整理得比較全面的MySQL優化參考
本文整理了一些MySQL的通用優化方法,做個簡單的總結分享,旨在幫助那些沒有專職MySQL DBA的企業做好基本的優化工作,至於具體的SQL優化,大部分通過加適當的索引即可達到效果,更復雜的就需要具體分析了。

1、硬件層相關優化
1.1、CPU相關
在服務器的BIOS設置中,可調整下面的幾個配置,目的是發揮CPU最大性能,或者避免經典的NUMA問題:
1、選擇Performance Per Watt Optimized(DAPC)模式,發揮CPU最大性能,跑DB這種通常需要高運算量的服務就不要考慮節電了;
2、關閉C1E和C States等選項,目的也是為了提升CPU效率;
3、Memory Frequency(內存頻率)選擇Maximum Performance(最佳性能);
4、內存設置菜單中,啟用Node Interleaving,避免NUMA問題;
1.2、磁盤I/O相關
下面幾個是按照IOPS性能提升的幅度排序,對於磁盤I/O可優化的一些措施:
1、使用SSD或者PCIe SSD設備,至少獲得數百倍甚至萬倍的IOPS提升;
2、購置陣列卡同時配備CACHE及BBU模塊,可明顯提升IOPS(主要是指機械盤,SSD或PCIe SSD除外。同時需要定期檢查CACHE及BBU模塊的健康狀況,確保意外時不至於丟失數據);
3、有陣列卡時,設置陣列寫策略為WB,甚至FORCE WB(若有雙電保護,或對數據安全性要求不是特別高的話),嚴禁使用WT策略。並且閉陣列預讀策略,基本上是雞肋,用處不大;
4、盡可能選用RAID-10,而非RAID-5;
5、使用機械盤的話,盡可能選擇高轉速的,例如選用15KRPM,而不是7.2KRPM的盤,不差幾個錢的;
2、系統層相關優化
2.1、文件系統層優化
在文件系統層,下面幾個措施可明顯提升IOPS性能:
1、使用deadline/noop這兩種I/O調度器,千萬別用cfq(它不適合跑DB類服務);
2、使用xfs文件系統,千萬別用ext3;ext4勉強可用,但業務量很大的話,則一定要用xfs;
3、文件系統mount參數中增加:noatime, nodiratime, nobarrier幾個選項(nobarrier是xfs文件系統特有的);
2.2、其他內核參數優化
針對關鍵內核參數設定合適的值,目的是為了減少swap的傾向,並且讓內存和磁盤I/O不會出現大幅波動,導致瞬間波峰負載:
1、將vm.swappiness設置為5-10左右即可,甚至設置為0(RHEL 7以上則慎重設置為0,除非你允許OOM kill發生),以降低使用SWAP的機會;
2、將vm.dirty_background_ratio設置為5-10,將vm.dirty_ratio設置為它的兩倍左右,以確保能持續將髒數據刷新到磁盤,避免瞬間I/O寫,產生嚴重等待(和MySQL中的innodb_max_dirty_pages_pct類似);
3、將net.ipv4.tcp_tw_recycle、net.ipv4.tcp_tw_reuse都設置為1,減少TIME_WAIT,提高TCP效率;
4、至於網傳的read_ahead_kb、nr_requests這兩個參數,我經過測試後,發現對讀寫混合為主的OLTP環境影響並不大(應該是對讀敏感的場景更有效果),不過沒准是我測試方法有問題,可自行斟酌是否調整;
3、MySQL層相關優化
3.1、關於版本選擇
官方版本我們稱為ORACLE MySQL,這個沒什麼好說的,相信絕大多數人會選擇它。
我個人強烈建議選擇Percona分支版本,它是一個相對比較成熟的、優秀的MySQL分支版本,在性能提升、可靠性、管理型方面做了不少改善。它和官方ORACLE MySQL版本基本完全兼容,並且性能大約有20%以上的提升,因此我優先推薦它,我自己也從2008年一直以它為主。
另一個重要的分支版本是MariaDB,說MariaDB是分支版本其實已經不太合適了,因為它的目標是取代ORACLE MySQL。它主要在原來的MySQL Server層做了大量的源碼級改進,也是一個非常可靠的、優秀的分支版本。但也由此產生了以GTID為代表的和官方版本無法兼容的新特性(MySQL 5.7開始,也支持GTID模式在線動態開啟或關閉了),也考慮到絕大多數人還是會跟著官方版本走,因此沒優先推薦MariaDB。
3.2、關於最重要的參數選項調整建議
建議調整下面幾個關鍵參數以獲得較好的性能(可使用本站提供的my.cnf生成器生成配置文件模板):
1、選擇Percona或MariaDB版本的話,強烈建議啟用thread pool特性,可使得在高並發的情況下,性能不會發生大幅下降。此外,還有extra_port功能,非常實用, 關鍵時刻能救命的。還有另外一個重要特色是 QUERY_RESPONSE_TIME 功能,也能使我們對整體的SQL響應時間分布有直觀感受;
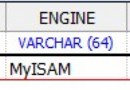
2、設置default-storage-engine=InnoDB,也就是默認采用InnoDB引擎,強烈建議不要再使用MyISAM引擎了,InnoDB引擎絕對可以滿足99%以上的業務場景;
3、調整innodb_buffer_pool_size大小,如果是單實例且絕大多數是InnoDB引擎表的話,可考慮設置為物理內存的50% ~ 70%左右;
4、根據實際需要設置innodb_flush_log_at_trx_commit、sync_binlog的值。如果要求數據不能丟失,那麼兩個都設為1。如果允許丟失一點數據,則可分別設為2和10。而如果完全不用care數據是否丟失的話(例如在slave上,反正大不了重做一次),則可都設為0。這三種設置值導致數據庫的性能受到影響程度分別是:高、中、低,也就是第一個會另數據庫最慢,最後一個則相反;
5、設置innodb_file_per_table = 1,使用獨立表空間,我實在是想不出來用共享表空間有什麼好處了;
6、設置innodb_data_file_path = ibdata1:1G:autoextend,千萬不要用默認的10M,否則在有高並發事務時,會受到不小的影響;
7、設置innodb_log_file_size=256M,設置innodb_log_files_in_group=2,基本可滿足90%以上的場景;
8、設置long_query_time = 1,而在5.5版本以上,已經可以設置為小於1了,建議設置為0.05(50毫秒),記錄那些執行較慢的SQL,用於後續的分析排查;
9、根據業務實際需要,適當調整max_connection(最大連接數)、max_connection_error(最大錯誤數,建議設置為10萬以上,而open_files_limit、innodb_open_files、table_open_cache、table_definition_cache這幾個參數則可設為約10倍於max_connection的大小;
10、常見的誤區是把tmp_table_size和max_heap_table_size設置的比較大,曾經見過設置為1G的,這2個選項是每個連接會話都會分配的,因此不要設置過大,否則容易導致OOM發生;其他的一些連接會話級選項例如:sort_buffer_size、join_buffer_size、read_buffer_size、read_rnd_buffer_size等,也需要注意不能設置過大;
11、由於已經建議不再使用MyISAM引擎了,因此可以把key_buffer_size設置為32M左右,並且強烈建議關閉query cache功能;
3.3、關於Schema設計規范及SQL使用建議
下面列舉了幾個常見有助於提升MySQL效率的Schema設計規范及SQL使用建議:
1、所有的InnoDB表都設計一個無業務用途的自增列做主鍵,對於絕大多數場景都是如此,真正純只讀用InnoDB表的並不多,真如此的話還不如用TokuDB來得劃算;
2、字段長度滿足需求前提下,盡可能選擇長度小的。此外,字段屬性盡量都加上NOT NULL約束,可一定程度提高性能;
3、盡可能不使用TEXT/BLOB類型,確實需要的話,建議拆分到子表中,不要和主表放在一起,避免SELECT * 的時候讀性能太差。
4、讀取數據時,只選取所需要的列,不要每次都SELECT *,避免產生嚴重的隨機讀問題,尤其是讀到一些TEXT/BLOB列;
5、對一個VARCHAR(N)列創建索引時,通常取其50%(甚至更小)左右長度創建前綴索引就足以滿足80%以上的查詢需求了,沒必要創建整列的全長度索引;
6、通常情況下,子查詢的性能比較差,建議改造成JOIN寫法;
7、多表聯接查詢時,關聯字段類型盡量一致,並且都要有索引;
8、多表連接查詢時,把結果集小的表(注意,這裡是指過濾後的結果集,不一定是全表數據量小的)作為驅動表;
9、多表聯接並且有排序時,排序字段必須是驅動表裡的,否則排序列無法用到索引;
10、多用復合索引,少用多個獨立索引,尤其是一些基數(Cardinality)太小(比如說,該列的唯一值總數少於255)的列就不要創建獨立索引了;
11、類似分頁功能的SQL,建議先用主鍵關聯,然後返回結果集,效率會高很多;
3.4、其他建議
關於MySQL的管理維護的其他建議有:
1、通常地,單表物理大小不超過10GB,單表行數不超過1億條,行平均長度不超過8KB,如果機器性能足夠,這些數據量MySQL是完全能處理的過來的,不用擔心性能問題,這麼建議主要是考慮ONLINE DDL的代價較高;
2、不用太擔心mysqld進程占用太多內存,只要不發生OOM kill和用到大量的SWAP都還好;
3、在以往,單機上跑多實例的目的是能最大化利用計算資源,如果單實例已經能耗盡大部分計算資源的話,就沒必要再跑多實例了;
4、定期使用pt-duplicate-key-checker檢查並刪除重復的索引。定期使用pt-index-usage工具檢查並刪除使用頻率很低的索引;
5、定期采集slow query log,用pt-query-digest工具進行分析,可結合Anemometer系統進行slow query管理以便分析slow query並進行後續優化工作;
6、可使用pt-kill殺掉超長時間的SQL請求,Percona版本中有個選項 innodb_kill_idle_transaction 也可實現該功能;
7、使用pt-online-schema-change來完成大表的ONLINE DDL需求;
8、定期使用pt-table-checksum、pt-table-sync來檢查並修復mysql主從復制的數據差異;
寫在最後:這次的優化參考,大部分情況下我都介紹了適用的場景,如果你的應用場景和本文描述的不太一樣,那麼建議根據實際情況進行調整,而不是生搬硬套。歡迎質疑拍磚,但拒絕不經過大腦的習慣性抵制。