帶你認識MySQL之MySQL體系結構
序
最近一直在忙項目,各種加班加點,項目上線,漸漸的沒有了學習的時間。這不,剛這幾天才能抽出點時間,忙裡偷閒,正在看一本數據庫的書籍,相信很多小伙伴們也都看過 — — 《MySQL 技術內幕:InnoDB 存儲引擎》。這本書很詳細的講述了 MySQL 的設計思想,體系結構,存儲引擎,索引,事務,以及對性能的調優等。當然,現在我也是剛剛看了一部分,至於現在寫這篇文章,主要是為了記錄一下我的學習歷程,並且和大家分享一些新的東西。
背景
至於背景嘛,這裡就不多說了,如果感興趣的話,還是推薦大家看一看這本書的。那麼現在嘛,先了解一下 MySQL 的體系結構也不錯,沒准還可以拿出來炫耀一下(純屬忽悠)。
概念
在說體系結構之前,先說兩個名詞,而且是在數據庫領域裡很常見的兩個詞:“數據庫”和“數據庫實例”。
我想,小伙伴們肯定都知道這兩個名詞的,而且有時候還經常會區分不出來。那麼,什麼是“數據庫”?什麼又是“數據庫實例”呢?下面我就詳細跟大家說說。
首先說“數據庫”,數據庫是物理操作系統文件或其他形式的文件類型的集合。在 MySQL 中,數據庫文件可以是 frm、myd、myi、ibd 結尾的文件。
然後說“數據庫實例”,數據庫實例是由數據庫後台進程/線程以及一個共享內存區組成。共享內存可以被運行的後台進程/線程所共享。需要注意的是,數據庫實例才是真正用來操作數據庫文件的。
這兩個詞有時可以互換使用,但兩者的概念完全不同。在 MySQL 中,實例和數據庫通常關系是一 一對應的,即一個實例對應一個數據庫,一個數據庫對應一個實例。但是,在集群情況下,可能存在一個數據庫可被多個實例使用的情況。
體系結構
MySQL 是一個可移植的數據庫,幾乎能在當前所有的操作系統上運行,如 Unix/Linux、Windows、Mac 和 Solaris。各種系統在底層實現方面各有不同,但是 MySQL 基本上能保證在各個平台上的物理體系結構的一致性。
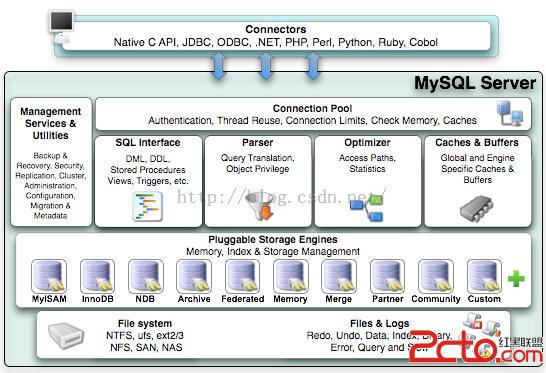
MySQL 由以下幾部分組成:
Connectors:不同語言中與 SQL 的交互
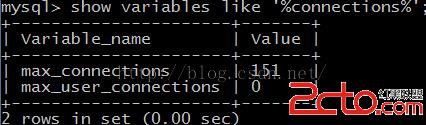
max_connections:就是整個MySQL實例的最大連接數限制 max_user_connections:是單個用戶的最大連接數,這裡未指明是哪個用戶,是任意一個用戶。
Management Serveices & Utilities:系統管理和控制工具
備份和恢復的安全性,復制,集群,管理,配置,遷移和元數據。
Connection Pool:連接池
進行身份驗證、線程重用,連接限制,檢查內存,數據緩存;管理用戶的連接,線程處理等需要緩存的需求。
SQL Interface:SQL 接口
進行 DML、DDL,存儲過程、視圖、觸發器等操作和管理;用戶通過 SQL 命令來查詢所需結果。
Parser:解析器
查詢翻譯對象的特權;SQL 命令傳遞到解析器的時候會被解析器驗證和解析。
Optimizer:查詢優化器
訪問路徑的統計數據;

在 MySQL 優化語句過程中,可以通過設置 optimize_switch 控制優化行為。在生產環境上,某時間段 MySQL 服務器壓力特別大,load 一度達到了 100,查詢發現數據庫中有大量的 sql 語句 state 狀態 result sorting ,result sorting 這種排序特別消耗 cpu 和內存資源。抽取其中的一條 sql 查看執行計劃。
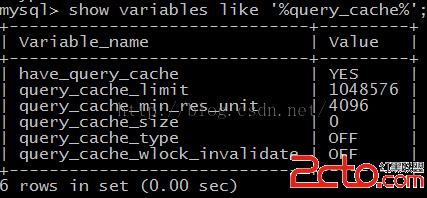
Cache 和 Buffer:查詢緩存
全局和引擎特定的緩存和緩沖區;
Engine:存儲引擎
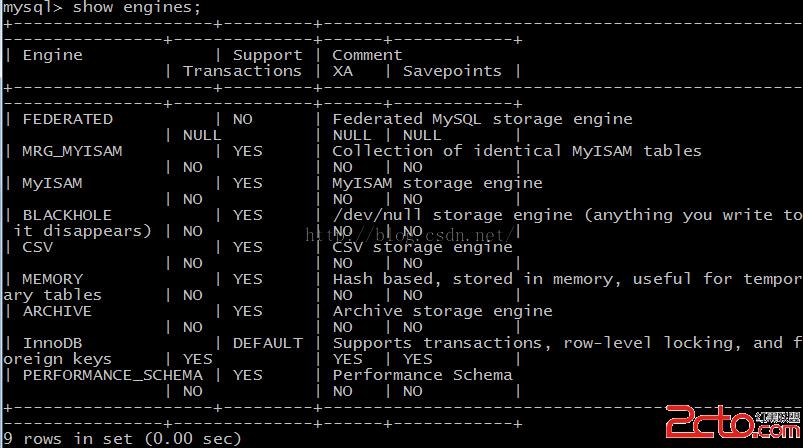
MySQL 的 Windows 版本默認存儲引擎為 InnoDB,InnoDB 支持事務,並且提供行級的鎖定。
結束語
想要認識 MySQL,這裡僅僅是個開始,在後續的學習中,我還會不定時的跟大家分享,同時,小伙伴們有新的想法也可以跟我一塊交流交流。