後端分布式系列:分布式存儲-MySQL 數據庫雙向同步復制
MySQL 復制問題的最後一篇,關於雙向同步復制架構設計的一些設計要點與制約。
問題和制約
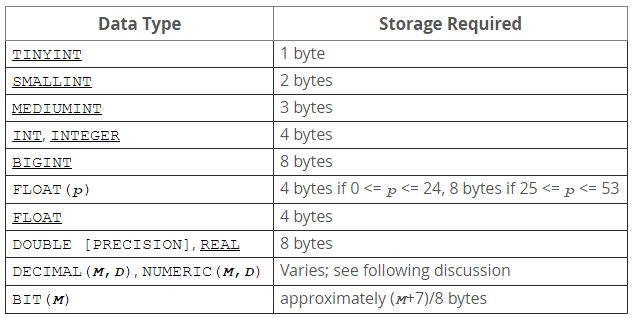
數據庫的雙主雙寫並雙向同步場景,主要考慮數據完整性、一致性和避免沖突。對於同一個庫,同一張表,同一個記錄中的同一字段的兩地變更,會引發數據一致性判斷沖突,盡可能通過業務場景設計規避。雙主雙寫並同步復制可能引發主鍵沖突,需避免使用數據庫自增類主鍵方案。另外,雙向同步潛在可能引發循環同步的問題,需要做回環控制。
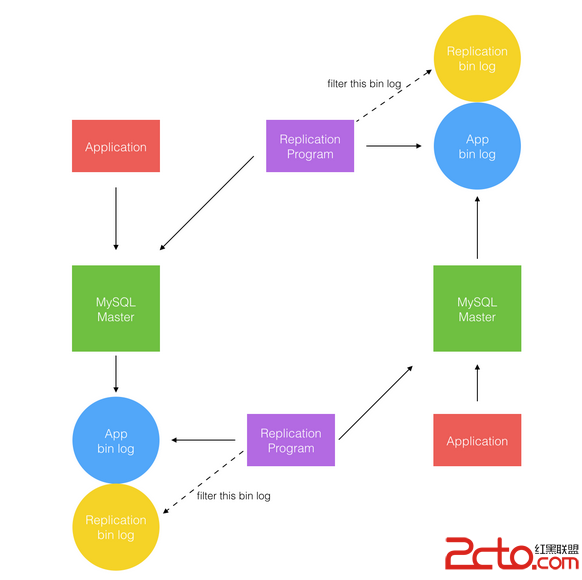
如上圖所示,復制程序寫入時也會產生 binlog,如何識別由復制程序產生的 binlog 並將其過濾掉是避免循環復制的關鍵。
原生 Dual Master 方案
MySQL 自身支持雙主配置,但並沒有去解決潛在的主鍵和雙寫帶來的數據一致性沖突。對於雙向同步潛在的循環復制問題,MySQL 在 binlog 中記錄了當前 MySQL 的 server-id。一旦有了 server-id 的值之後,MySQL 就很容易判斷某個變更是從哪一個 Server 最初產生的,所以就很容易避免出現循環復制的情況。而且,還可以配置不打開記錄 slave 的 binlog 選項(--log-slave-update),MySQL 就不會記錄復制過程中的變更到 binlog 中,就更不用擔心可能會出現循環復制的情形了。
從 MySQL 自身的方案中可以找到切入點,就是如果能在 binlog 中打上標記,就有辦法判斷哪些 binlog 是復制產生的,並將其過濾。使用 MySQL 的方案則過於耦合 MySQL 的配置,在大規模部署的線上生產系統中容易因為 MySQL 配置錯誤導致問題。
自定義標記 SQL 方案
為了和 MySQL 配置解耦合,可以考慮一種通用的標記 SQL 方案。簡單來說,就是在同步復制入庫時插入特殊的標記 SQL 語句來標記這是來自復制程序的變更,這個標記 SQL 會進入 binlog 中。而在復制程序讀取時,通過識別這個標記 SQL 來過濾判斷。
binlog 中存儲了對數據產生變更影響的的 SQL 語句,這些 SQL 語句組成了一段一段的事務,如下圖所示:
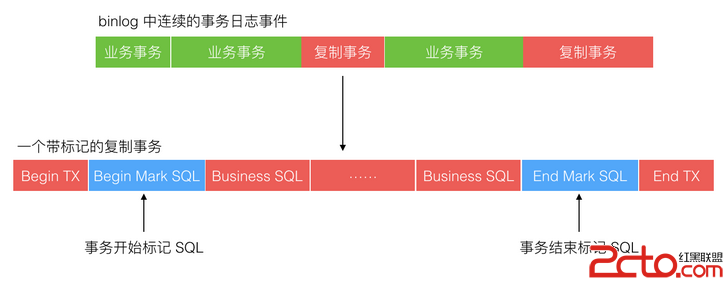
綠色區是業務運行產生的正常事務,紅色區是復制程序寫入產生的事務,其中藍色塊是標記 SQL。標記 SQL 分別在事務開始後與事務結束前,標記 SQL 更新一張預定義的區別於業務表的標記表。那麼每次復制程序去批量讀取 binlog 內容時,可能存在下面 5 種情況,如下圖所示:
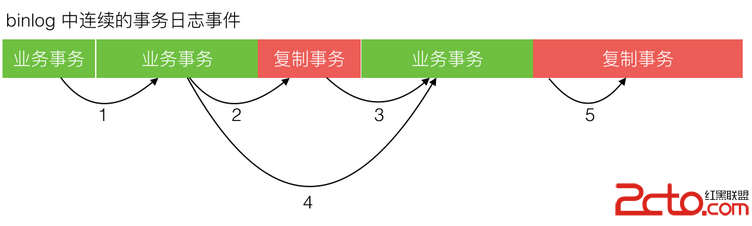
批量讀取范圍全落在綠色區內。
批量讀取范圍起點落在綠色區,終點落在紅色區。
批量讀取范圍起點落在紅色區,終點落在綠色區。
批量讀取范圍起點和終點都在綠色區,但中間涵蓋了一段紅色區。
批量讀取范圍全落在紅色區。
如上只有第 5 種情況,一個事務被拆成 3 段來同步。中間一段因為沒有事務頭和尾的標記,復制程序讀取時將無法判斷,導致循環同步,需要避免。通過把復制程序的批量讀取范圍固定設置為至少大於或等於寫入的事務長度范圍,避免了第 5 種情況。復制程序批量讀取 binlog 日志事件時,通過標記 SQL 來過濾,避免了循環復制,實現了回環控制。
總結
本文考慮了在 MySQL 雙主寫入場景下雙向同步復制的一些設計要點和制約。以原生實現為參考,給出了一種自定義實現方式的設計要點分析。而對於同庫同表同記錄同字段的同時兩地變更,則必然引發數據一致性沖突,在復制同步層面無法區分哪邊的更新為准。通常會考慮以最後時間戳來恢復到一致狀態,但時間戳實際也會產生誤差,此類場景不多見最好還是盡可能還是在業務場景設計上來規避。