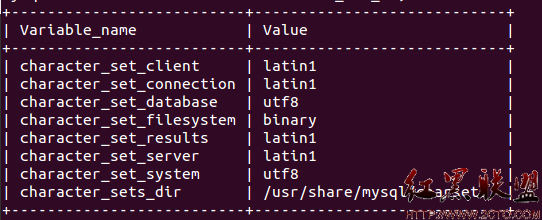
數據庫(DataBase,即RDBMS裡的DB)是一個用來存儲信息的倉庫,它的結構簡單、規則。
數據庫裡的數據集都被組織成表(table)。
每個表由多個行(row)和列(column)組成。
表中的每一行稱為一條記錄(record)。
記錄可以包含多項信息;表裡的每一列對應於其中的一項。
管理系統(Management System,即RDBMS裡的MS)是一個軟件,我們可以通過它來插入(insert)、檢索(retrieve)、修改(modify)或刪除(delete)記錄。
關系(Relational,即RDBMS裡的R)一詞表示這是一種特殊的DBMS,其長處在於通過查找兩個表裡的共同元素,將分別存放於兩個表裡的信息聯系(即匹配)起來。RDBMS的強大之處在於:它能方便地將這些表裡的數據提取出來,並把相關表裡的信息結合起來生成答案,回答那些只靠單個表無法回答的問題。(事實上,“關系”的正式定義與我在本書中用它的方式有所不同。為此,我先向那些純粹主義者道歉。不過,我的定義更有助於表達出RDBMS的用途。) 服務器強制執行並發控制,可以防止兩個用戶同時修改同一條記錄。所有客戶端請求都要經過服務器,因此服務器會負責安排處理它們的先後順序。即使出現多個客戶端同時訪問同一個表的情況,它們也不用先找到對方進行協商。它們只需把自己的請求發往服務器,然後由服務器來決定執行這些請求的順序。 不是只有在數據庫所在的那台機器上才能登錄。MySQL工作在網絡環境裡,因此你可以在任意地方運行MySQL客戶端程序,它都能夠通過網絡連接到服務器。距離不是問題!你可以在世界的任何地方訪問服務器。例如,你的服務器位於澳大利亞,那麼就算你帶著筆記本電腦旅行到了冰島,你也仍然可以訪問自己的數據庫。這是否意味著任何人都能夠通過互聯網看到你的數據呢?答案是“不能”。MySQL有一套靈活的安全機制,你可以設定只有得到授權的人才能訪問。此外,你還可以進一步限制這些人的操作。例如,財務部的Sally應該有查看和更新(修改)記錄的權限;而服務台的Phil卻只應該有查看記錄的權限。總之,你可以把這種訪問權限控制細化到每一個人。如果你只想運行一個自屬的系統,那麼你完全可以把訪問權限設置為只允許服務器上的客戶端程序進行連接。 了解MySQL所能理解的SQL基礎知識。(MySQL與其他RDBMS所使用的SQL有所不同,因此你最好也能快速浏覽一下本節的內容,從而確認一下MySQL的SQL實現與你熟悉的版本是否存在差異。) 了解MySQL自帶的標准客戶端程序是如何與MySQL服務器進行通信的。前一節講過,MySQL采用的是“客戶端/服務器”體系結構。其中,服務器運行在數據庫所在的機器上;而客戶端則是通過網絡連接到服務器。本教程主要依賴於客戶端程序mysql,它首先讀取你輸入的SQL查詢語句,把它們發送到服務器執行,然後把執行結果顯示在你面前。客戶端mysql可以在MySQL所支持的所有平台上運行,並且提供了與服務器進行交互的最直接的方式。不過根據需要,有些示例會使用mysqlimport或者mysqlshow來代替。 必須安裝MySQL軟件。 要有一個能夠連接數據庫服務器的MySQL賬號。 要有一個用來操作的數據庫。 -h host_name(另一種形式是:--host=host_name) -u user_name(另一種形式是:--user=user_name) -p(另一種形式是:--password) president表。其中包含美國歷任總統的描述性記錄。我們需要用它來實現聯盟網站上的在線小測驗(對聯盟通訊兒童專欄裡出現的小測驗進行交互式模擬)。 member表。用於保存聯盟每位成員的最新個人資料。我們可以用它來創建成員名錄的印刷版本和在線版本,用它來向到期成員自動發送提醒通知,還可以用它做很多其他事情。 姓名。在表裡,表示姓名的方式有好幾種,如使用單列包含整個名字,或用不同的列分別表示姓(last name)和名(first name)。使用單列來表示當然更簡單一些,但這種做法不夠靈活,存在一些限制。 出生地(城市和州)。與姓名的情況類似,它既可以用一列來表示,也可以用多列表示。采用單列來表示的做法顯得更簡單些;但與姓名的情況一樣,使用多列能實現某些更復雜的操作。例如,若把州名與市名分開表示,那麼像“找出出生在某個州的總統共有多少位”這種類似的操作便能輕易地實現。我們將使用兩個單獨的列來分別存放州名與市名。 出生日期和逝世日期。這裡唯一需要特殊處理的事情是:因為有些總統依然健在,所以我們不能要求必須填上逝世日期。特殊值NULL的意思即表示“無值”,因此我們可以在逝世日期列裡用它來表示該位總統“依然健在”。 姓名。我們將沿用與president表相同的3列表示法:姓、名和姓名後綴。 ID編號。這是一個唯一值,為每個首次加入的成員分配一個。聯盟此前從未對成員編過號,但現在需要所有的記錄都更系統化,因此這裡需要這個值。(希望你能不斷發現MySQL的好處,並找到更多將編號應用於聯盟記錄的方式。當想要將member表裡的行,與你所創建的成員相關的其他表建立關聯時,使用編號則會比使用姓名更容易實現。) 有效期。所有成員必須定期更新其成員資格,以避免過期。對於某些應用程序,可能還需要把最近一次資格更新後的起始日期存儲起來,但“美史聯盟”不需要這樣做。成員資格的有效期是一個變值(通常有1年、2年、3年或者5年之分),而最近一次的資格更新日期也並不能說明該成員下一次的資格更新日期一定是在什麼時候。因此,我們需要把成員資格的截止日期存儲起來。此外,聯盟還提供了終身成員資格。雖然我們可以用一個很遙遠的日期來表示這種情況,但使用NULL會更合適,因為“無值”在邏輯上正好對應於“永不失效”。 電子郵件地址。公開電子郵件地址可以使興趣相投的成員交流起來更方便。作為聯盟的秘書,在有了這些地址之後,就可以用電子郵件來向成員發送成員資格更新通知,而不用郵寄信件了。與到郵局寄信相比,這種做法既方便又省錢。你還可以利用電子郵件把每位成員的個人最新資料發送給他們,讓他們在必要時更新信息。 通信地址。當與那些沒有電子郵件(或者長期沒有回復你郵件)的成員進行聯系時,你會需要這條信息。我們將使用多個列來分別存儲街道地址、城市名、州名和郵政編碼。 電話號碼。與地址列相似,主要用於聯系成員。 特殊興趣關鍵字。聯盟的每位成員對美國歷史肯定都很感興趣,但他們的興趣卻可能集中於某些特定的歷史時期。此列便是用於記錄這些興趣。每位成員都可以利用這些信息來尋找與自己興趣相投的其他成員。(嚴格來講,建立一個獨立的表可能會更好些,表中的每一行都由一個關鍵字和相關成員的ID組成。這點有些復雜,我們暫不作處理。) INT。它表示該列用於存放整數(無小數部分的數值)。 UNSIGNED。它表示該值不能為負數。 NOT NULL。它表示該列必須要填值,這可以防止創建的成員沒有ID號。 AUTO_INCREMENT。它是MySQL的一個特殊屬性,表示該列存放的是序號。AUTO_INCREMENT的工作原理為:當往member表裡添加新記錄時,如果沒有為member_id列提供值,那麼MySQL將自動生成下一個編號,並將它賦給該列。如果你顯式地將NULL賦給該列,結果也是一樣的。AUTO_INCREMENT的這種特性使得為每一位成員分配一個唯一的ID變得很簡單,因為MySQL會替我們生成這些值。 你需要把考試成績記錄在表格的每一個格裡,這些格都要按學生姓名和考試日期進行排列(姓名由上往下排列,考試日期則由左往右排列)。這正是我剛才講過的兩組信息當中的一組,而它正好對應於score表裡的內容。 你要如何才能知道各日期所對應的考試類型呢?你或許會這樣做:在日期上方寫一個T或Q。於是,你又在表格的頂部把考試日期與考試類型關聯起來了。這正是我剛才講過的兩組信息當中的第二組,而它也正好對應於grade_``event表裡的內容。 成績冊由行和列構成,電子表格也是如此。這使得它們在概念和外觀上都很相似。 電子表格程序能夠執行計算,因此可以使用計算字段來統計每個學生的分數。將測驗分數和考試分數按不同權重來統計可能會有點棘手,但相信你能辦到。 考試成績與考試事件和學生都有關聯:只有當與考試成績相關聯的學生ID和考試事件ID分別在student``表和grade_event表裡存在時,才允許考試成績進入score表。 類似地,考勤記錄與學生有關聯:只有與考勤相關聯的學生ID在student表裡存在時,才允許考勤情況進入absence表。 我們已將這兩列的組合設置成了一個PRIMARY KEY。這樣可以確保我們不會重復記錄某位學生在某次考試或測驗的分數。請注意,只有event_id和student_id的組合才具有唯一性。在score表裡,這兩個ID值自身都不具備唯一性。對於每一個event_id值(每位學生有一個)都會有多個分數行與之對應;對於每一個student_id值(每次考試或測驗有一個)也會有多行記錄相對應。 每一個ID列都需要用FOREIGN KEY子句來定義約束條件。此子句的REFERENCES部分表明這個ID列是與哪個表的哪一列相對應。event_id列的約束條件為:該列裡的每一個值都必須與grade_event表裡的某個event_id值相匹配。類似地,score表裡的每一個student_id值都必須與student表裡的某個student_id值相匹配。 score表依賴於grade_event表和student表,因此在創建score表之前必須先創建其依賴的表。類似地,adsence表依賴於student表,因此在創建adsence表之前,student表必須已存在。 在刪除表時,必須把上面的順序顛倒過來。如果不先刪除score表,就無法刪除grade_event表;如果不先刪除score表和absence表,也無法刪除student表。 按日期排序(我們已經操作過多次)。 搜索特定日期或日期范圍。 從日期值裡提取各組成部分,如年、月或日。 計算兩個日期之間的時間差。 通過將一個日期加上或減去一個時間間隔,計算出另一個日期。 不用事先知道被統計列裡有些什麼值。 只需一個查詢語句。 因為只用一個查詢便能獲得所有的結果,所以可以對輸出進行排序。 FROM子句指定了多個表名,因為需要從多個表裡檢索信息: ON子句指定了表grade_``event和score的連接條件,即這兩個表的event_id值必須相互匹配: FROM子句現在包含了student表,因為這條查詢語句除了要用到grade_``event表和score表以外,還需要用到它。 在前一個查詢裡,student_id列不會產生二義性,因此在引用它時,既可以不限定表名(student_id),也可以限定表名(score.student_id)。但在這個查詢裡,因為score表和student表都有student_id列,所以肯定會出現二義性。於是,為了避免產生二義性,必須將它們分別限定為score.student_id和student.student_id。 ON子句裡多了一個查詢條件,用於指定score表裡的行與student表裡的行必須基於學生ID匹配在一起: 這個查詢會顯示出學生的姓名,而不顯示學生的ID。(如果想要兩者都顯示,只需要在輸出列的列表裡加上student.student_id即可。) 它需要引用同一個表中的兩個實例,因此我們必須為它創建兩個別名(p1和p2),並用它們來將表中的同名列區別開來。由於列已有別名,所以在為表指定別名時, AS關鍵字就是可選項了。 每位總統的記錄都與其本身相匹配,但這並不是我們想要的輸出結果。在確保參與比較的總統名字都不相同的情況下, WHERE子句便能防止出現“行與其本身相匹配”的情況。 把連接參數存儲在一個選項文件裡。 利用shell的歷史命令功能輸入重復命令。 利用shell別名或腳本定義一個mysql命令行快捷方式。 利用mysql的輸入行編輯功能。 利用復制和粘貼。 利用批處理運行mysql程序。