mysql在架構中的演變
寫在最前:
本文主要描述在網站的不同的並發訪問量級下Mysql架構的演變
可擴展性
架構的可擴展性往往和並發是息息相關沒有並發的增長也就沒有必要做高可擴展性的架構這裡對可擴展性進行簡單介紹一下常用的擴展手段有以下兩種
Scale-up : 縱向擴展通過替換為更好的機器和資源來實現伸縮提升服務能力
Scale-out : 橫向擴展, 通過加節點機器來實現伸縮提升服務能力
對於互聯網的高並發應用來說無疑Scale out才是出路通過縱向的買更高端的機器一直是我們所避諱的問題也不是長久之計在scale out的理論下可擴展性的理想狀態是什麼
可擴展性的理想狀態
一個服務當面臨更高的並發的時候能夠通過簡單增加機器來提升服務支撐的並發度且增加機器過程中對線上服務無影響(no down time)這就是可擴展性的理想狀態
架構的演變
V1.0 簡單網站架構
一個簡單的小型網站或者應用背後的架構可以非常簡單, 數據存儲只需要一個mysql instance就能滿足數據讀取和寫入需求這裡忽略掉了數據備份的實例處於這個時間段的網站一般會把所有的信息存到一個database instance裡面。
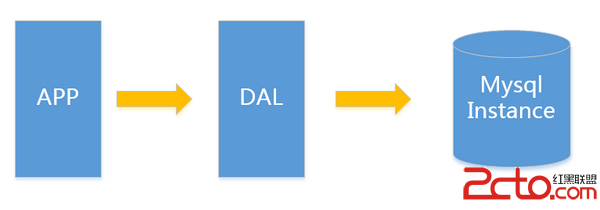
在這樣的架構下我們來看看數據存儲的瓶頸是什麼
1.數據量的總大小 一個機器放不下時
2.數據的索引B+ Tree一個機器的內存放不下時
3.訪問量(讀寫混合)一個實例不能承受
只有當以上3件事情任何一件或多件滿足時我們才需要考慮往下一級演變。 從此我們可以看出事實上對於很多小公司小應用這種架構已經足夠滿足他們的需求了初期數據量的准確評估是杜絕過度設計很重要的一環畢竟沒有人願意為不可能發生的事情而浪費自己的經歷。
這裡簡單舉個我的例子對於用戶信息這類表 3個索引16G內存能放下大概2000W行數據的索引簡單的讀和寫混合訪問量3000/s左右沒有問題你的應用場景是否
V2.0 垂直拆分
一般當V1.0 遇到瓶頸時首先最簡便的拆分方法就是垂直拆分何謂垂直就是從業務角度來看將關聯性不強的數據拆分到不同的instance上從而達到消除瓶頸的 目標。以圖中的為例將用戶信息數據和業務數據拆分到不同的三個實例上。對於重復讀類型比較多的場景我們還可以加一層cache來減少對DB的壓 力。
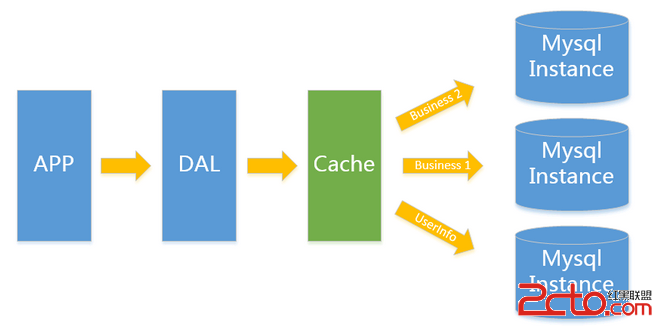
在這樣的架構下我們來看看數據存儲的瓶頸是什麼
1.單實例單業務 依然存在V1.0所述瓶頸
遇到瓶頸時可以考慮往本文更高V版本升級, 若是讀請求導致達到性能瓶頸可以考慮往V3.0升級 其他瓶頸考慮往V4.0升級
V3.0 主從架構
此類架構主要解決V2.0架構下的讀問題通過給Instance掛數據實時備份的思路來遷移讀取的壓力在Mysql的場景下就是通過主從結構主庫抗寫壓力通過從庫來分擔讀壓力對於寫少讀多的應用V3.0主從架構完全能夠勝任
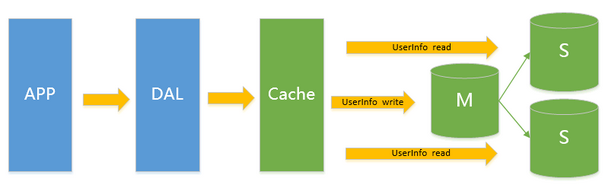
在這樣的架構下我們來看看數據存儲的瓶頸是什麼
1.寫入量主庫不能承受
V4.0 水平拆分
對於V2.0 V3.0方案遇到瓶頸時都可以通過水平拆分來解決水平拆分和垂直拆分有較大區別垂直拆分拆完的結果在一個實例上是擁有全量數據的而水平拆分之 後任何實例都只有全量的1/n的數據以下圖Userinfo的拆分為例將userinfo拆分為3個cluster每個cluster持有總量的 1/3數據3個cluster數據的總和等於一份完整數據注這裡不再叫單個實例 而是叫一個cluster 代表包含主從的一個小mysql集群
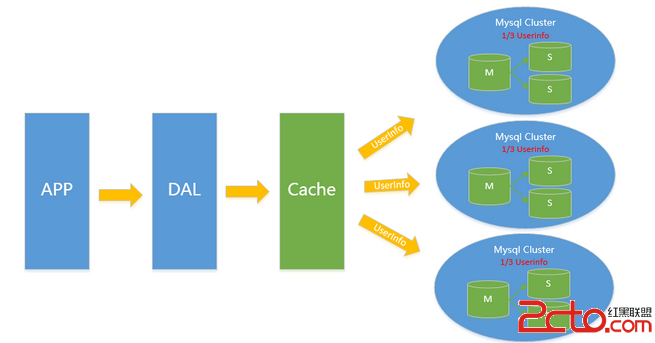
數據如何路由
1.Range拆分
sharding key按連續區間段路由一般用在有嚴格自增ID需求的場景上如Userid, Userid Range的小例子以userid 3000W 為Range進行拆分 1號cluster userid 1-3000W 2號cluster userid 3001W-6000W
2.List拆分
List拆分與Range拆分思路一樣都是通過給不同的sharding key來路由到不同的cluster,但是具體方法有些不同,List主要用來做sharding key不是連續區間的序列落到一個cluster的情況如以下場景
假定有20個音像店分布在4個有經銷權的地區如下表所示
地區
商店ID 號
北區
3, 5, 6, 9, 17
東區
1, 2, 10, 11, 19, 20
西區
4, 12, 13, 14, 18
中心區
7, 8, 15, 16
業務希望能夠把一個地區的所有數據組織到一起來搜索這種場景List拆分可以輕松搞定
3.Hash拆分
通過對sharding key 進行哈希的方式來進行拆分常用的哈希方法有除余,字符串哈希等等除余如按userid%n 的值來決定數據讀寫哪個cluster其他哈希類算法這裡就不細展開講了。
數據拆分後引入的問題
數據水平拆分引入的問題主要是只能通過sharding key來讀寫操作例如以userid為sharding key的切分例子讀userid的詳細信息時一定需要先知道userid,這樣才能推算出再哪個cluster進而進行查詢假設我需要按 username進行檢索用戶信息需要引入額外的反向索引機制類似HBASE二級索引如在redis上存儲 username->userid的映射以username查詢的例子變成了先通過查詢username->userid再通過 userid查詢相應的信息。
實際上這個做法很簡單但是我們不 要忽略了一個額外的隱患那就是數據不一致的隱患。存儲在redis裡的username->userid和存儲在mysql裡的 userid->username必須需要是一致的這個保證起來很多時候是一件比較困難的事情舉個例子來說對於修改用戶名這個場景你需要同 時修改redis和mysql,這兩個東西是很難做到事務保證的,如mysql操作成功 但是redis卻操作失敗了分布式事務引入成本較高,對於互聯網應用來說可用性是最重要的一致性是其次所以能夠容忍小量的不一致出現. 畢竟從占比來說這類的不一致的比例可以微乎其微到忽略不計一般寫更新也會采用mq來保證直到成功為止才停止重試操作
在這樣的架構下我們來看看數據存儲的瓶頸是什麼
在 這個拆分理念上搭建起來的架構理論上不存在瓶頸sharding key能確保各cluster流量相對均衡的前提下),不過確有一件惡心的事情那就是cluster擴容的時候重做數據的成本如我原來有3個 cluster但是現在我的數據增長比較快我需要6個cluster那麼我們需要將每個cluster 一拆為二一般的做法是
1.摘下一個slave,停同步,
2.對寫記錄增量log實現上可以業務方對寫操作 多一次寫持久化mq 或者mysql主創建trigger記錄寫 等等方式
3.開始對靜態slave做數據, 一拆為二
4.回放增量寫入,直到追上的所有增量,與原cluster基本保持同步
5.寫入切換由原3 cluster 切換為6cluster
有沒有類似飛機空中加油的感覺這是一個髒活累活容易出問題的活為了避免這個我們一般在最開始的時候設計足夠多的sharding cluster來防止可能的cluster擴容這件事情
V5.0 雲計算 騰飛雲數據庫
雲計算現在是各大IT公司內部作為節約成本的一個突破口對於數據存儲的 mysql來說如何讓其成為一個saasSoftware as a Service是關鍵點。在MS的官方文檔中把構建一個足夠成熟的SAAS(MS簡單列出了SAAS應用的4級成熟度)所面臨的3個主要挑戰可配置性可擴展性多用戶存儲結構設計稱為"three headed monster". 可配置性和多用戶存儲結構設計在Mysql saas這個問題中並不是特別難辦的一件事情所以這裡重點說一下可擴展性。
Mysql作為一個saas服務在架構演變為V4.0之後依賴良好的sharding key設計, 已經不再存在擴展性問題只是他在面對擴容縮容時有一些髒活需要干而作為saas,並不能避免擴容縮容這個問題所以只要能把V4.0的髒活變成 1. 擴容縮容對前端APP透明(業務代碼不需要任何改動) 2.擴容縮容全自動化且對在線服務無影響 那麼他就拿到了作為Saas的門票.
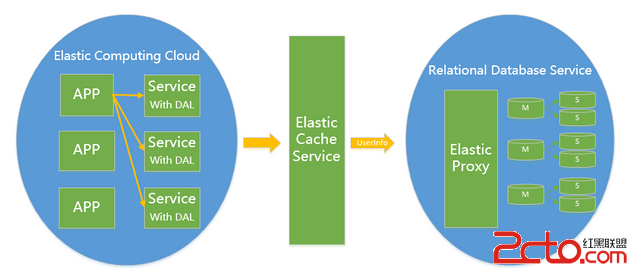
對於架構實現的關鍵點需要滿足對業務透明擴容縮容對業務不需要任何改動 那麼就必須eat our own dog food在你mysql saas內部解決這個問題一般的做法是我們需要引入一個Proxy,Proxy來解析sql協議按sharding key 來尋找cluster, 判斷是讀操作還是寫操作來請求主 或者 從這一切內部的細節都由proxy來屏蔽。
這裡借淘寶的圖來列舉一下proxy需要干哪些事情
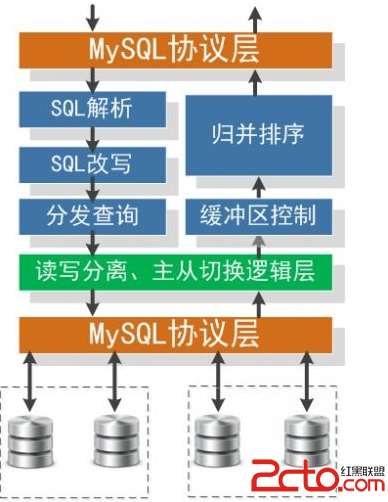
百度公開的技術方案中也有類似的解決方案見文章最後資料部分鏈接
對於架構實現的關鍵點擴容縮容全自動化且對在線服務無影響 擴容縮容對應到的數據操作即為數據拆分和數據合並要做到完全自動化有非常多不同的實現方式總體思路和V4.0介紹的瓶頸部分有關目前來看這個問題比 較好的方案就是實現一個偽裝slave的sync slave, 解析mysql同步協議然後實現數據拆分邏輯把全量數據進行拆分。具體架構見下圖
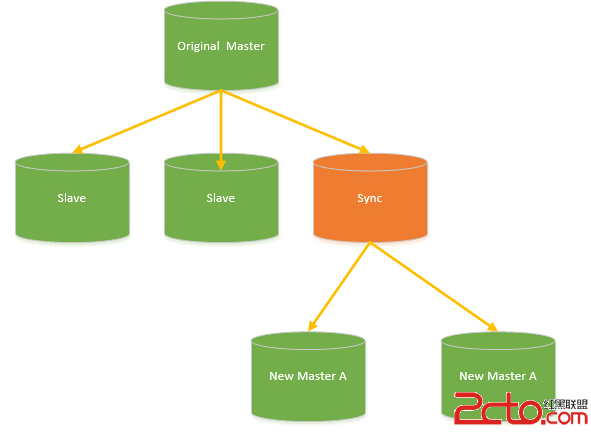
其中Sync slave對於Original Master來說和一個普通的Mysql Slave沒有任何區別也不需要任何額外的區分對待。需要擴容/縮容時掛上一個Sync slave,開始全量同步+增量同步等待一段時間追數據。以擴容為例若擴容後的服務和擴容前數據已經基本同步了這時候如何做到切換對業務無影響 其實關鍵點還是在引入的proxy,這個問題轉換為了如何讓proxy做熱切換後端的問題。這已經變成一個非常好處理的問題了.
另外值得關注的是2014年5月28日——為了滿足當下對Web及雲應用需求甲骨文宣布推出MySQL Fabric在對應的資料部分我也放了很多Fabric的資料有興趣的可以看看說不定會是以後的一個解決雲數據庫擴容縮容的手段