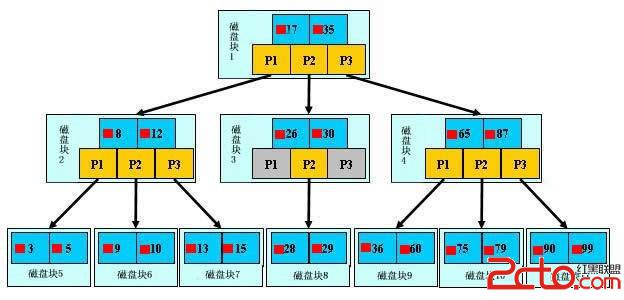
索引常用的數據結構為B+樹。結構如下
 mysql會一直向右匹配直到遇到范圍查詢(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)順序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引則都可以用到,a,b,d的順序可以任意調整。
mysql會一直向右匹配直到遇到范圍查詢(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)順序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引則都可以用到,a,b,d的順序可以任意調整。
2.=和in可以亂序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意順序,mysql的查詢優化器會幫你優化成索引可以識別的形式
3.盡量選擇區分度高的列作為索引,區分度的公式是count(distinct col)/count(*),表示字段不重復的比例,比例越大我們掃描的記錄數越少,唯一鍵的區分度是1,而一些狀態、性別字段可能在大數據面前區分度就是0,那可能有人會問,這個比例有什麼經驗值嗎?使用場景不同,這個值也很難確定,一般需要join的字段我們都要求是0.1以上,即平均1條掃描10條記錄
4.索引列不能參與計算,保持列“干淨”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很簡單,b+樹中存的都是數據表中的字段值,但進行檢索時,需要把所有元素都應用函數才能比較,顯然成本太大。所以語句應該寫成create_time = unix_timestamp(’2014-05-29’);
5.盡量的擴展索引,不要新建索引。比如表中已經有a的索引,現在要加(a,b)的索引,那麼只需要修改原來的索引即可