1、以書的目錄為例,通過查看目錄,再找到對應的內容。因此,索引就是給數據加上了’目錄’,便於快速找到數據
2、索引的作用:
好處: 加快了查詢速度
壞處: a、降低了增刪改的速度
b、增大了表的文件大小(索引文件甚至可能比數據文件還大)
案例: 設有某個表15列,存在10列上有索引,共500w行數據,如何快速導入?
答: 1、把空表的索引全部刪除 2、導入數據 3、數據導入完畢後再建立索引
3、索引算法
設有N條隨機記錄,不用索引,平均查找N/2次,用了索引呢?
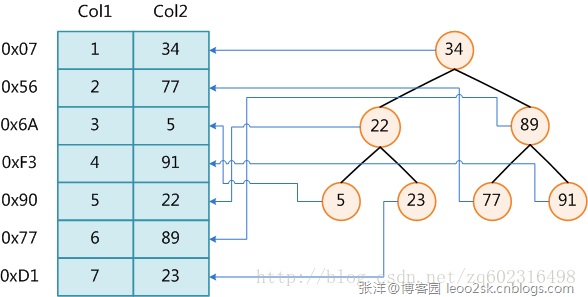
3.1、二叉樹索引對應次數為log2N次
說明例子,數據1,2,3,4,5,6,7,以中間值4為分界點
4
2 6
1 3 5 7
查找3需要多少次?
由於3<4,因此3在二叉樹的左邊,由於3>2,因此在以2為根節點的右邊。結果需要2次
3.2、哈希索引,理論上為1次
說明例子,數據1,2,3,4,5,6,7
hash[1]=001
hash[2]=003
hash[3]=005
hash[4]=007
hash[5]=009
hash[6]=011
hash[7]=013
查找3需要多少次?
先hash下,得到005,這樣就找到了。剛好1次。
hash的不足:
a、浪費空間,因為hash的值不連續。
b、hash要求高,確保每個值的hash值不同
4、索引的使用原則
a、不過度索引
b、索引條件列(where後面最頻繁的條件比較適宜索引)
c、索引散列值,過於集中的值不要索引(如: 性別)
5、如何看表結構
5.1、存儲引擎為myisam

frm為表結構、MYD為數據文件、MYI為索引文件
5.2、存儲引擎為innodb

frm為表結構、ibd為數據文件和索引文件
1、類型
a、普通索引(index): 僅僅是加快查詢速度
b、唯一索引(unique index): 行上的值不能重復
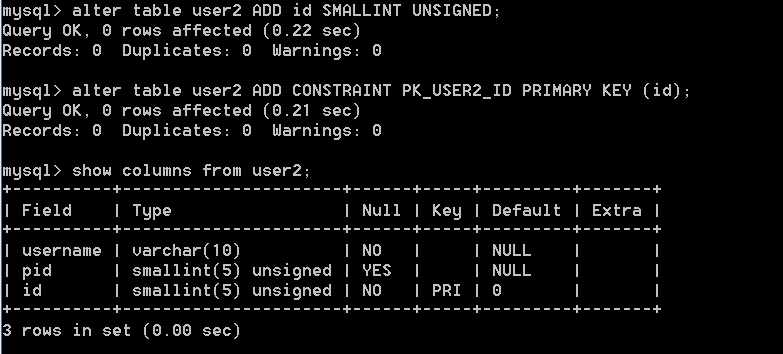
c、主鍵索引(primary key): 不能重復
d、全文索引(fulltext index):
唯一索引和主鍵索引的關系:
主鍵必唯一,但是唯一索引不一定是主鍵;一張表上只能有一個主鍵,但是可以有一個或多個唯一索引
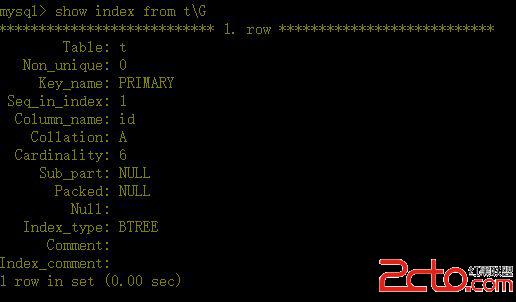
2、如何查看表中的索引
3、建立索引
3.1、對已經存在的表建立索引
語法: alter table 表名 add index/uniqueindex/fulltext index/primary key [索引名](列名) (備注:索引名可選,不指定則與列名相同)
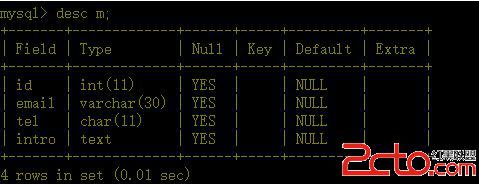
表結構:
create table m( id int, emailvarchar(30),tel char(11), intro text)engine=myisam charset=utf8;
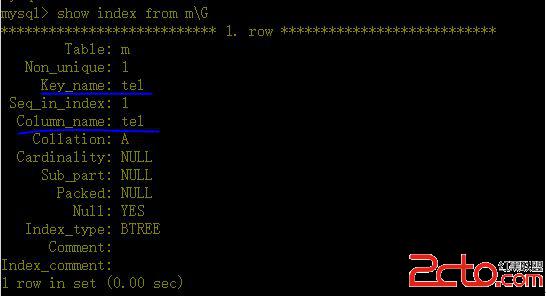
a、給tel列建立普通索引
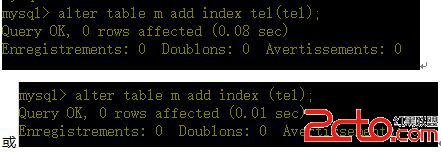
(備注: 指定索引名與列名相同)
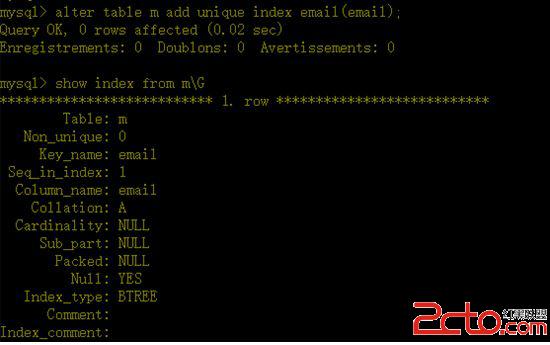
b、給email列加上唯一索引
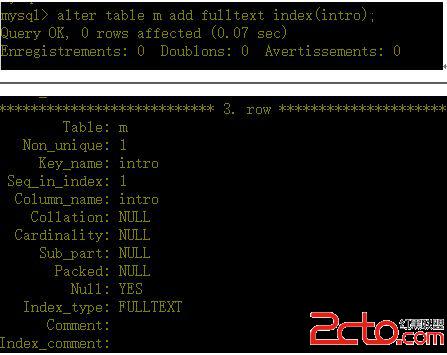
c、給intro列加上全文索引
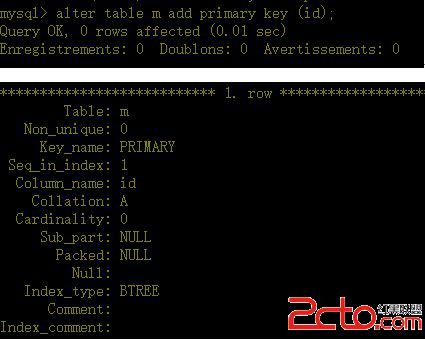
d、給id列加上主鍵索引
e、加上多列組合索引

(備注: 這個普通索引m作用在列email和tel列上)
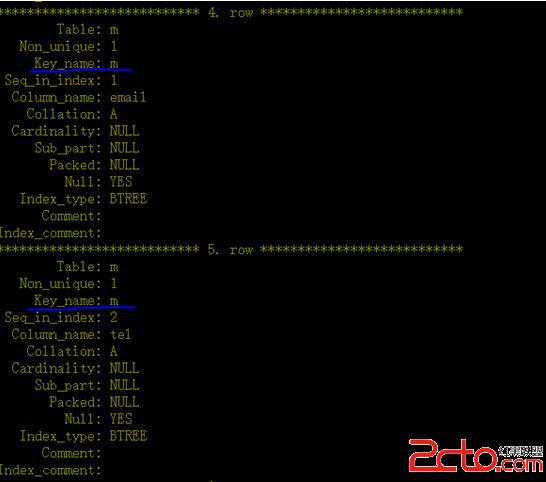
錯誤點:

錯誤原因: 沒有指定該索引應用在那個列上。
3.2、建立新表時,指定索引
create table m(id int primary keyauto_increment, email varchar(30), tel char(11), intro text, index(tel), uniqueindex(email), fulltext index(intro) )engine=myisam charset=utf8;
4、刪除索引
4.1、刪除普通索引/唯一索引/全文索引

4.2、刪除主鍵索引
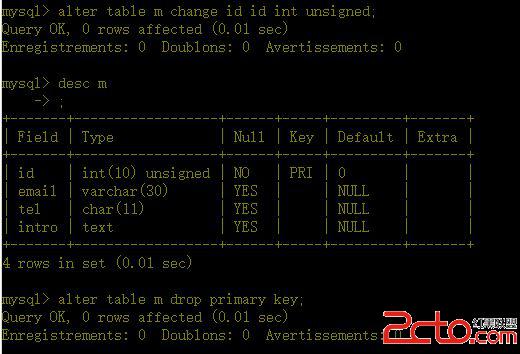
如果主鍵列本身就是自增的,則刪除時會報錯
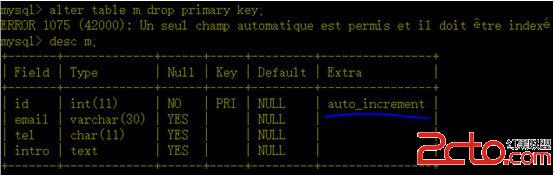
這個情況,應該先修改列的自增屬性。
三、全文索引
全文索引在mysql的默認情況下,對於中文意義不大
因為英文有空格,標點符號來拆成單詞,進而對單詞進行索引。
而對於中文,沒有空格來隔開單詞。mysql無法識別每個中文詞。
用法: match(全文索引名) against(‘keyword’);