本文將主要講解了數據庫的一些基礎知識,介紹了MySql的存儲引擎,最後講了MySql常用的數據類型
1.1、數據庫概述
簡單地說:數據庫(Database或DB)是存儲、管理數據的容器; 嚴格地說:數據庫是“按照某種數據結構對數據進行組織、存儲和管理的容器”。 總結:數據永遠是數據庫的核心。1.2、關系數據庫管理系統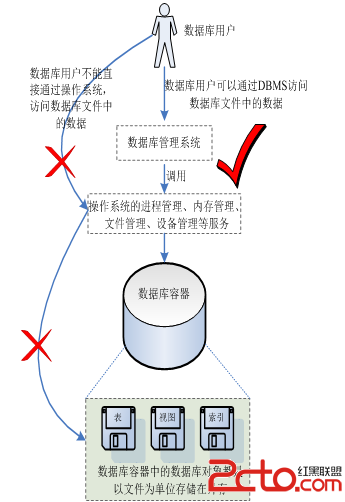
1.3、關系數據庫
關系數據庫,是建立在關系數據庫模型基礎上的數據庫,借助於集合代數等概念和方法來處理數據庫中的數據,同時也是一個被組織成一組擁有正式描述性的表格,該形式的表格作用的實質是裝載著數據項的特殊收集體,這些表格中的數據能以許多不同的方式被存取或重新召集而不需要重新組織數據庫表格。關系數據庫的定義造成元數據的一張表格或造成表格、列、范圍和約束的正式描述。每個表格(有時被稱為一個關系)包含用列表示的一個或更多的數據種類。 每行包含一個唯一的數據實體,這些數據是被列定義的種類。
基本特征
關系數據庫在一個給定的應用領域中,所有實體及實體之間聯系的集合構成一個關系數據庫。
關系數據庫的型與值關系數據庫的型稱為關系數據庫模式,是對關系數據庫的描述,若干域的定義,在這些域上定義的若干關系模式。
關系數據庫的值是這些關系模式在某一時刻對應的關系的集合,通常簡稱為關系數據庫。

1.4、結構化查詢語言SQL
結構化查詢語言SQL(Structured Query Language)是一種介於關系代數與關系演算之間的語言,其功能包括查詢、操縱、定義和控制四個方面,是一個通用的功能極強的關系數據庫標准語言。目前,SQL語言已被確定為關系數據庫系統的國際標准,被絕大多數商品化關系數據庫系統采用。在SQL語言中,指定要做什麼而不是怎麼做,不需要告訴SQL如何訪問數據庫,只要告訴SQL需要數據庫做什麼。可以在設計或運行時對數據控件使用SQL語句。
1.5、SQL數據庫的體系結構
SQL數據庫的體系結構基本上也是三級模式結構
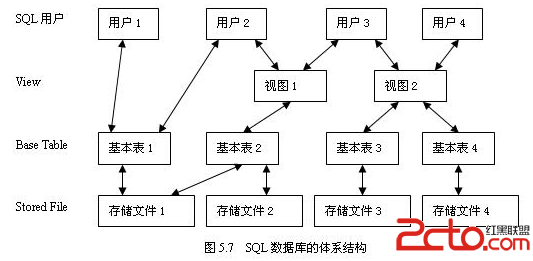
SQL術語與傳統的關系模型術語不同。在SQL中,外模式對應於視圖,模式對應於基本表,元組稱為行,屬性稱為列。內模式對應於存儲文件。SQL數據庫的體系結構具有如下特征:
SQL模式(Schema)是表和約束的集合。表(Table)是行(Row)的集合,每行是列(Column)的序列,每列對應一個數據項。 表可以是一個基本表,也可以是一個視圖。基本表是實際存儲在數據庫中的表。視圖是從基本表或其他視圖中導出的表,它本身不獨立存儲在數據庫中,也就是說數據庫中只存放視圖的定義而不存放視圖的數據,這些數據仍存放在導出視圖的基本表中,因此視圖是一個虛表。 一個基本表可以跨一個或多個存儲文件,一個存儲文件也可存放一個或多個基本表,一個表可以帶若干索引,索引也存放在存儲文件中。每個存儲文件與外部存儲器上一個物理文件對應,存儲文件的邏輯結構組成了關系數據庫的內模式。用戶可以用SQL語句對視圖和基本表進行查詢等操作。在用戶看來,視圖和基本表是一樣的,都是關系(即表格)。 SQL用戶可以是應用程序,也可以是終端用戶。SQL語句可嵌入在宿主語言的程序中使用,宿主語言有Fortran、Cobol、Pascal、PL/I、C和Ada等語言;SQL語言也能作為獨立的用戶接口,供交互環境下的終端用戶使用。1.6、SQL的組成
數據定義 這一部分也稱為“SQL DDL”,用於定義SQL模式、基本表、視圖和索引。 數據操縱 這一部分也稱為“SQL DML”。數據操縱分成數據查詢和數據更新兩類。其中數據更新又分成插入、刪除和修改三種操作。 數據控制 這一部分也稱為“SQL DCL”。數據控制包括對基本表和視圖的授權,完整性規則的描述,事務控制語句等。嵌入式SQL使用 這一部分內容涉及到SQL語句嵌入在宿主語言程序中的使用規則。
關系數據庫表是用於存儲和組織信息的數據結構,可以將表理解為由行和列組成的表格,類似於Excel的電子表格的形式。有的表簡單,有的表復雜,有的表根本不用來存儲任何長期的數據,有的表讀取時非常快,但是插入數據時去很差;而我們在實際開發過程中,就可能需要各種各樣的表,不同的表,就意味著存儲不同類型的數據,數據的處理上也會存在著差異,那麼。對於MySQL來說,它提供了很多種類型的存儲引擎,我們可以根據對數據處理的需求,選擇不同的存儲引擎,從而最大限度的利用MySQL強大的功能。
在mysql客戶端中,使用以下命令可以查看MySQL支持的引擎。
show engines;
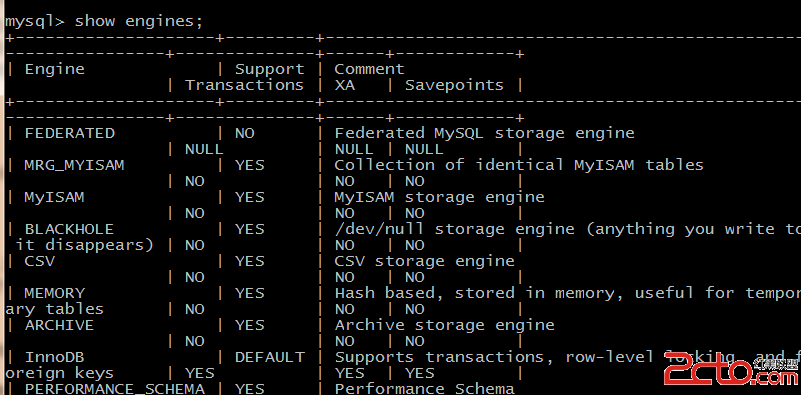
可以看到MySQL有多種存儲引擎:
MyISAM、InnoDB、MERGE、MEMORY(HEAP)、BDB(BerkeleyDB)、EXAMPLE、FEDERATED、ARCHIVE、CSV、BLACKHOLE。
平時用得最多的是MyISAM和InnoDB,下面主要來介紹這兩種。
2.1、MyISAM
MyISAM表是獨立於操作系統的,這說明可以輕松地將其從Windows服務器移植到Linux服務器;每當我們建立一個MyISAM引擎的表時,就會在本地磁盤上建立三個文件,文件名就是表明。例如,我建立了一個MyISAM引擎的tb_Demo表,那麼就會生成以下三個文件:
1.tb_demo.frm,存儲表定義;
2.tb_demo.MYD,存儲數據;
3.tb_demo.MYI,存儲索引。
MyISAM表無法處理事務,這就意味著有事務處理需求的表,不能使用MyISAM存儲引擎。MyISAM存儲引擎特別適合在以下幾種情況下使用:
1.選擇密集型的表。MyISAM存儲引擎在篩選大量數據時非常迅速,這是它最突出的優點。
2.插入密集型的表。MyISAM的並發插入特性允許同時選擇和插入數據。例如:MyISAM存儲引擎很適合管理郵件或Web服務器日志數據。
2.2、InnoDB
InnoDB是一個健壯的事務型存儲引擎,這種存儲引擎已經被很多互聯網公司使用,為用戶操作非常大的數據存儲提供了一個強大的解決方案。InnoDB是作為默認的存儲引擎。InnoDB還引入了行級鎖定和外鍵約束,在以下場合下,使用InnoDB是最理想的選擇:
1.更新密集的表。InnoDB存儲引擎特別適合處理多重並發的更新請求。
2.事務。InnoDB存儲引擎是支持事務的標准MySQL存儲引擎。
3.自動災難恢復。與其它存儲引擎不同,InnoDB表能夠自動從災難中恢復。
4.外鍵約束。MySQL支持外鍵的存儲引擎只有InnoDB。
5.支持自動增加列AUTO_INCREMENT屬性。
一般來說,如果需要事務支持,並且有較高的並發讀取頻率,InnoDB是不錯的選擇。
2.3、MEMORY
使用MySQL Memory存儲引擎的出發點是速度。為得到最快的響應時間,采用的邏輯存儲介質是系統內存。雖然在內存中存儲表數據確實會提供很高的性能,但當mysqld守護進程崩潰時,所有的Memory數據都會丟失。獲得速度的同時也帶來了一些缺陷。它要求存儲在Memory數據表裡的數據使用的是長度不變的格式,這意味著不能使用BLOB和TEXT這樣的長度可變的數據類型,VARCHAR是一種長度可變的類型,但因為它在MySQL內部當做長度固定不變的CHAR類型,所以可以使用。
一般在以下幾種情況下使用Memory存儲引擎:
1.目標數據較小,而且被非常頻繁地訪問。在內存中存放數據,所以會造成內存的使用,可以通過參數max_heap_table_size控制Memory表的大小,設置此參數,就可以限制Memory表的最大大小。
2.如果數據是臨時的,而且要求必須立即可用,那麼就可以存放在內存表中。
3.存儲在Memory表中的數據如果突然丟失,不會對應用服務產生實質的負面影響。
Memory同時支持散列索引和B樹索引。B樹索引的優於散列索引的是,可以使用部分查詢和通配查詢,也可以使用<、>和>=等操作符方便數據挖掘。散列索引進行“相等比較”非常快,但是對“范圍比較”的速度就慢多了,因此散列索引值適合使用在=和<>的操作符中,不適合在<或>操作符中,也同樣不適合用在order by子句中。
可以在表創建時利用USING子句指定要使用的版本。例如:
復制代碼 代碼如下:
create table users(
id smallint unsigned not null auto_increment,
username varchar(15) not null,
pwd varchar(15) not null,
index using hash (username),
primary key (id))engine=memory;
上述代碼創建了一個表,在username字段上使用了HASH散列索引。下面的代碼就創建一個表,使用BTREE索引。
復制代碼 代碼如下:
create table users(
id smallint unsigned not null auto_increment,
username varchar(15) not null,
pwd varchar(15) not null,
index using btree (username),
primary key (id))engine=memory;
2.4、MERGE
MERGE存儲引擎是一組MyISAM表的組合,這些MyISAM表結構必須完全相同,盡管其使用不如其它引擎突出,但是在某些情況下非常有用。說白了,Merge表就是幾個相同MyISAM表的聚合器;Merge表中並沒有數據,對Merge類型的表可以進行查詢、更新、刪除操作,這些操作實際上是對內部的MyISAM表進行操作。Merge存儲引擎的使用場景。
對於服務器日志這種信息,一般常用的存儲策略是將數據分成很多表,每個名稱與特定的時間端相關。例如:可以用12個相同的表來存儲服務器日志數據,每個表用對應各個月份的名字來命名。當有必要基於所有12個日志表的數據來生成報表,這意味著需要編寫並更新多表查詢,以反映這些表中的信息。與其編寫這些可能出現錯誤的查詢,不如將這些表合並起來使用一條查詢,之後再刪除Merge表,而不影響原來的數據,刪除Merge表只是刪除Merge表的定義,對內部的表沒有任何影響。
2.5、小結
InnoDB存儲引擎:用於事務處理應用程序,具有眾多特性
MyISAM存儲引擎:主要用於管理費事務表,它提供高速存儲和檢索,以及全文搜索能力
MEMORY存儲引擎:提供“內存中”表,MEMORY存儲引擎的所有數據都在內存中,數據的處理速度快,但安全性不高
字段和數據類型
雖然所有這些引擎都支持通用的數據類型,例如整型、實型和字符型等,但是,並不是所有的引擎都支持其它的字段類型,特別是BLOG(二進制大對象)或者TEXT文本類型。其它引擎也許僅支持有限的字符寬度和數據大小。
這些局限性可能直接影響到你可以存儲的數據,同時也可能會對你實施的搜索的類型或者你對那些信息創建的索引產生間接的影響。這些區別能夠影響你的應用程序的性能和功能,因為你必須要根據你要存儲的數據類型選擇對需要的存儲引擎的功能做出決策。
數據庫引擎中的鎖定功能決定了如何管理信息的訪問和更新。當數據庫中的一個對象為信息更新鎖定了,在更新完成之前,其它處理不能修改這個數據(在某些情況下還不允許讀這種數據)。
鎖定不僅影響許多不同的應用程序如何更新數據庫中的信息,而且還影響對那個數據的查詢。這是因為查詢可能要訪問正在被修改或者更新的數據。總的來說,這種延遲是很小的。大多數鎖定機制主要是為了防止多個處理更新同一個數據。由於向數據中插入信息和更新信息這兩種情況都需要鎖定,你可以想象,多個應用程序使用同一個數據庫可能會有很大的影響。
不同的存儲引擎在不同的對象級別支持鎖定,而且這些級別將影響可以同時訪問的信息。得到支持的級別有三種:表鎖定、塊鎖定和行鎖定。支持最多的是表鎖定,這種鎖定是在MyISAM中提供的。在數據更新時,它鎖定了整個表。這就防止了許多應用程序同時更新一個具體的表。這對應用很多的多用戶數據庫有很大的影響,因為它延遲了更新的過程。
頁級鎖定使用Berkeley DB引擎,並且根據上載的信息頁(8KB)鎖定數據。當在數據庫的很多地方進行更新的時候,這種鎖定不會出現什麼問題。但是,由於增加幾行信息就要鎖定數據結構的最後8KB,當需要增加大量的行,也別是大量的小型數據,就會帶來問題。
行級鎖定提供了最佳的並行訪問功能,一個表中只有一行數據被鎖定。這就意味著很多應用程序能夠更新同一個表中的不同行的數據,而不會引起鎖定的問題。只有InnoDB存儲引擎支持行級鎖定。
建立索引在搜索和恢復數據庫中的數據的時候能夠顯著提高性能。不同的存儲引擎提供不同的制作索引的技術。有些技術也許會更適合你存儲的數據類型。
有些存儲引擎根本就不支持索引,其原因可能是它們使用基本表索引(如MERGE引擎)或者是因為數據存儲的方式不允許索引(例如FEDERATED或者BLACKHOLE引擎)。
事務處理功能通過提供在向表中更新和插入信息期間的可靠性。這種可靠性是通過如下方法實現的,它允許你更新表中的數據,但僅當應用的應用程序的所有相關操作完全完成後才接受你對表的更改。例如,在會計處理中每一筆會計分錄處理將包括對借方科目和貸方科目數據的更改,你需要要使用事務處理功能保證對借方科目和貸方科目的數據更改都順利完成,才接受所做的修改。如果任一項操作失敗了,你都可以取消這個事務處理,這些修改就不存在了。如果這個事務處理過程完成了,我們可以通過允許這個修改來確認這個操作。
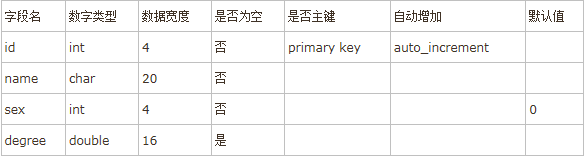
1.char(n)和varchar(n)中括號中n代表字符的個數,並不代表字節個數,所以當使用了中文的時候(UTF8)意味著可以插入m個中文,但是實際會占用m*3個字節。
2.同時char和varchar最大的區別就在於char不管實際value都會占用n個字符的空間,而varchar只會占用實際字符應該占用的空間+1,並且實際空間+1<=n。
3.超過char和varchar的n設置後,字符串會被截斷。
4.char的上限為255字節,varchar的上限65535字節,text的上限為65535。
5.char在存儲的時候會截斷尾部的空格,varchar和text不會。
6.varchar會使用1-3個字節來存儲長度,text不會。
數值數據類型
整型
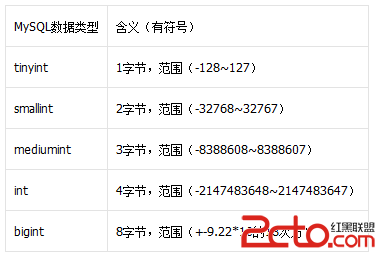
上面定義的都是有符號的,當然了,也可以加上unsigned關鍵字,定義成無符號的類型,那麼對應的取值范圍就要翻翻了,比如:
tinyint unsigned的取值范圍為0~255。
浮點型

二進制數據類型
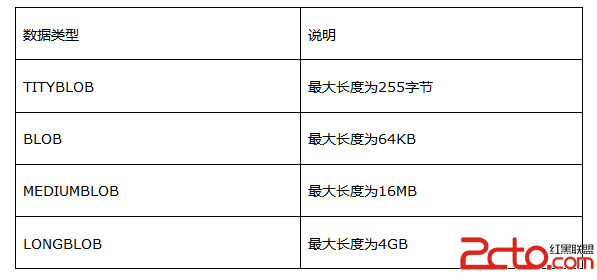
二進制類型可存儲任何數據,如文字、圖像、多媒體等。具體類型描述如下: