所謂索引就是為特定的mysql字段進行一些特定的算法排序,比如二叉樹的算法和哈希算法,哈希算法是通過建立特征值,然後根據特征值來快速查找。而用的最多,並且是mysql默認的就是二叉樹算法 BTREE,通過BTREE算法建立索引的字段,比如掃描20行就能得到未使用BTREE前掃描了2^20行的結果,具體的實現方式後續本博客會出一個算法專題裡面會有具體的分析討論;
Explain優化查詢檢測
EXPLAIN可以幫助開發人員分析SQL問題,explain顯示了mysql如何使用索引來處理select語句以及連接表,可以幫助選擇更好的索引和寫出更優化的查詢語句.
使用方法,在select語句前加上Explain就可以了:
Explain select * from blog where false;
mysql在執行一條查詢之前,會對發出的每條SQL進行分析,決定是否使用索引或全表掃描如果發送一條select * from blog where falseMysql是不會執行查詢操作的,因為經過SQL分析器的分析後MySQL已經清楚不會有任何語句符合操作;
Example
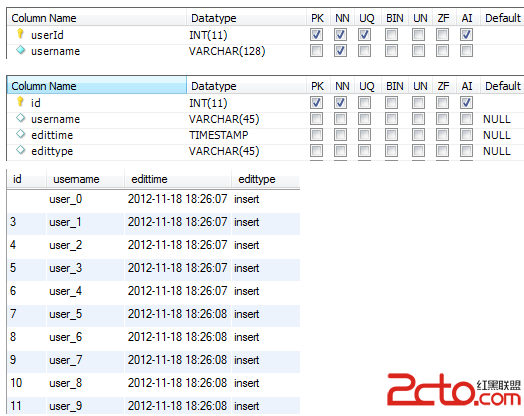
- mysql> EXPLAIN SELECT `birday` FROM `user` WHERE `birthday` < "1990/2/2";
- -- 結果:
- id: 1
- select_type: SIMPLE -- 查詢類型簡單查詢,聯合查詢,子查詢)
- table: user -- 顯示這一行的數據是關於哪張表的
- type: range -- 區間索引在小於1990/2/2區間的數據),這是重要的列,顯示連接使用了何種類型。從最好到最差的連接類型為system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL,const代表一次就命中,ALL代表掃描了全表才確定結果。一般來說,得保證查詢至少達到range級別,最好能達到ref。
- possible_keys: birthday -- 指出MySQL能使用哪個索引在該表中找到行。如果是空的,沒有相關的索引。這時要提高性能,可通過檢驗WHERE子句,看是否引用某些字段,或者檢查字段不是適合索引。
- key: birthday -- 實際使用到的索引。如果為NULL,則沒有使用索引。如果為primary的話,表示使用了主鍵。
- key_len: 4 -- 最長的索引寬度。如果鍵是NULL,長度就是NULL。在不損失精確性的情況下,長度越短越好
- ref: const -- 顯示哪個字段或常數與key一起被使用。
- rows: 1 -- 這個數表示mysql要遍歷多少數據才能找到,在innodb上是不准確的。
- Extra: Using where; Using index -- 執行狀態說明,這裡可以看到的壞的例子是Using temporary和Using
select_type
Extra與type詳細說明
其中type: