轉載請注明: TheViper http://www.cnblogs.com/TheViper
部分翻譯自How to select the first/least/max row per group in SQL
一些常見的sql問題有著類似的解決方法,比如:查找每個程序最近的日志,查找每個商品分類中最受歡迎的商品,查找每個玩家的玩出的前5高分。。。這些問題可以被歸納為從各組中選出Top N.
fruits表
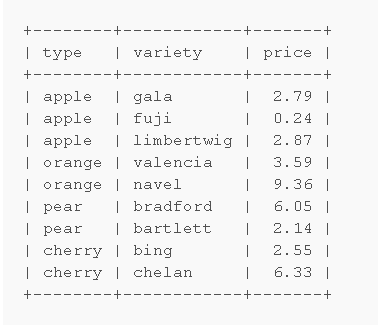
選取每個分類中價格最低的行
步驟:1.找到要求的所需的值price。2.填充其他字段
方法1.自連接
按type分組並選取價格最低的行
select type, min(price) as minprice from fruits group by type;

用自連接把剩下的行與上面的行合並,由於上面的查詢已經分好組了,這裡用子查詢把剩下的字段連接到沒分組的表中。
select f.type, f.variety, f.price from ( select type, min(price) as minprice from fruits group by type ) as x inner join fruits as f on f.type = x.type and f.price = x.minprice;

事實上此方法直接用group分組就可以了,不知道作者怎麼想的。
SELECT TYPE,variety, MIN(price) AS minprice FROM fruits GROUP BY TYPE;
方法2 相關子查詢
這種方法效率低點,但是很清晰。
select type, variety, price from fruits where price = (select min(price) from fruits as f where f.type = fruits.type);
選取每組的Top N行
select type, variety, price
from fruits
where price = (select min(price) from fruits as f where f.type = fruits.type)
or price = (select min(price) from fruits as f where f.type = fruits.type
and price > (select min(price) from fruits as f2 where f2.type = fruits.type));
可以看到,先選出價格最低的行,然後選出價格第二低的行,兩個用or連接。
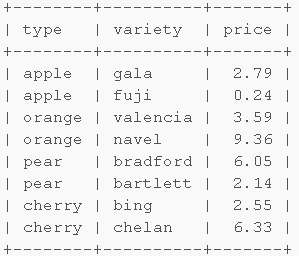
這個也可以用自連接寫,不過要復雜點。可以看到,如果需要選出top3,top4,...的時候,這種方法就會變得糟糕。
這裡有個更好的方法
select type, variety, price from fruits where ( select count(*) from fruits as f where f.type = fruits.type and f.price <= fruits.price ) <= 2;
這個可以理解成,遍歷外面的fruits各行,如果同一分類中,還有其他行<=該行且這樣的行的個數<=2,那該行符合要求,取出。
可以看到這種方法很優雅,因為改變n為其他值時都不需要重寫。但是這個方法和上個方法本質上是一樣的,都用到了子查詢。而一些查詢優化器在子查詢上做的不夠好。
使用union
如果(type, price)上有索引,並且索引可以過濾很多行,這時就可以對各個分類用limit.然後union把它們合並。
(select * from fruits where type = 'apple' order by price limit 2) union all (select * from fruits where type = 'orange' order by price limit 2) union all (select * from fruits where type = 'pear' order by price limit 2) union all (select * from fruits where type = 'cherry' order by price limit 2)
注意,這裡是UNION ALL,不是UNION。這樣做可以防止在返回結果前,對結果排序以去除重復的行。在該情景中不會出現重復的行,所以這裡要告訴數據庫不要排序去重。
關於union可以參見Using UNION to implement loose index scan in MySQL
使用用戶變量(user variables) 僅限mysql
上面union這種方法在行數較少且有索引可以用來排序時,是個好辦法。下面介紹的方法僅對mysql有效。介紹這種方法前請看我的另外一篇文章 how to number rows in MySQL。
文章簡單說來,就是為同一分類的行依次遞增編號

而下面介紹的方法正是基於此。
set @num := 0, @type := '';
select type, variety, price
from (
select type, variety, price,
@num := if(@type = type, @num + 1, 1) as row_number,
@type := type as dummy
from fruits
order by type, price
) as x where x.row_number <= 2;
子查詢創建臨時表,並向裡面填充row_number,dummy,這是一次操作。然後從中選出row_number<=2的行,這又是一次操作。盡管有兩次操作,但其復雜度仍然是O(n),只和表的大小相關,這比相關子查詢的復雜度O(n2)好很多。相關子查詢的n是分類個數,如果有很多分類的話,性能會很糟糕。
(完)