寫在前面的話
查詢容易,優化不易,且寫且珍惜
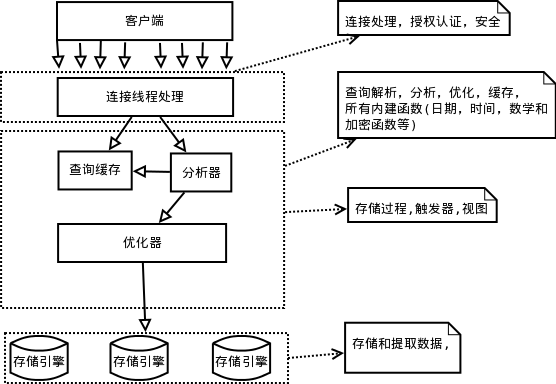
從MySQL邏輯架構來看,MySQL有三層架構,第一層連接,第二層查詢解析、分析、優化、視圖、緩存,第三層,存儲引擎
從數據結構角度
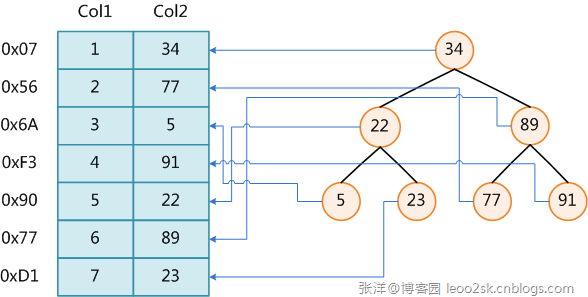
1、B+樹索引(O(log(n))):關於B+樹索引,可以參考 MySQL索引背後的數據結構及算法原理
2、hash索引:
a 僅僅能滿足"=","IN"和"<=>"查詢,不能使用范圍查詢
b 其檢索效率非常高,索引的檢索可以一次定位,不像B-Tree 索引需要從根節點到枝節點,最後才能訪問到頁節點這樣多次的IO訪問,所以 Hash 索引的查詢效率要遠高於 B-Tree 索引
c 只有Memory存儲引擎顯示支持hash索引
3、FULLTEXT索引(現在MyISAM和InnoDB引擎都支持了)
4、R-Tree索引(用於對GIS數據類型創建SPATIAL索引)
從物理存儲角度
1、聚集索引(clustered index)
2、非聚集索引(non-clustered index)
從邏輯角度
1、主鍵索引:主鍵索引是一種特殊的唯一索引,不允許有空值
2、普通索引或者單列索引
3、多列索引(復合索引):復合索引指多個字段上創建的索引,只有在查詢條件中使用了創建索引時的第一個字段,索引才會被使用。使用復合索引時遵循最左前綴集合
4、唯一索引或者非唯一索引
5、空間索引:空間索引是對空間數據類型的字段建立的索引,MYSQL中的空間數據類型有4種,分別是GEOMETRY、POINT、LINESTRING、POLYGON。
MYSQL使用SPATIAL關鍵字進行擴展,使得能夠用於創建正規索引類型的語法創建空間索引。創建空間索引的列,必須將其聲明為NOT NULL,空間索引只能在存儲引擎為MYISAM的表中創建
CREATE TABLE table_name[col_name data type] [unique|fulltext|spatial][index|key][index_name](col_name[length])[asc|desc] 1、unique|fulltext|spatial為可選參數,分別表示唯一索引、全文索引和空間索引; 2、index和key為同義詞,兩者作用相同,用來指定創建索引 3、col_name為需要創建索引的字段列,該列必須從數據表中該定義的多個列中選擇; 4、index_name指定索引的名稱,為可選參數,如果不指定,MYSQL默認col_name為索引值; 5、length為可選參數,表示索引的長度,只有字符串類型的字段才能指定索引長度; 6、asc或desc指定升序或降序的索引值存儲
1、基數很低的字段不創建索引,更新非常頻繁的字段不適合創建索引
2、MySQL不支持bitmap索引
3、采用第三方系統實現 Text/Blob 的全文索引(Sphinx、Coreseek、Lucene、ElashSearch)
4、常用的 where、ORDER BY 、GROUP BY 、DISTINCT 字段要建立索引
5、索引不能太多,會有負作用
6、多使用聯合索引、少使用獨立索引
7、字符型可創建前綴索引(如 username 字段 80% 的數據都小於18個字符,那麼可以創建18個字符的前綴索引
8、字段的順序對組合索引效率有至關重要的作用,過濾效果越好的字段需要更靠前
最左前綴匹配原則,非常重要的原則,mysql會一直向右匹配直到遇到范圍查詢(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)順序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引則都可以用到,a,b,d的順序可以任意調整盡量的擴展索引,不要新建索引。比如表中已經有a的索引,現在要加(a,b)的索引,那麼只需要修改原來的索引即可=和in可以亂序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意順序,mysql的查詢優化器會幫你優化成索引可以識別的形式
9、MySQL只對以下操作符才使用索引
<,<=,=,>,>=,between,like(不以通配符%或_開頭的情形)10、不要過度索引,只保持所需的索引。每個額外的索引都要占用額外的磁盤空間,並降低寫操作的性能。 在修改表的內容時,索引必須進行更新,有時可能需要重構,因此,索引越多,所花的時間越長。
1、通過索引掃描的記錄數超過30%會進行全表掃描
2、第一個索引列使用范圍查詢不能使用索引
3、內存表使用Hash進行全表掃描
4、ORDER BY 、GROUP BY Hash索引只能進行等於/不等於的檢索
5、SELECT … WHERE key1 = ? ORDER BY key2 ASC 對於key1和key2上的索引,查詢優化器會自己判斷用哪個(只能用到一個)
6、表關聯字段類型要一樣(包括長度),否則會有類型轉換
7、使用函數時不能用到索引( WHERE func(key1) = ? 不能用到)( WHERE key1 + 1 = ? 不能用到)(WHERE key1 = ? + ? 可以用到)
1、增,刪,改都需要修訂索引,索引存在額外的維護成本
2、查找翻閱索引系統需要消耗時間,索引存在額外的訪問成本
3、索引系統需要一個地方來存放,索引存在額外的空間成本
mysqlidxchx/pt-index-usage/userstat/check-unused-keys
1、mysqlidxchx工具很長時間沒有更新,但主要用來分析general log、slow.log,來判斷實例中那個索引是可以刪除,但這個工具沒有經過實戰,風險很大。
2、pt-index-usage原理來類似mysqlidxchx,執行過程中性能消耗比較嚴重,如果要在生產庫上部署,最好在凌晨業務低鋒時使用,pt-index-usage只支持slow.log格式的文件,如果要全面分析整個實例索引使用情況,需要long_query_time設置成0,才能把所以的sql記錄下來,但同時會對磁盤空間造成壓力,同時pt-index-usage對大文件分析就是件痛苦的事。當然pt-index-usage可以考慮部分表索引使用情況的確認。
3、最看好的userstat,收集信息性能優越,成本低。這個patch是google貢獻的(userstat_running),percona把它改名成userstat,默認是不開啟的,開啟是會收集客戶端、索引、表、線程信息存儲在CLIENT_STATISTICS、INDEX_STATISTICS、TABLE_STATISTICS、THREAD_STATISTICS。Userstat的bug導致的問題太嚴重,直接導致mysql crash,到目前淘寶生產環境還沒有使用。
4、Ryan Lowe的check-unused-keys腳本基於userstat,能夠比較方便輸出需要刪除的索引。
參考地址
http://www.mysqlperformanceblog.com/2012/06/30/find-unused-indexes/
http://www.mysqlperformanceblog.com/2012/12/05/quickly-finding-unused-indexes-and-estimating-their-size/
http://www.mysqlperformanceblog.com/2009/06/26/check-unused-keys-a-tool-to-interact-with-index_statistics/