在數據庫設計過程中,用戶可能會經常遇到這樣的問題:1.表裡面的字段到底該設置多長合適?2.是否應該把所有表都按照第三范式來設計?
表的數據類型參見鏈接:
http://blog.csdn.net/pursuing0my0dream/article/details/44729707
在mysql中,我們可以使用函數 procedure analyse()對數據庫中的表進行分析,該函數可以對數據表中的列的數據類型提出優化建議。
#語法
select * from table_name procedure analyse();
#或
select * from table_name procedure analyse(element_num,max_memory);第2個語句中告訴該函數不要為那些包含的值多於element_num個或者max_memory個字節的enum類型提出建議。如果沒有這些限制,輸出信息可能很長,enum類型定義通常很難閱讀。
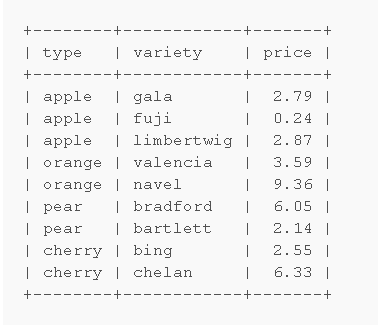
SELECT * FROM c PROCEDURE ANALYSE(16,255);
field_name 對於表哪個字段,optimal_fieldtype給出優化建議。
對數據表的拆分,分為兩種拆分方式:垂直拆分,水平拆分
即把主鍵和一些數據表的列放在一個表中,然後把主鍵和另一些數據表的列放在一個表中。
如果一個表的某些列常用,另一些不常用,則可以采用垂直拆分。垂直拆分可以使數據行變小,一個數據頁就可以存放更多的數據,在查詢時候可以減少I/O次數。其缺點是需要管理冗余列,查詢所有數據時候需要join查找。
即把數據表中的列根據一定規則放在多個獨立的表或分區中。水平拆分使用場景:
表很大,分割後可以降低查詢時候需要讀取的數據和索引的頁數,同時降低索引的層數,提高查詢速度。 表中的數據是獨立的,例如表中分別記錄各個地區的數據或不同時期的數據,特別是有些數據常用,而另一些數據不常用。 需要把數據放在多個存儲介質上。?&esmsp;在數據庫設計中,規范化越高,那麼產生的關系就越多,直接導致表與表之間的join操作越頻繁,而join操作又是一種性能比較低的操作,直接影響到查詢的速度。
??反規范化的好處是降低了join操作的需求,降低了外鍵和索引數目。還可以減少表的個數,相應的帶來的問題是可能出現數據的完整性問題。加快查詢速度,但會降低修改速度。