1、表設計要符合三范式,當然,有時也需要適當的逆范式
2、什麼是三范式
一范式: 具有原子性,不可再分割
二范式: 在滿足一范式的基礎上,我們考慮是否滿足二范式。只要表的記錄滿足唯一性,也是說,同一張表,不可能出現完全相同的記錄,一般說,在表中設計一個主鍵即可。
三范式: 在滿足二范式的基礎上,我們考慮是否滿足三范式。只要表滿足沒冗余性。
1、sql優化的一般步驟
a、通過show status命令了解各種sql的執行效率
b、定位執行效率較低的sql語句
c、通過explain/desc分析低效率的sql語句的執行情況
d、確定問題並采取相應的優化措施
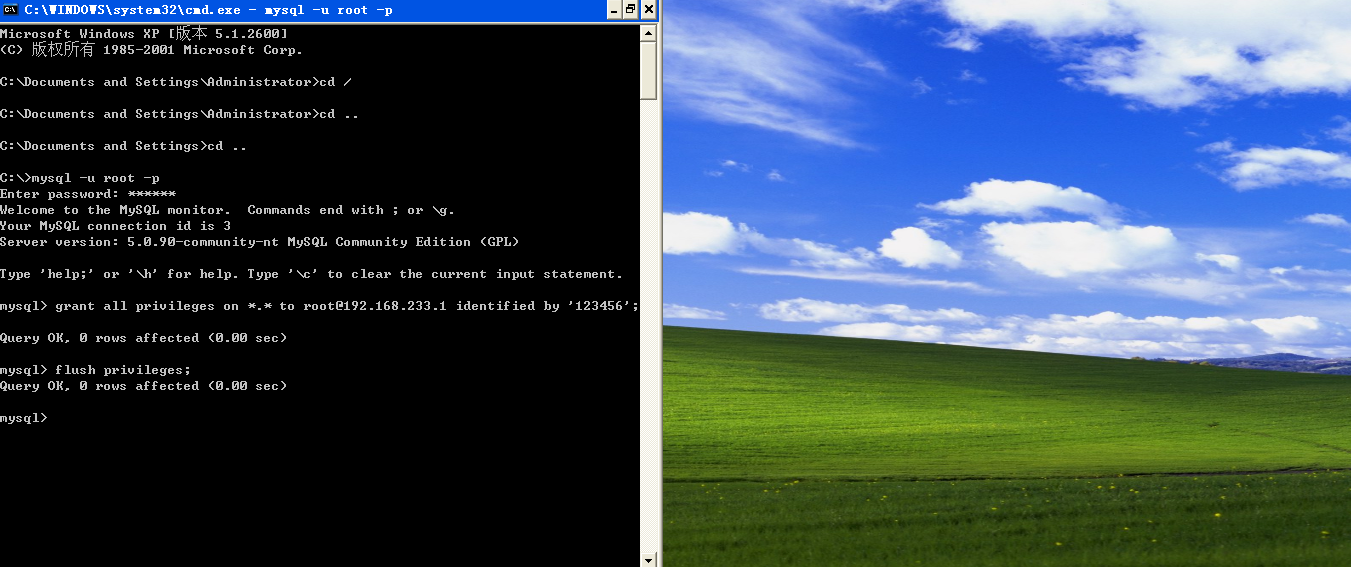
2、showstatus命令
該命令可以顯示mysql數據庫當前狀態,主要關心的是’com’開頭的指令
showstatus like ‘com%’ ó show session status like ‘com%’//顯示當前控制台的情況
showglobal status like ‘com%’ //顯示數據庫從啟動到現在的情況
3、showvariables命令
該命令可以查看mysql當前的變量設置,主要關心的是慢查詢時間
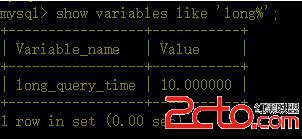
4、如何在mysql中找到慢查詢的sql語句
(備注: mysql數據庫支持把慢查詢語句,記錄到日志中給程序員分析;默認情況下,mysql不啟用慢查詢日志)
步驟: a、啟動mysql慢查詢
a1、在啟動mysql服務時,指定—slow-query-log
a2、在利用客戶端登進mysql後,設置變量
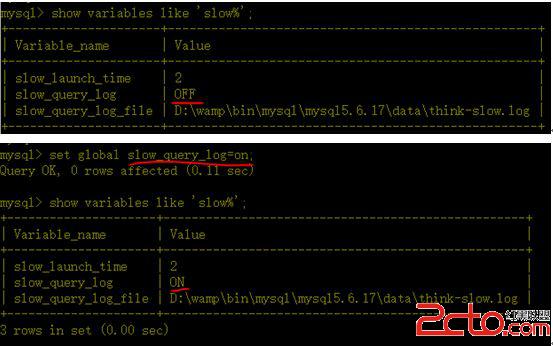
b、查看慢查詢時間
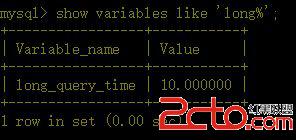 默認為10秒
默認為10秒
c、修改慢查詢時間
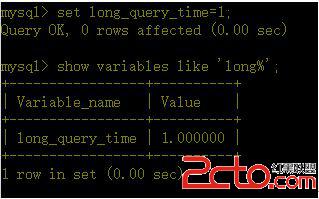 設置為1秒
設置為1秒
(這個只能在當前環境生效,如果想每次都生效,就修改mysql的配置文件)
d、查看慢查詢日志
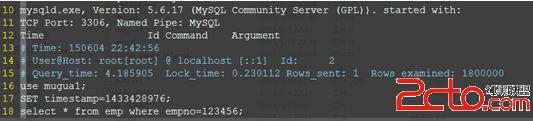
e、根據慢查詢的sql語句,進行優化。最廉價的做法就是加索引

f、加上索引後
5、索引的影響
a、增加磁盤空間

b、給增刪改帶來不便
6、哪些列上適合添加索引
a、頻繁地作為查詢條件字段應該創建索引
b、唯一性太差的字段(即該字段的值變化不大)不適合單獨創建索引,即使頻繁作為查詢條件
c、更新非常頻繁的字段不適合創建索引
d、不會出現在where子句中字段也不應該創建索引
7、索引的使用
測試表:
Create Table: CREATE TABLE`t2` (
`id` int(11) NOT NULL DEFAULT '0',
`name` char(5) DEFAULT NULL,
`age` tinyint(4) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULTCHARSET=utf8;
insert into t2(name,age) values('a',2),('aa',3),('b',4),('c',3);
查詢要使用索引最重要的條件是查詢條件中需要使用索引。
下列幾種情況下有可能使用到索引:
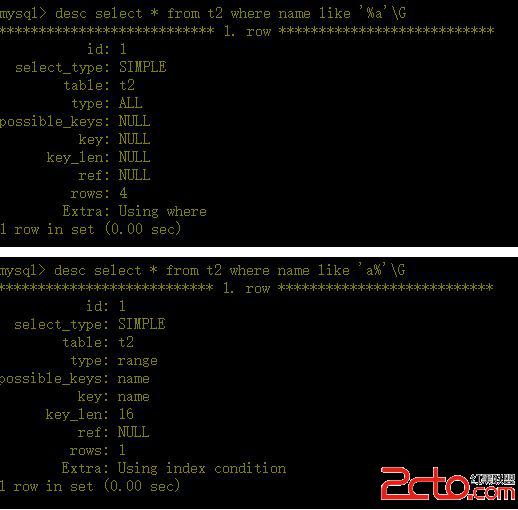
a、對於創建的多列索引,只要查詢條件使用了最左邊的列,索引一般就會被使用。

b、對於使用like的查詢,查詢如果是 ‘%aaa’不會使用到索引‘aaa%’ 會使用到索引。
下列的表將不使用索引:
a、如果條件中有or,即使其中有條件帶索引也不會使用。
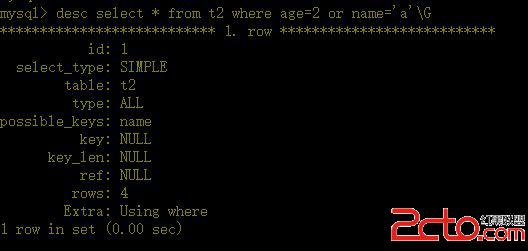
b、對於多列索引,不是使用的第一部分,則不會使用索引。
c、like查詢是以%開頭
d、如果列類型是字符串,那一定要在條件中將數據使用引號引用起來。否則不使用索引。
e、如果mysql估計使用全表掃描要比使用索引快,則不使用索引。
8、驗證索引使用情況
showstatus like ‘Handler_read%’;
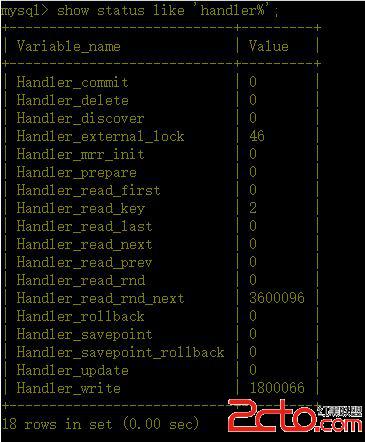
備注:
handler_read_key:這個值越高越好,越高表示使用索引查詢到的次數。
handler_read_rnd_next:這個值越高,說明查詢低效。
9、常用SQL優化
a、大批量插入數據:
對於MyIsam:
1、alter table table_name disable keys;
2、loading data;
3、alter table table_name enable keys;
對於Innodb:
1、將要導入的數據按照主鍵排序
2、set unique_checks=0,關閉 唯一性校驗
3、set autocommit=0,關閉自動提交
(提示: myisam和innodb的區別是:
a、myisam不支持外接,innodb支持
b、myisam不支持事務,innodb支持)
b、優化group by
默認情況下,mysql對group by後面的列名進行排序。如果查詢中包括group by但用戶想要避免排序結果的消耗,可以使用order by null禁止排序
當一個表的數據很大的時候,其它的優化方式已經都考慮進去。起到的作用不大時,就要考慮分表了。即把一張大表分割成多張小表。
分表方式:
a、垂直分表
此時,表中存在很多列,這個時候可以通過主鍵,把表中列分成多張表,然後再根據主鍵進行關聯.(拆分後,每張表的列都不同)
分表前: 個人信息表
id
name
age
intro
1
a
11
xxxx
2
b
22
yyyy
分表後: 個人信息表
id
name
age
1
a
11
2
b
22
個人介紹表
id
intro
1
xxxx
2
yyyy
b、水平分表
可以通過取模的方式,進行分表。因此,需要判斷分成幾張小表,即模的值為多少。另外,拆分後,每張表的列都是一致的。
分表前: 個人信息表
id
name
age
intro
1
a
11
xxxx
2
b
22
yyyy
確定取模的值為2,因此可以把這種表分為兩張小表
1、判斷id的值,id/2=?
分表後: 個人信息表0
id
name
age
intro
1
a
11
xxxx
個人信息表1
id
name
age
intro
2
b
22
yyyy
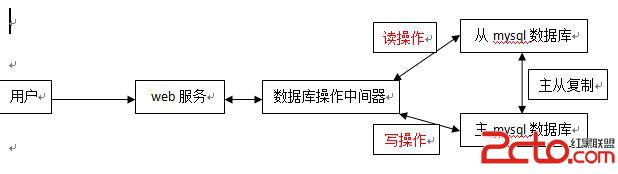
四、讀寫分離
通常來說,一台mysql服務器承載著所有關於數據庫的操作。但是在訪問量大的時候,mysql服務器很容易出現瓶頸。為了減少mysql服務器的壓力,(mysql本身支持主從復制功能)
可以通過分離讀寫操作。
1、讀寫分離前示意圖

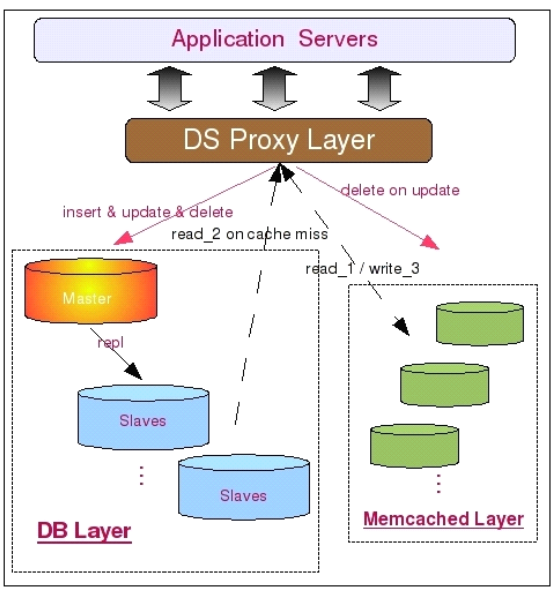
2、讀寫分離