線程池是Mysql5.6的一個核心功能,對於服務器應用而言,無論是web應用服務還是DB服務,高並發請求始終是一個繞不開的話題。當有大量請求並發訪問時,一定伴隨著資源的不斷創建和釋放,導致資源利用率低,降低了服務質量。線程池是一種通用的技術,通過預先創建一定數量的線程,當有請求達到時,線程池分配一個線程提供服務,請求結束後,該線程又去服務其他請求。 通過這種方式,避免了線程和內存對象的頻繁創建和釋放,降低了服務端的並發度,減少了上下文切換和資源的競爭,提高資源利用效率。所有服務的線程池本質都是位了提高資源利用效率,並且實現方式也大體相同。本文主要說明Mysql線程池的實現原理。
在Mysql5.6出現以前,Mysql處理連接的方式是One-Connection-Per-Thread,即對於每一個數據庫連接,Mysql-Server都會創建一個獨立的線程服務,請求結束後,銷毀線程。再來一個連接請求,則再創建一個連接,結束後再進行銷毀。這種方式在高並發情況下,會導致線程的頻繁創建和釋放。當然,通過thread-cache,我們可以將線程緩存起來,以供下次使用,避免頻繁創建和釋放的問題,但是無法解決高連接數的問題。One-Connection-Per-Thread方式隨著連接數暴增,導致需要創建同樣多的服務線程,高並發線程意味著高的內存消耗,更多的上下文切換(cpu cache命中率降低)以及更多的資源競爭,導致服務出現抖動。相對於One-Thread-Per-Connection方式,一個線程對應一個連接,Thread-Pool實現方式中,線程處理的最小單位是statement(語句),一個線程可以處理多個連接的請求。這樣,在保證充分利用硬件資源情況下(合理設置線程池大小),可以避免瞬間連接數暴增導致的服務器抖動。
Mysql-Server同時支持3種連接管理方式,包括No-Threads,One-Thread-Per-Connection和Pool-Threads。No-Threads表示處理連接使用主線程處理,不額外創建線程,這種方式主要用於調試;One-Thread-Per-Connection是線程池出現以前最常用的方式,為每一個連接創建一個線程服務;Pool-Threads則是本文所討論的線程池方式。Mysql-Server通過一組函數指針來同時支持3種連接管理方式,對於特定的方式,將函數指針設置成特定的回調函數,連接管理方式通過thread_handling參數控制,代碼如下:
if (thread_handling <= SCHEDULER_ONE_THREAD_PER_CONNECTION)
one_thread_per_connection_scheduler(thread_scheduler,
&max_connections,
&connection_count);
else if (thread_handling == SCHEDULER_NO_THREADS)
one_thread_scheduler(thread_scheduler);
else
pool_of_threads_scheduler(thread_scheduler, &max_connections,&connection_count);
下面代碼展示了scheduler_functions模板和線程池對模板回調函數的實現,這個是多種連接管理的核心。
struct scheduler_functions
{
uint max_threads;
uint *connection_count;
ulong *max_connections;
bool (*init)(void);
bool (*init_new_connection_thread)(void);
void (*add_connection)(THD *thd);
void (*thd_wait_begin)(THD *thd, int wait_type);
void (*thd_wait_end)(THD *thd);
void (*post_kill_notification)(THD *thd);
bool (*end_thread)(THD *thd, bool cache_thread);
void (*end)(void);
};
static scheduler_functions tp_scheduler_functions=
{
0, // max_threads
NULL,
NULL,
tp_init, // init
NULL, // init_new_connection_thread
tp_add_connection, // add_connection
tp_wait_begin, // thd_wait_begin
tp_wait_end, // thd_wait_end
tp_post_kill_notification, // post_kill_notification
NULL, // end_thread
tp_end // end
};
上面描述了Mysql-Server如何管理連接,這節重點描述線程池的實現框架,以及關鍵接口。如圖1
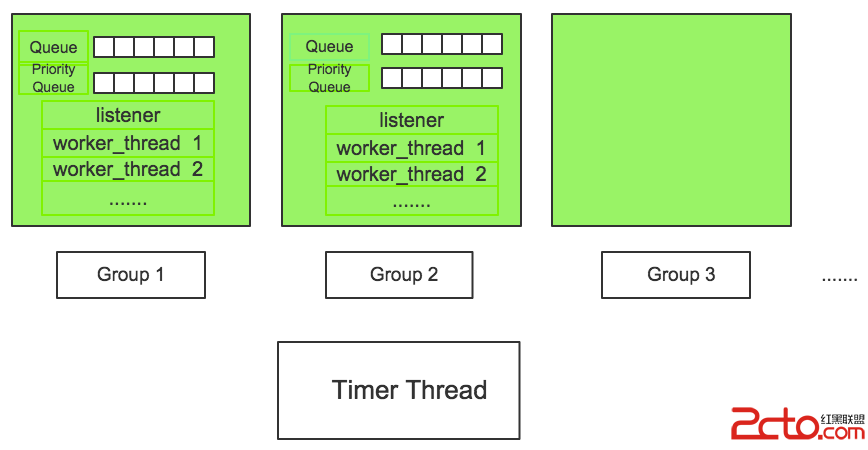
圖 1(線程池框架圖)
每一個綠色的方框代表一個group,group數目由thread_pool_size參數決定。每個group包含一個優先隊列和普通隊列,包含一個listener線程和若干個工作線程,listener線程和worker線程可以動態轉換,worker線程數目由工作負載決定,同時受到thread_pool_oversubscribe設置影響。此外,整個線程池有一個timer線程監控group,防止group“停滯”。
1. tp_add_connection[處理新連接]
1) 創建一個connection對象
2) 根據thread_id%group_count確定connection分配到哪個group
3) 將connection放進對應group的隊列
4) 如果當前活躍線程數為0,則創建一個工作線程
2. worker_main[工作線程]
1) 調用get_event獲取請求
2) 如果存在請求,則調用handle_event進行處理
3) 否則,表示隊列中已經沒有請求,退出結束。
3. get_event[獲取請求]
1) 獲取一個連接請求
2) 如果存在,則立即返回,結束
3) 若此時group內沒有listener,則線程轉換為listener線程,阻塞等待
4) 若存在listener,則將線程加入等待隊列頭部
5) 線程休眠指定的時間(thread_pool_idle_timeout)
6) 如果依然沒有被喚醒,是超時,則線程結束,結束退出
7) 否則,表示隊列裡有連接請求到來,跳轉1
備注:獲取連接請求前,會判斷當前的活躍線程數是否超過了
thread_pool_oversubscribe+1,若超過了,則將線程進入休眠狀態。
4. handle_event[處理請求]
1) 判斷連接是否進行登錄驗證,若沒有,則進行登錄驗證
2) 關聯thd實例信息
3) 獲取網絡數據包,分析請求
4) 調用do_command函數循環處理請求
5) 獲取thd實例的套接字句柄,判斷句柄是否在epoll的監聽列表中
6) 若沒有,調用epoll_ctl進行關聯
7) 結束
5.listener[監聽線程]
1) 調用epoll_wait進行對group關聯的套接字監聽,阻塞等待
2) 若請求到來,從阻塞中恢復
3) 根據連接的優先級別,確定是放入普通隊列還是優先隊列
4) 判斷隊列中任務是否為空
5) 若隊列為空,則listener轉換為worker線程
6) 若group內沒有活躍線程,則喚醒一個線程
備注:這裡epoll_wait監聽group內所有連接的套接字,然後將監聽到的連接
請求push到隊列,worker線程從隊列中獲取任務,然後執行。
6. timer_thread[監控線程]
1) 若沒有listener線程,並且最近沒有io_event事件
2) 則創建一個喚醒或創建一個工作線程
3) 若group最近一段時間沒有處理請求,並且隊列裡面有請求,則
4) 表示group已經stall,則喚醒或創建線程
5)檢查是否有連接超時
備注:timer線程通過調用check_stall判斷group是否處於stall狀態,通過調用timeout_check檢查客戶端連接是否超時。
7.tp_wait_begin[進入等待狀態流程]
1) active_thread_count減1,waiting_thread_count加1
2)設置connection->waiting= true
3) 若活躍線程數為0,並且任務隊列不為空,或者沒有監聽線程,則
4) 喚醒或創建一個線程
8.tp_wait_end[結束等待狀態流程]
1) 設置connection的waiting狀態為false
2) active_thread_count加1,waiting_thread_count減1
備注:
1)waiting_threads這個list裡面的線程是空閒線程,並非等待線程,所謂空閒線程是隨時可以處理任務的線程,而等待線程則是因為等待鎖,或等待io操作等無法處理任務的線程。
2)tp_wait_begin和tp_wait_end的主要作用是由於匯報狀態,即使更新active_thread_count和waiting_thread_count的信息。
9. tp_init/tp_end
分別調用thread_group_init和thread_group_close來初始化和銷毀線程池
連接池通常實現在Client端,是指應用(客戶端)創建預先創建一定的連接,利用這些連接服務於客戶端所有的DB請求。如果某一個時刻,空閒的連接數小於DB的請求數,則需要將請求排隊,等待空閒連接處理。通過連接池可以復用連接,避免連接的頻繁創建和釋放,從而減少請求的平均響應時間,並且在請求繁忙時,通過請求排隊,可以緩沖應用對DB的沖擊。線程池實現在server端,通過創建一定數量的線程服務DB請求,相對於one-conection-per-thread的一個線程服務一個連接的方式,線程池服務的最小單位是語句,即一個線程可以對應多個活躍的連接。通過線程池,可以將server端的服務線程數控制在一定的范圍,減少了系統資源的競爭和線程上下文切換帶來的消耗,同時也避免出現高連接數導致的高並發問題。連接池和線程池相輔相成,通過連接池可以減少連接的創建和釋放,提高請求的平均響應時間,並能很好地控制一個應用的DB連接數,但無法控制整個應用集群的連接數規模,從而導致高連接數,通過線程池則可以很好地應對高連接數,保證server端能提供穩定的服務。如圖2所示,每個web-server端維護了3個連接的連接池,對於連接池的每個連接實際不是獨占db-server的一個worker,而是可能與其他連接共享。這裡假設db-server只有3個group,每個group只有一個worker,每個worker處理了2個連接的請求。
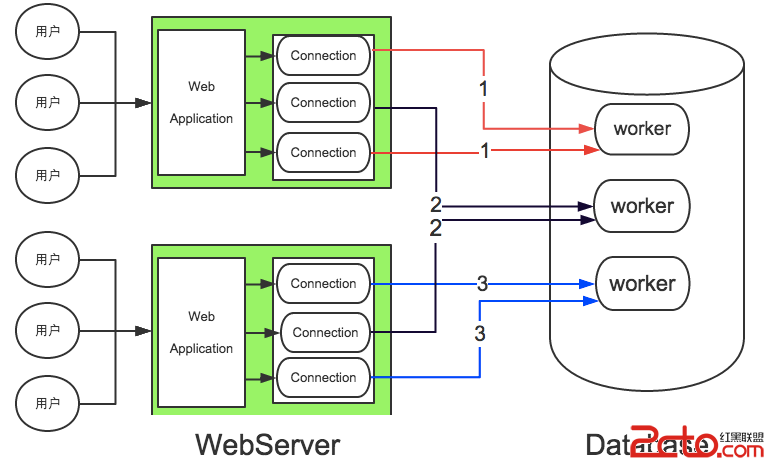
圖 2(連接池與線程池框架圖)
1.調度死鎖解決
引入線程池解決了多線程高並發的問題,但也帶來一個隱患。假設,A,B兩個事務被分配到不同的group中執行,A事務已經開始,並且持有鎖,但由於A所在的group比較繁忙,導致A執行一條語句後,不能立即獲得調度執行;而B事務依賴A事務釋放鎖資源,雖然B事務可以被調度起來,但由於無法獲得鎖資源,導致仍然需要等待,這就是所謂的調度死鎖。由於一個group會同時處理多個連接,但多個連接不是對等的。比如,有的連接是第一次發送請求;而有的連接對應的事務已經開啟,並且持有了部分鎖資源。為了減少鎖資源爭用,後者顯然應該比前者優先處理,以達到盡早釋放鎖資源的目的。因此在group裡面,可以添加一個優先級隊列,將已經持有鎖的連接,或者已經開啟的事務的連接發起的請求放入優先隊列,工作線程首先從優先隊列獲取任務執行。
2.大查詢處理
假設一種場景,某個group裡面的連接都是大查詢,那麼group裡面的工作線程數很快就會達到thread_pool_oversubscribe參數設置值,對於後續的連接請求,則會響應不及時(沒有更多的連接來處理),這時候group就發生了stall。通過前面分析知道,timer線程會定期檢查這種情況,並創建一個新的worker線程來處理請求。如果長查詢來源於業務請求,則此時所有group都面臨這種問題,此時主機可能會由於負載過大,導致hang住的情況。這種情況線程池本身無能為力,因為源頭可能是爛SQL並發,或者SQL沒有走對執行計劃導致,通過其他方法,比如SQL高低水位限流或者SQL過濾手段可以應急處理。但是,還有另外一種情況,就是dump任務。很多下游依賴於數據庫的原始數據,通常通過dump命令將數據拉到下游,而這種dump任務通常都是耗時比較長,所以也可以認為是大查詢。如果dump任務集中在一個group內,並導致其他正常業務請求無法立即響應,這個是不能容忍的,因為此時數據庫並沒有壓力,只是因為采用了線程池策略,才導致了請求響應不及時,為了解決這個問題,我們將group中處理dump任務的線程不計入thread_pool_oversubscribe累計值,避免上述問題。