在程序設計中,經常以樹形結構表示數據的層次關系,如菜單的結構、商品的分類等。
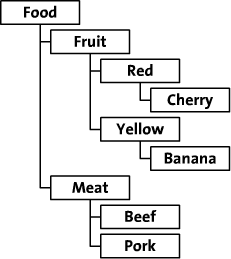
這樣的層次結構在關系數據庫中難以直觀地表示。常見的一種做法是用一個字段指向上級節點來表示記錄的上下級關系。
fid pid fname 1 Food 2 1 Fruit 3 2 Red 4 3 Cherry 5 2 Yellow 6 5 Banana 7 1 Meat 8 7 Beef 9 7 Pork當要查詢某一節點的上一級節點,比如 Beff,可以查詢 Beff(pid=7) 指向的那條記錄。
SELECT * FROM food WHERE fid = 7;
當要查詢某一節點的下一級節點,比如 Fruit,可以查詢 pid 指向 Fruit(fid=2) 的記錄。
SELECT * FROM food WHERE pid = 2;
另有一種基於左右值編碼的設計,這種設計方式的表結構如下:
fid fname lft rgt 1 Food 1 18 2 Fruit 2 11 3 Red 3 6 4 Cherry 4 5 5 Yellow 7 10 6 Banana 8 9 7 Meat 12 17 8 Beef 13 14 9 Pork 15 16fid 跟節點的層次完全沒有關系,僅僅用來標識節點。引入了左右值來表示節點之間的關系,如下圖所示。
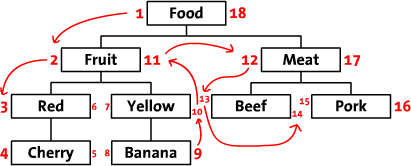
這樣的設計能夠方便地遍歷一棵樹,從左值數到右值便是先序遍歷了一棵(子)樹。更多詳細的設計,參見 http://www.sitepoint.com/hierarchical-data-database/ 和 http://blog.csdn.net/monkey_d_meng/article/details/6647488
最後一種自己想到的設計:用字符串 str 來標識節點,並約定標識其上級節點的字符串為 substr(str, 1, length(str)-1)。例如,有一節點的以 "abc" 標識,則其上級節點以 "ab" 標識。
fid fname a Food aa Fruit aaa Red aaaa Cherry aab Yellow aaba Banana ab Meat aba Beef abb Pork當要查詢某一節點的上一級節點,比如 Beff,因為 Beff 的 fid 為 "aba", 所以其上級節點的 fid 為 "ab"。
SELECT * FROM food WHERE fid = 'ab';
當要查詢某一節點的路徑,比如 Beff,因為 Beff 的 fid 為 "aba",所有其路徑為 a/ab/aba。
SELECT * FROM food WHERE fid IN ('a', 'ab', 'aba') ORDER BY fid;
當要查詢某一節點的下一級節點,比如 Fruit,因為 Fruit 的 fid 為 "aa",所以其下一級節點的 fid 是以 "aa" 開頭且比 "aa" 多一個字符的字符串。
SELECT * FROM food WHERE fid LIKE 'aa_';
當要查詢某一節點的所有下級地區,比如 Fruit,因為 Fruit 的 fid 為 "aa",所以其所有下級節點的 fid 是以 "aa" 開頭的字符串。
SELECT * FROM food WHERE fid LIKE 'aa%' AND fid != 'aa';
第一種設計方式, 直觀方便,但是在對樹的遍歷過程中需要遞歸查詢,數據量大時,對效率的影響很大。這種設計適合的場景:1) 數據量不大的時候; 2) 只會經常查詢節點的下一級節點而不會頻繁查詢節點的所有下級節點。
基於左右值編碼的設計方式,消除了遍歷樹時的遞歸操作,查詢效率高,但是設計較為復雜,增刪節點的代價較大。
第三種設計方式,同樣刪除了遍歷樹是的遞歸操作,無論是廣度優先搜索(ORDER BY LENGTH(fid))還是深度優先搜索(ORDER BY fid),都極為方便。這種設計在增刪節點時會影響著節點的所有下級節點的標識編碼。這種設計方式適合的場景:1) 樹形結構基本穩定,很少需要對其增刪節點; 2) 需要頻繁地查詢某個節點的所有下級節點。