我們知道分析MySQL語句查詢性能的方法除了使用EXPLAIN 輸出執行計劃,還可以讓MySQL記錄下查詢超過指定時間的語句,我們將超過指定時間的SQL語句查詢稱為“慢查詢”。
一、 起因
研發反應某台數據庫僵死,後面的會話要麼連接不上,要麼要花費大量的時間返回結果,哪怕是一個簡單的查詢。
二、 處理
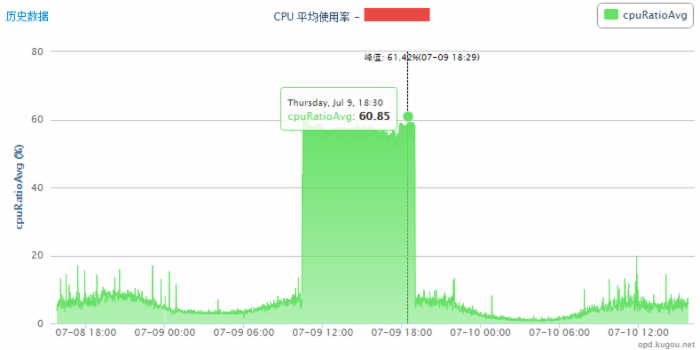
首先去監控平台查看服務器以及數據庫狀態,發現這台數據庫有大量的慢查詢。繼續看服務器監控,CPU 平均使用率較高,IO 讀寫平均值正常。登錄到 MySQL,使用 SHOW PROCESSLIST 查看會話狀態,總數居然有 600+,這是很不正常的。查看慢查詢日志,發現出問題的 SQL 主要集中在幾個,有 SUM、有 COUNT、有等值操作等等。這台 MySQL 服務器的 long_query_time 設置為 3秒,而一個簡單的查詢卻要幾十秒,這顯然是有問題的。寫腳本試著 kill 掉相關的會話,發現於事無補,仍然有大量的連接進來。此時使用 top 查看服務器狀態,mysqld 進程占用內存和 CPU 居高不下。
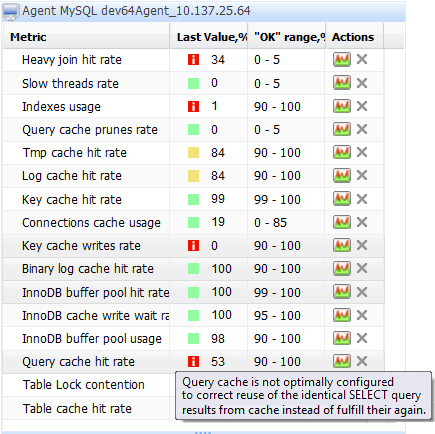
故障期間的慢查詢數,如圖:

CPU 平均使用率,如圖:
接著使用 SHOW FULL PROCESSLIST 查看完整狀態,在最上面居然發現幾條 SQL。這些 SQL 操作使用子查詢實現,TIME 列居然達到了 30000 秒,折算過來差不多 10 小時。EXPLAIN 這些語句,居然出現了 USING TEMPORY 和 USING FILESORT,可以看出這些語句是很糟糕的。於是跟開發確認,緊急把這些會話 kill 掉。稍等片刻,會話數立馬降下來,只有 100+,top 查看 mysqld 進程,內存和 CPU 都呈現下降的趨勢。接著分析開發說上午 9 時寫了這些 SQL,發現有問題,注釋掉了。新的代碼雖然沒有此類 SQL,但之前建立的連接並不會釋放。解決問題和出現問題的時間差剛好可以和添加子查詢的時間對應,就可以確認子查詢是此次故障的罪魁禍首。
三、 總結
通過這個故障,總結如下幾點:
第一,查看服務器監控和 MySQL 監控,分析服務器以及 MySQL 性能,找出異常;
第二,如果是慢查詢導致,查看慢查詢日志,找出出現問題的 SQL,試著優化,或者把結果緩存;
第三,分清主次,先解決大塊問題,後解決細小問題。 把大塊的異常解決,小問題就迎刃而解了。比如本文中的例子,把耗費時間長的會話 kill 掉後,後面的連接就正常了;
第四,總結分析。
四、 技巧
最後,附上一個快速kill 掉 MySQL 會話的方法:
首先使用如下語句分析出有問題的 SQL:
/usr/local/mysql/bin/mysql -uroot -p'XXX' \ -e "SHOW FULL PROCESSLIST;" | more
然後將 SHOW FULL PROCESSLIST 的結果保存到一個文件:
/usr/local/mysql/bin/mysql -uroot -p'XXX' \
-e "SHOW FULL PROCESSLIST;" | \
grep "XXX" | awk '{print $1}' > mysql_slow.txt
最後使用如下簡單的 Shell 腳本 kill 掉相關會話:
SELECT concat('kill ',id,';')
FROM information_schema.processlist
WHERE info like 'XXX';
當然也可以使用如下 SQL 拼接 kill 語句:
SELECT concat('kill ',id,';')
FROM information_schema.processlist
WHERE info like 'XXX';
本文對MySQL慢查詢導致故障的起因,處理方法,所需的技巧進行了全面分析,希望可以讓大家更好的了解MySQL慢查詢,對大家的。