什麼是分布式計算?所謂分布式計算是一門計算機科學,它研究如何把一個需要非常巨大的計算能力才能解決的問題分成許多小的部分,然後把這些部分分配給許多計算機進行處理,最後把這些計算結果綜合起來得到最終的結果。----百度百科
這就是說我們一台機器不能完成這樣的工作量,需要將數據和計算分到多台機器上才能更加高效的處理請求。
接下來首先需要決策的就是,要選擇什麼樣子的分布式模型進行系統的設計,一般有兩種模型供參考:
a) 心化的分布式模型
簡單理解就是所有的命令都會被發送到中心節點,由中心節點統一的分析,將經過分析的事件拆分,發送到每一個非中心節點上。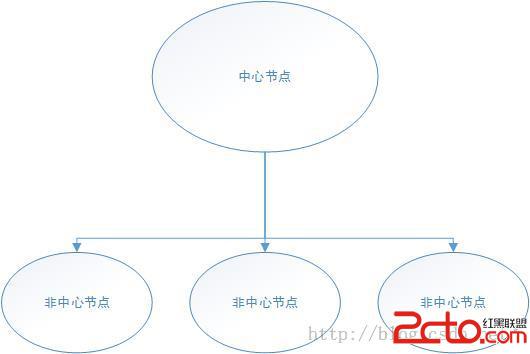
這樣,所有的命令都先發送到中心節點,然後轉發到非中間節點。但是,這有一個問題就是,中間節點的分析與轉發的能力有限,當請求達到一定的程度以後,增加非中心節點的數量的作用就會非常小。
對於上述中間節點的分析和轉發能力有限的問題,如果只是分析能力有限,一個優化的方式是通過添加二級中心節點來分擔一級中心節點的壓力。所有的命令都被發送到中心節點,中心節點做少量的分析就轉發到二級節點,由二級節點進一步分析,再發送到非中心節點。
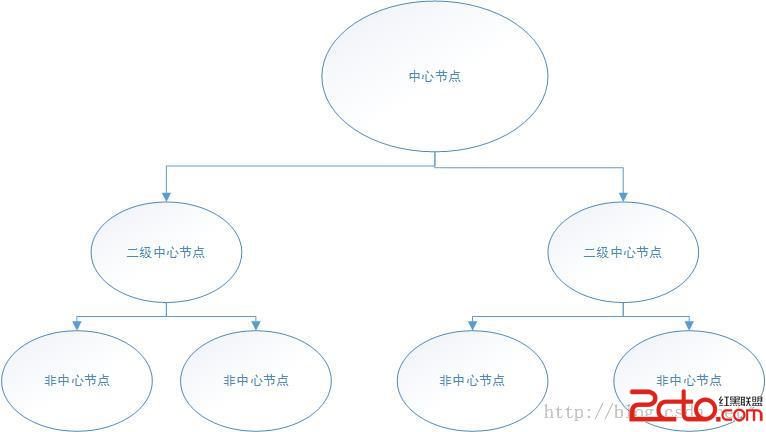
在上述的情況中,中心節點的轉發能力也是致命缺點,那麼如何再一次提升系統的性能呢?這就要引入非中心化去解決問題。
b) 去中心化的分布式模型
去中心化的模型就是, 沒有中心的模型。各個節點只按照自己的邏輯進行傳遞消息。如下所示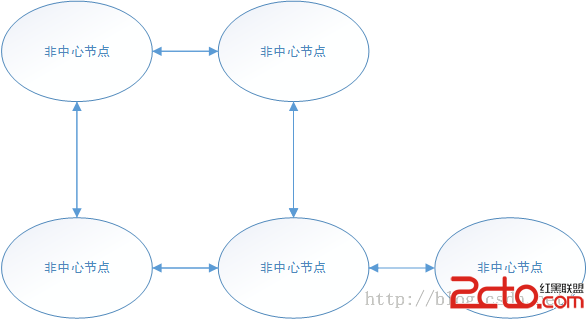
這就是去中心化的模型,模型並不會在意哪些節點和那些節點能夠聯通,每個節點只會去負責自己的那一方面事情。
中心化的分布式模型就像是:中國古代王權,是所有的權利都是大王來控制。
去中心化分布式模型就像是:平民自家過自家的日子,需要連同作業的時候通過自己的組織作業進行。
由上述分析引出我們需要了解的技術內容,只列舉一部分,請大家自行擴展:
這兩種模型有哪些例子?
MySQL的一主雙從(MSS),MangDB Master, MapReduce Jobtracker?
zookeeper, cassandra?