日志君導讀:
一個成熟的數據庫架構並不是一開始設計就具備高可用、高伸縮等特性的,它是隨著用戶量的增加,基礎架構才逐漸完善。
max_connections = 151 #同時處理最大連接數,推薦設置最大連接數是上限連接數的80%左右 sort_buffer_size = 2M #查詢排序時緩沖區大小,只對order by和group by起作用,可增大此值為16M query_cache_limit = 1M #查詢緩存限制,只有1M以下查詢結果才會被緩存,以免結果數據較大把緩存池覆蓋 query_cache_size = 16M #查看緩沖區大小,用於緩存SELECT查詢結果,下一次有同樣SELECT查詢將直接從緩存池返回結果,可適當成倍增加此值 open_files_limit = 1024 #打開文件數限制,如果show global status like 'open_files'查看的值等於或者大於open_files_limit值時,程序會無法連接數據庫或卡死
key_buffer_size = 16M #索引緩存區大小,一般設置物理內存的30-40% read_buffer_size = 128K #讀操作緩沖區大小,推薦設置16M或32M
innodb_buffer_pool_size = 128M #索引和數據緩沖區大小,一般設置物理內存的60%-70% innodb_buffer_pool_instances = 1 #緩沖池實例個數,推薦設置4個或8個 innodb_flush_log_at_trx_commit = 1 #關鍵參數,0代表大約每秒寫入到日志並同步到磁盤,數據庫故障會丟失1秒左右事務數據。1為每執行一條SQL後寫入到日志並同步到磁盤,I/O開銷大,執行完SQL要等待日志讀寫,效率低。2代表只把日志寫入到系統緩存區,再每秒同步到磁盤,效率很高,如果服務器故障,才會丟失事務數據。對數據安全性要求不是很高的推薦設置2,性能高,修改後效果明顯。 innodb_file_per_table = OFF #默認是共享表空間,共享表空間idbdata文件不斷增大,影響一定的I/O性能。推薦開啟獨立表空間模式,每個表的索引和數據都存在自己獨立的表空間中,可以實現單表在不同數據庫中移動。 innodb_log_buffer_size = 8M #日志緩沖區大小,由於日志最長每秒鐘刷新一次,所以一般不用超過16M

QPS,Queries Per Second:每秒查詢數,一台數據庫每秒能夠處理的查詢次數;
TPS,Transactions Per Second:每秒處理事務數。
通過show status查看運行狀態,會有300多條狀態信息記錄,其中有幾個值幫可以我們計算出QPS和TPS,如下:
Uptime:服務器已經運行的實際,單位秒
Questions:已經發送給數據庫查詢數
Com_select:查詢次數,實際操作數據庫的
Com_insert:插入次數
Com_delete:刪除次數
Com_update:更新次數
Com_commit:事務次數
Com_rollback:回滾次數
那麼,計算方法來了,基於Questions計算出QPS:
QPS = Questions / Uptime
mysql> show global status like 'Questions'; mysql> show global status like 'Uptime';
基於Com_commit和Com_rollback計算出TPS:
mysql> show global status like 'Com_commit'; mysql> show global status like 'Com_rollback'; mysql> show global status like 'Uptime'; TPS = (Com_commit + Com_rollback) / Uptime
另一計算方式:基於Com_select、Com_insert、Com_delete、Com_update計算出QPS。
mysql>mysql> show global status where Variable_name in('com_select','com_insert','com_delete','com_update'); 等待1秒再執行,獲取間隔差值,第二次每個變量值減去第一次對應的變量值,就是QPS
TPS計算方法:
mysql>mysql> show global status where Variable_name in('com_insert','com_delete','com_update'); 計算TPS,就不算查詢操作了,計算出插入、刪除、更新四個值即可。 經網友對這兩個計算方式的測試得出,當數據庫中myisam表比較多時,使用Questions計算比較准確。當數據庫中innodb表比較多時,則以Com_*計算比較准確。
MySQL開啟慢查詢日志,分析出哪條SQL語句比較慢,使用set設置變量,重啟服務失效,可以在my.cnf添加參數永久生效。
mysql> set global slow-query-log=on #開啟慢查詢功能 mysql> set global slow_query_log_file='/var/log/mysql/mysql-slow.log'; #指定慢查詢日志文件位置 mysql> set global log_queries_not_using_indexes=on; #記錄沒有使用索引的查詢 mysql> set global long_query_time=1; #只記錄處理時間1s以上的慢查詢
分析慢查詢日志,可以使用MySQL自帶的mysqldumpslow工具,分析的日志較為簡單。
# mysqldumpslow -t 3 /var/log/mysql/mysql-slow.log #查看最慢的前三個查詢
也可以使用percona公司的pt-query-digest工具,日志分析功能全面,可分析slow log、binlog、general log。
分析慢查詢日志:pt-query-digest /var/log/mysql/mysql-slow.log
分析binlog日志:mysqlbinlog mysql-bin.000001 >mysql-bin.000001.sql
pt-query-digest –type=binlog mysql-bin.000001.sql
分析普通日志:pt-query-digest –type=genlog localhost.log
備份數據庫是最基本的工作,也是最重要的,否則後果很嚴重,你懂得!但由於數據庫比較大,上百G,往往備份都很耗費時間,所以就該選擇一個效率高的備份策略,對於數據量大的數據庫,一般都采用增量備份。常用的備份工具有mysqldump、mysqlhotcopy、xtrabackup等,mysqldump比較適用於小的數據庫,因為是邏輯備份,所以備份和恢復耗時都比較長。mysqlhotcopy和xtrabackup是物理備份,備份和恢復速度快,不影響數據庫服務情況下進行熱拷貝,建議使用xtrabackup,支持增量備份。
Xtrabackup備份工具使用博文:http://lizhenliang.blog.51cto.com/7876557/1612800
有時候MySQL服務器突然斷電、異常關閉,會導致表損壞,無法讀取表數據。這時就可以用到MySQL自帶的兩個工具進行修復,myisamchk和mysqlcheck。
myisamchk:只能修復myisam表,需要停止數據庫
常用參數:
-f –force 強制修復,覆蓋老的臨時文件,一般不使用
-r –recover 恢復模式
-q –quik 快速恢復
-a –analyze 分析表
-o –safe-recover 老的恢復模式,如果-r無法修復,可以使用此參數試試
-F –fast 只檢查沒有正常關閉的表
快速修復weibo數據庫:
# cd /var/lib/mysql/weibo
# myisamchk -r -q *.MYI
mysqlcheck:myisam和innodb表都可以用,不需要停止數據庫,如修復單個表,可在數據庫後面添加表名,以空格分割。
常用參數:
-a –all-databases 檢查所有的庫
-r –repair 修復表
-c –check 檢查表,默認選項
-a –analyze 分析表
-o –optimize 優化表
-q –quik 最快檢查或修復表
-F –fast 只檢查沒有正常關閉的表
快速修復weibo數據庫:
mysqlcheck -r -q -uroot -p123 weibo
查看CPU性能
參數-P是顯示CPU數,ALL為所有,也可以只顯示第幾顆

查看I/O性能

參數-m是以M單位顯示,默認K
%util:當達到100%時,說明I/O很忙。
await:請求在隊列中等待時間,直接影響read時間。
I/O極限:IOPS(r/s+w/s),一般在1200左右。(IOPS,每秒進行讀寫(I/O)操作次數)
I/O帶寬:在順序讀寫模式下SAS硬盤理論值在300M/s左右,SSD硬盤理論值在600M/s左右。
以上是本人使用MySQL三年來總結的一些主要優化方案,能力有限,有些不太全面,但這些基本能夠滿足中小型企業數據庫需求。由於關系型數據庫初衷設計限制,一些BAT公司海量數據放到關系型數據庫中,在海量數據查詢和分析方面已經達不到更好的性能。因此NoSQL火起來了,非關系型數據庫,大數據量,具有高性能,同時也彌補了關系型數據庫某方面不足,漸漸大多數公司已經將部分業務數據庫存放到NoSQL中,如MongoDB、HBase等。數據存儲方面采用分布式文件系統,如HDFS、GFS等。海量數據計算分析采用Hadoop、Spark、Storm等。這些都是與運維相關的前沿技術,也是在存儲方面主要學習對象,小伙伴們共同加油吧!哪位博友有更好的優化方案,歡迎交流哦。
日志君導讀:
一個成熟的數據庫架構並不是一開始設計就具備高可用、高伸縮等特性的,它是隨著用戶量的增加,基礎架構才逐漸完善。
作者:zhenliang8,本文轉自51CTO博客,點擊原文閱讀查看網頁版文章。
本博文主要談MySQL數據庫發展周期中所面臨的問題及優化方案,暫且拋開前端應用不說,大致分為以下五個階段:
項目立項後,開發部根據產品部需求開發項目,開發工程師工作其中一部分就是對表結構設計。對於數據庫來說,這點很重要,如果設計不當,會直接影響訪問速度和用戶體驗。影響的因素很多,比如慢查詢、低效的查詢語句、沒有適當建立索引、數據庫堵塞(死鎖)等。當然,有測試工程師的團隊,會做壓力測試,找bug。對於沒有測試工程師的團隊來說,大多數開發工程師初期不會太多考慮數據庫設計是否合理,而是盡快完成功能實現和交付,等項目有一定訪問量後,隱藏的問題就會暴露,這時再去修改就不是這麼容易的事了。
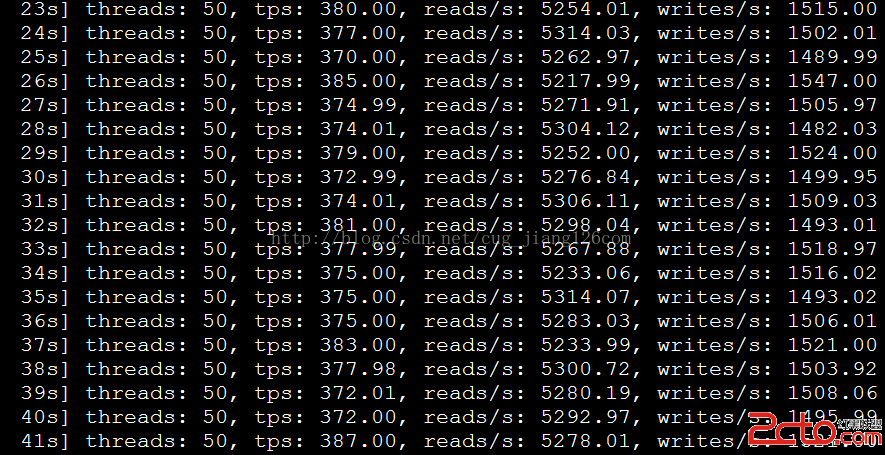
該運維工程師出場了,項目初期訪問量不會很大,所以單台部署足以應對在1500左右的QPS(每秒查詢率)。考慮到高可用性,可采用MySQL主從復制+Keepalived做雙擊熱備,常見集群軟件有Keepalived、Heartbeat。
雙機熱備博文:http://lizhenliang.blog.51cto.com/7876557/1362313
如果將MySQL部署到普通的X86服務器上,在不經過任何優化情況下,MySQL理論值正常可以處理2000左右QPS,經過優化後,有可能會提升到2500左右QPS,否則,訪問量當達到1500左右並發連接時,數據庫處理性能就會變慢,而且硬件資源還很富裕,這時就該考慮軟件問題了。那麼怎樣讓數據庫最大化發揮性能呢?一方面可以單台運行多個MySQL實例讓服務器性能發揮到最大化,另一方面是對數據庫進行優化,往往操作系統和數據庫默認配置都比較保守,會對數據庫發揮有一定限制,可對這些配置進行適當的調整,盡可能的處理更多連接數。
具體優化有以下三個層面:
MySQL常用有兩種存儲引擎,一個是MyISAM,不支持事務處理,讀性能處理快,表級別鎖。另一個是InnoDB,支持事務處理(ACID),設計目標是為處理大容量數據發揮最大化性能,行級別鎖。
表鎖:開銷小,鎖定粒度大,發生死鎖概率高,相對並發也低。
行鎖:開銷大,鎖定粒度小,發生死鎖概率低,相對並發也高。
為什麼會出現表鎖和行鎖呢?主要是為了保證數據的完整性,舉個例子,一個用戶在操作一張表,其他用戶也想操作這張表,那麼就要等第一個用戶操作完,其他用戶才能操作,表鎖和行鎖就是這個作用。否則多個用戶同時操作一張表,肯定會數據產生沖突或者異常。
根據以上看來,使用InnoDB存儲引擎是最好的選擇,也是MySQL5.5以後版本中默認存儲引擎。每個存儲引擎相關聯參數比較多,以下列出主要影響數據庫性能的參數。
公共參數默認值:
max_connections = 151 #同時處理最大連接數,推薦設置最大連接數是上限連接數的80%左右 sort_buffer_size = 2M #查詢排序時緩沖區大小,只對order by和group by起作用,可增大此值為16M query_cache_limit = 1M #查詢緩存限制,只有1M以下查詢結果才會被緩存,以免結果數據較大把緩存池覆蓋 query_cache_size = 16M #查看緩沖區大小,用於緩存SELECT查詢結果,下一次有同樣SELECT查詢將直接從緩存池返回結果,可適當成倍增加此值 open_files_limit = 1024 #打開文件數限制,如果show global status like 'open_files'查看的值等於或者大於open_files_limit值時,程序會無法連接數據庫或卡死
MyISAM參數默認值:
key_buffer_size = 16M #索引緩存區大小,一般設置物理內存的30-40% read_buffer_size = 128K #讀操作緩沖區大小,推薦設置16M或32M
InnoDB參數默認值:
innodb_buffer_pool_size = 128M #索引和數據緩沖區大小,一般設置物理內存的60%-70% innodb_buffer_pool_instances = 1 #緩沖池實例個數,推薦設置4個或8個 innodb_flush_log_at_trx_commit = 1 #關鍵參數,0代表大約每秒寫入到日志並同步到磁盤,數據庫故障會丟失1秒左右事務數據。1為每執行一條SQL後寫入到日志並同步到磁盤,I/O開銷大,執行完SQL要等待日志讀寫,效率低。2代表只把日志寫入到系統緩存區,再每秒同步到磁盤,效率很高,如果服務器故障,才會丟失事務數據。對數據安全性要求不是很高的推薦設置2,性能高,修改後效果明顯。 innodb_file_per_table = OFF #默認是共享表空間,共享表空間idbdata文件不斷增大,影響一定的I/O性能。推薦開啟獨立表空間模式,每個表的索引和數據都存在自己獨立的表空間中,可以實現單表在不同數據庫中移動。 innodb_log_buffer_size = 8M #日志緩沖區大小,由於日志最長每秒鐘刷新一次,所以一般不用超過16M
大多數MySQL都部署在linux系統上,所以操作系統的一些參數也會影響到MySQL性能,以下對linux內核進行適當優化。
加大物理內存,提高文件系統性能。linux內核會從內存中分配出緩存區(系統緩存和數據緩存)來存放熱數據,通過文件系統延遲寫入機制,等滿足條件時(如緩存區大小到達一定百分比或者執行sync命令)才會同步到磁盤。也就是說物理內存越大,分配緩存區越大,緩存數據越多。當然,服務器故障會丟失一定的緩存數據。
SSD硬盤代替SAS硬盤,將RAID級別調整為RAID1+0,相對於RAID1和RAID5有更好的讀寫性能(IOPS),畢竟數據庫的壓力主要來自磁盤I/O方面。
隨著業務量越來越大,單台數據庫服務器性能已無法滿足業務需求,該考慮加機器了,該做集群了~~~。主要思想是分解單台數據庫負載,突破磁盤I/O性能,熱數據存放緩存中,降低磁盤I/O訪問頻率。
因為生產環境中,數據庫大多都是讀操作,所以部署一主多從架構,主數據庫負責寫操作,並做雙擊熱備,多台從數據庫做負載均衡,負責讀操作,主流的負載均衡器有LVS、HAProxy、Nginx。怎麼來實現讀寫分離呢?大多數企業是在代碼層面實現讀寫分離,效率比較高。另一個種方式通過代理程序實現讀寫分離,企業中應用較少,常見代理程序有MySQL Proxy、Amoeba。在這樣數據庫集群架構中,大大增加數據庫高並發能力,解決單台性能瓶頸問題。如果從數據庫一台從庫能處理2000 QPS,那麼5台就能處理1w QPS,數據庫橫向擴展性也很容易。
有時,面對大量寫操作的應用時,單台寫性能達不到業務需求。如果做雙主,就會遇到數據庫數據不一致現象,產生這個原因是在應用程序不同的用戶會有可能操作兩台數據庫,同時的更新操作造成兩台數據庫數據庫數據發生沖突或者不一致。在單庫時MySQL利用存儲引擎機制表鎖和行鎖來保證數據完整性,怎樣在多台主庫時解決這個問題呢?有一套基於perl語言開發的主從復制管理工具,叫MySQL-MMM(Master-Master replication managerfor Mysql,Mysql主主復制管理器),這個工具最大的優點是在同一時間只提供一台數據庫寫操作,有效保證數據一致性。
給數據庫增加緩存系統,把熱數據緩存到內存中,如果內存緩存中有要請求的數據就不再去數據庫中返回結果,提高讀性能。緩存實現有本地緩存和分布式緩存,本地緩存是將數據緩存到本地服務器內存中或者文件中,速度快。分布式可以緩存海量數據,擴展容易,主流的分布式緩存系統有memcached、redis,memcached性能穩定,數據緩存在內存中,速度很快,QPS可達8w左右。如果想數據持久化那就用redis,性能不低於memcached。
工作過程:
分庫是根據業務不同把相關的表切分到不同的數據庫中,比如web、bbs、blog等庫。如果業務量很大,還可將切分後的庫做主從架構,進一步避免單個庫壓力過大。
數據量的日劇增加,數據庫中某個表有幾百萬條數據,導致查詢和插入耗時太長,怎麼能解決單表壓力呢?你就該考慮是否把這個表拆分成多個小表,來減輕單個表的壓力,提高處理效率,此方式稱為分表。
分表技術比較麻煩,要修改程序代碼裡的SQL語句,還要手動去創建其他表,也可以用merge存儲引擎實現分表,相對簡單許多。分表後,程序是對一個總表進行操作,這個總表不存放數據,只有一些分表的關系,以及更新數據的方式,總表會根據不同的查詢,將壓力分到不同的小表上,因此提高並發能力和磁盤I/O性能。
分表分為垂直拆分和水平拆分:
垂直拆分:把原來的一個很多字段的表拆分多個表,解決表的寬度問題。你可以把不常用的字段單獨放到一個表中,也可以把大字段獨立放一個表中,或者把關聯密切的字段放一個表中。
水平拆分:把原來一個表拆分成多個表,每個表的結構都一樣,解決單表數據量大的問題。
分區就是把一張表的數據分成多個區塊,這些區塊可以在一個磁盤上,也可以在不同的磁盤上,分區後,表面上還是一張表,但數據散列在多個位置,這樣一來,多塊硬盤同時處理不同的請求,從而提高磁盤I/O讀寫性能,實現比較簡單。
注:增加緩存、分庫、分表和分區主要由程序猿來實現。
數據庫維護是運維工程師或者DBA主要工作,包括性能監控、性能分析、性能調優、數據庫備份和恢復等。
QPS,Queries Per Second:每秒查詢數,一台數據庫每秒能夠處理的查詢次數;
TPS,Transactions Per Second:每秒處理事務數。
通過show status查看運行狀態,會有300多條狀態信息記錄,其中有幾個值幫可以我們計算出QPS和TPS,如下:
Uptime:服務器已經運行的實際,單位秒
Questions:已經發送給數據庫查詢數
Com_select:查詢次數,實際操作數據庫的
Com_insert:插入次數
Com_delete:刪除次數
Com_update:更新次數
Com_commit:事務次數
Com_rollback:回滾次數
那麼,計算方法來了,基於Questions計算出QPS:
QPS = Questions / Uptime
mysql> show global status like 'Questions'; mysql> show global status like 'Uptime';
基於Com_commit和Com_rollback計算出TPS:
mysql> show global status like 'Com_commit'; mysql> show global status like 'Com_rollback'; mysql> show global status like 'Uptime'; TPS = (Com_commit + Com_rollback) / Uptime
另一計算方式:基於Com_select、Com_insert、Com_delete、Com_update計算出QPS。
mysql>mysql> show global status where Variable_name in('com_select','com_insert','com_delete','com_update'); 等待1秒再執行,獲取間隔差值,第二次每個變量值減去第一次對應的變量值,就是QPS
TPS計算方法:
mysql>mysql> show global status where Variable_name in('com_insert','com_delete','com_update'); 計算TPS,就不算查詢操作了,計算出插入、刪除、更新四個值即可。 經網友對這兩個計算方式的測試得出,當數據庫中myisam表比較多時,使用Questions計算比較准確。當數據庫中innodb表比較多時,則以Com_*計算比較准確。
MySQL開啟慢查詢日志,分析出哪條SQL語句比較慢,使用set設置變量,重啟服務失效,可以在my.cnf添加參數永久生效。
mysql> set global slow-query-log=on #開啟慢查詢功能 mysql> set global slow_query_log_file='/var/log/mysql/mysql-slow.log'; #指定慢查詢日志文件位置 mysql> set global log_queries_not_using_indexes=on; #記錄沒有使用索引的查詢 mysql> set global long_query_time=1; #只記錄處理時間1s以上的慢查詢
分析慢查詢日志,可以使用MySQL自帶的mysqldumpslow工具,分析的日志較為簡單。
# mysqldumpslow -t 3 /var/log/mysql/mysql-slow.log #查看最慢的前三個查詢
也可以使用percona公司的pt-query-digest工具,日志分析功能全面,可分析slow log、binlog、general log。
分析慢查詢日志:pt-query-digest /var/log/mysql/mysql-slow.log
分析binlog日志:mysqlbinlog mysql-bin.000001 >mysql-bin.000001.sql
pt-query-digest –type=binlog mysql-bin.000001.sql
分析普通日志:pt-query-digest –type=genlog localhost.log
備份數據庫是最基本的工作,也是最重要的,否則後果很嚴重,你懂得!但由於數據庫比較大,上百G,往往備份都很耗費時間,所以就該選擇一個效率高的備份策略,對於數據量大的數據庫,一般都采用增量備份。常用的備份工具有mysqldump、mysqlhotcopy、xtrabackup等,mysqldump比較適用於小的數據庫,因為是邏輯備份,所以備份和恢復耗時都比較長。mysqlhotcopy和xtrabackup是物理備份,備份和恢復速度快,不影響數據庫服務情況下進行熱拷貝,建議使用xtrabackup,支持增量備份。
Xtrabackup備份工具使用博文:http://lizhenliang.blog.51cto.com/7876557/1612800
有時候MySQL服務器突然斷電、異常關閉,會導致表損壞,無法讀取表數據。這時就可以用到MySQL自帶的兩個工具進行修復,myisamchk和mysqlcheck。
myisamchk:只能修復myisam表,需要停止數據庫
常用參數:
-f –force 強制修復,覆蓋老的臨時文件,一般不使用
-r –recover 恢復模式
-q –quik 快速恢復
-a –analyze 分析表
-o –safe-recover 老的恢復模式,如果-r無法修復,可以使用此參數試試
-F –fast 只檢查沒有正常關閉的表
快速修復weibo數據庫:
# cd /var/lib/mysql/weibo
# myisamchk -r -q *.MYI
mysqlcheck:myisam和innodb表都可以用,不需要停止數據庫,如修復單個表,可在數據庫後面添加表名,以空格分割。
常用參數:
-a –all-databases 檢查所有的庫
-r –repair 修復表
-c –check 檢查表,默認選項
-a –analyze 分析表
-o –optimize 優化表
-q –quik 最快檢查或修復表
-F –fast 只檢查沒有正常關閉的表
快速修復weibo數據庫:
mysqlcheck -r -q -uroot -p123 weibo
查看CPU性能
參數-P是顯示CPU數,ALL為所有,也可以只顯示第幾顆
查看I/O性能
參數-m是以M單位顯示,默認K
%util:當達到100%時,說明I/O很忙。
await:請求在隊列中等待時間,直接影響read時間。
I/O極限:IOPS(r/s+w/s),一般在1200左右。(IOPS,每秒進行讀寫(I/O)操作次數)
I/O帶寬:在順序讀寫模式下SAS硬盤理論值在300M/s左右,SSD硬盤理論值在600M/s左右。
以上是本人使用MySQL三年來總結的一些主要優化方案,能力有限,有些不太全面,但這些基本能夠滿足中小型企業數據庫需求。由於關系型數據庫初衷設計限制,一些BAT公司海量數據放到關系型數據庫中,在海量數據查詢和分析方面已經達不到更好的性能。因此NoSQL火起來了,非關系型數據庫,大數據量,具有高性能,同時也彌補了關系型數據庫某方面不足,漸漸大多數公司已經將部分業務數據庫存放到NoSQL中,如MongoDB、HBase等。數據存儲方面采用分布式文件系統,如HDFS、GFS等。海量數據計算分析采用Hadoop、Spark、Storm等。這些都是與運維相關的前沿技術,也是在存儲方面主要學習對象,小伙伴們共同加油吧!哪位博友有更好的優化方案,歡迎交流哦。