MySQL 體系結構
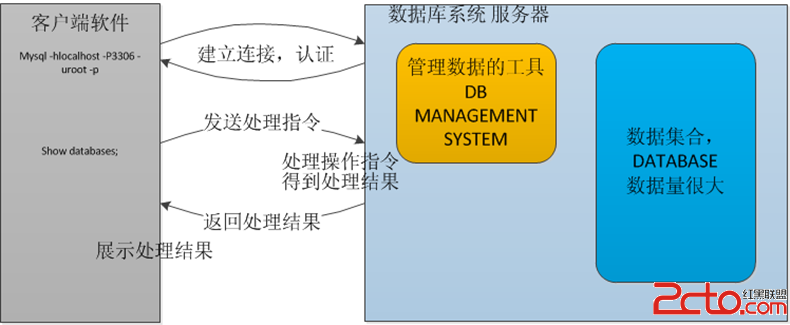
學習一門數據庫系統首先得了解它的架構,明白它的架構原理對於後期的分析問題和性能調優都有很大的幫助,接下來就通過分析架構圖來認識它。
目錄
概述
架構圖
總結
架構圖
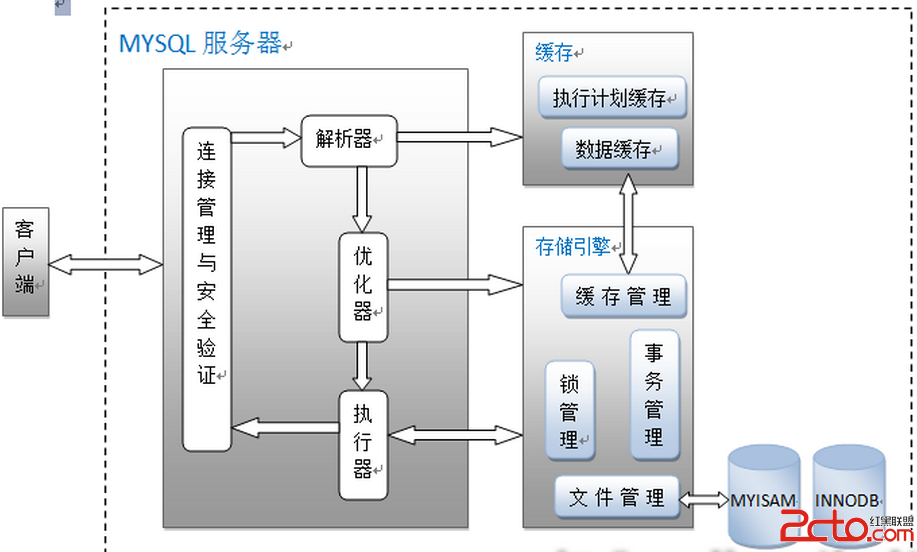
1.連接管理與安全驗證
每個客戶端都會建立一個與服務器連接的線程,服務器會有一個線程池來管理這些連接;如果客戶端需要連接到MYSQL數據庫還需要進行驗證,包括用戶名、密碼、主機信息等。
2.解析器
解析器的作用主要是分析查詢語句,最終生成解析樹;首先解析器會對查詢語句的語法進行分析,分析語法是否有問題。還有解析器會查詢緩存,如果在緩存中有對應的語句,就返回查詢結果不進行接下來的優化執行操作。前提是緩存中的數據沒有被修改,當然如果被修改了也會被清出緩存。
在有的書籍中會把查詢緩存放在解析之前,難道不需要判斷語法是否有錯誤嗎?如果有知道的麻煩幫忙解惑。
3.優化器
優化器的作用主要是對查詢語句進行優化操作,包括選擇合適的索引,數據的讀取方式,包括獲取查詢的開銷信息,統計信息等,這也是為什麼圖中會有優化器指向存儲引擎的箭頭。之前在別的文章沒有看到優化器跟存儲引擎之間的關系,在這裡我個人的理解是因為優化器需要通過存儲引擎獲取查詢的大致數據和統計信息。
4.執行器
執行器包括執行查詢語句,返回查詢結果,生成執行計劃包括與存儲引擎的一些處理操作。
存儲引擎
1.鎖的種類
鎖的由來是為了解決並發控制,對於一個查詢語句為了不讓查詢的數據被其它語句所更改就需要將數據附加鎖,我們比較熟悉的鎖有共享鎖和排他鎖。
2.鎖的粒度
任何一種操作都需要消耗資源,附加鎖同樣也會消耗資源,同樣的一個查詢如果我們鎖定的資源越少那麼並發就越高同時資源消耗越大,反之並發低消耗越小。
表鎖(table lock)
表鎖是MYSQL裡面資源消耗最小的鎖,只需要在查詢對應的表上附加鎖就可以了。一個SQL語句首先需要獲得鎖,首先查詢語句會判斷表上面是否存在鎖,如果表上面有排他鎖那麼查詢語句就會等待,所以查詢語句只需要獲取一次鎖就可以了,不需要再往下一層去判斷是否存在行鎖,鎖資源消耗低。同時如果有一個排他鎖附加在該表上面其它的語句都需要等待改鎖釋放,系統的並發度很低。
行鎖(row lock)
行鎖與表鎖剛好相反,一個update語句首先它會判斷對應的表是否存在排他鎖,如果不存在接下來會判斷對應的更新記錄上面是否存在鎖,如果不存在附加排他鎖。行鎖的獲取鎖資源方面消耗比表鎖更多,但是由於它只在對應的記錄行上面添加鎖,不影響對應表的其它記錄行,系統的並發度比表鎖要高。
死鎖
在一個高並發的系統中,由於鎖和事務的存在往往會有死鎖的情況發生。舉個簡單的死鎖的例子,假如兩個事務同時執行。
事務1
START TRANSACTION;
UPDATE USER SET NAME='張三' WHERE ID=1
等待5秒
UPDATE USER SET NAME='李四' WHERE ID=2
COMMIT;
事務2
START TRANSACTION;
UPDATE USER SET NAME='張三' WHERE ID=2
等待5秒
UPDATE USER SET NAME='李四' WHERE ID=1
COMMIT;
由於兩個事務在更新第一天語句的時候都鎖定了對應的行記錄,當進行第二天更新語句的時候由於對應的記錄行已經被鎖定需要等待,陷入了死循環,這就是常見的死鎖的情況。
3.事務
mysql和其它的數據庫產品有一個很大的不同就是事務由存儲引擎所決定,例如MYISAM,MEMORY,ARCHIVE都不支持事務,事務就是為了解決一組查詢要麼全部執行成功,要麼全部執行失敗。
mysql事務默認是采取自動提交的模式,除非顯示開始一個事務
SHOW VARIABLES LIKE 'AUTOCOMMIT';
修改自動提交模式,0=OFF,1=ON
注意:修改自動提交對非事務類型的表是無效的,因為它們本身就沒有提交和回滾的概念,還有一些命令是會強制自動提交的,比如DLL命令、lock tables等。
SET AUTOCOMMIT=OFF
或
SET AUTOCOMMIT=0
大家可能比較熟悉的就是事務的ACID特性:原子性,一致性,隔離性,持久性。
原子性:事務是不可分割的最小工作單元,整個事務要麼全部提交要麼全部回滾失敗。
一致性:數據庫總是從一個一致性狀態轉換到另一個一致性的狀態。
隔離性: 一個事務所做的更改在最終提交之前其它事務是不可見的。
持久性:事務一旦提交所做的修改就會永久保存在數據庫中,即使系統崩潰,數據也不會丟失。
隔離級別
隔離級別是用來規定一個事務所做的更改,通常會默認系統使用哪一種隔離級別,通常隔離級別越高系統的並發就越低,系統開銷也越大,mysql有四種隔離級別分別是:
未提交讀(READ UNCOMMITTED):未提交讀隔離級別也叫讀髒,就是事務可以讀取其它事務未提交的數據。
提交讀(READ COMMITTED):在其它數據庫系統比如SQL Server默認的隔離級別就是提交讀,已提交讀隔離級別就是在事務未提交之前所做的修改其它事務是不可見的。
可重復讀(REPEATABLE READ):保證同一個事務中的多次相同的查詢的結果是一致的,比如一個事務一開始查詢了一條記錄然後過了幾秒鐘又執行了相同的查詢,保證兩次查詢的結果是相同的,可重復讀也是mysql的默認隔離級別,。
可串行化(SERIALIZABLE):可串行化就是保證讀取的范圍內沒有新的數據插入,比如事務第一次查詢得到某個范圍的數據,第二次查詢也同樣得到了相同范圍的數據,中間沒有新的數據插入到該范圍中。
查詢系統默認隔離級別、當前回話隔離級別
select @@global.tx_isolation,@@tx_isolation;
分別設置系統和回話當前隔離級別為可提交讀
/*設置系統當前隔離級別*/
SET global transaction isolation level read committed;
/*設置回話當前隔離級別*/
SET SESSION transaction isolation LEVEL read committed;
注意:在同一個事務中避免出現混合存儲引擎的表,比如混合了事務和非事務的表,正常提交不會有影響,如果出現了回滾操作,非事務的表的修改就無法回滾這樣就會導致數據庫處於不一致的狀態,一旦出現這種情況將很難修復,所以表選擇合適存儲引擎很重要。
隱式和顯示鎖定
所謂的隱式鎖定就是系統自動加鎖而不是認為的添加鎖,INNODB采用兩段鎖定協議,在事務的執行過程中隨時執行鎖定,在執行commit或者rollback的時候所有的鎖才同時釋放
顯示鎖定就是人為的添加鎖,比如lock tables或者unlock tables,顯示鎖定是基於服務器層的設定和存儲引擎無關,就是不管你的表是myisam還是innodb都可以顯示添加lock tables,但是myisam本身就是lock tables所以再顯示添加也多此一舉。
注意:避免在事務中使用lock tables
存儲
存儲這塊知識放在後面單獨講解
總結
對於mysql的體系結構每個人的理解可能會有所不同,上圖是根據自己的理解繪制的不是官方標准的體系結構,僅供參考。