prunes的值不停地增加,而且增加的數值還較大,則說明我們為查詢緩沖區分配的內存過小,可以適當地增加查詢緩存區的內存大小;
若是整個平穩運行期監控獲得的信息,為命中率低於40%,Qcache_lowmem_prunes的值也保持一個平穩狀態,則說明我們的查詢緩沖區的內 存設置過大,或者說業務場景重復執行一樣查詢語句的概率低,同時若還監測到一定量的freeing items,那麼必須考慮把查詢緩存的內存條小,甚至關閉查詢緩存功能;
業務場景
通過上述的知識梳理和分析,我們至少知道查詢緩存的以下幾點:
查詢緩存能夠加速已經存在緩存的查詢語句的速度,可以不用重新解析和執行而獲得正確得記錄集;
查詢緩存中涉及的表,每一個表對象都有一個屬於自己的全局性質的鎖;
表若是做DDL、FLUSH TABLES 等類似操作,觸發相關表的查詢緩存信息清空;
表對象的DML操作,必須優先判斷是否需要清理相關查詢緩存的記錄信息,將不可避免地出現鎖等待事件;
查詢緩存的內存分配問題,不可避免地產生一些內存碎片;
查詢緩存對是否是一樣的查詢語句,要求非常苛刻,而且還不智能;
我們再重新回到本節的重點上,查詢緩存適合什麼樣的業務場景呢?只要是清楚了查詢緩存的上述優缺點,就不難羅列出來,業務場景要求:
整個系統以讀為主的業務,比如門戶型、新聞類、報表型、論壇等網站;
查詢語句操作的表對象,非頻繁地進行DML操作,可以使用query_cache_type=2模式,然後SQL語句加SQL_CACHE參數指定;