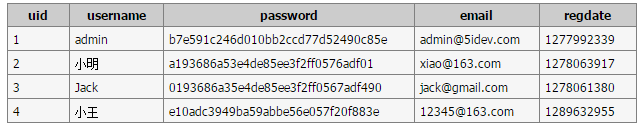
【問題來源】將設計的數據庫表展示的時候,yu哥問我,你的那個top_info字段定義的類型是varchar(100),為什麼是100呢,這100的長度能存多少個中文?
當時的想法就是,這個100能存多少個中文和數據庫的編碼方式有關,具體怎麼個有關發還真是沒有細細探究。為了搞清這一系列的問題,我百度了一下,但是網上的答案千奇百怪,很不給力,只能自己摸索了。
首先需要明確的是:utf8編碼方式下,一個中文占3個字節;而gbk編碼下,一個中文占2個字節。這個我們可以使用varchar類型存儲一個字段vname,然後分別向其中添加一個漢字和英文,然後select length(vname) from tablename;然後我們添加進去的數據占多少個字節一目了然。再用select char_length(vname) from tablename,你會發現二者的關系就是上述內容。
回到那個問題,這100的長度到底能存多少個中文,既然一個中文占3個字節,是不是就只能存100/3=33個中文呢??換句話說,100這個數字是字節數,還是字符數!?為此我做了如下測試:
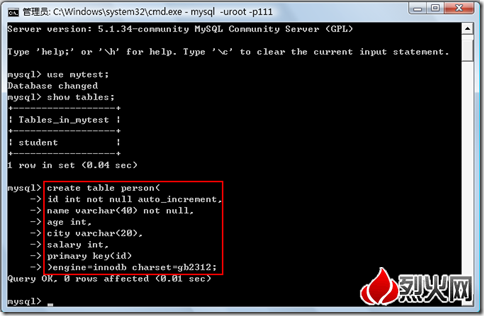
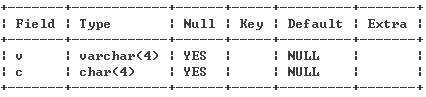
在linux上的mysql中定義了下表
CREATE TABLE `test` (
`v` varchar(4) default NULL,
`c` char(4) default NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
即如下圖
然後insert into test values (‘圍脖你好’,’圍脖你好’);有2個warning,select之後才發現
只存進去一個“新”字,後面的全丟了。這就說明,varchar(4)和char(4)中的4是字節數,即100是字節數,只能存33個中文字符。(備注:如果我們存儲的字符串長度超過預定義的長度,mysql仍然可以存儲成功,只是會提示warning,會將超出的部分自動截斷。)
答案貌似明確了,但緊接著問題又來了!
因為以前聽說,這個varchar(n)和char(n)中的n指的是存儲的字符數,這不和我剛才做的測試完全不符嗎?所以我又在本地windows下的mysql中做了同樣的操作,建相同的表,插入相同的數據,看到結果,我傻眼了!!
insert into test values (‘圍脖你好’,’圍脖你好’);並未warning,而是query OK!select之後發現,這四個中文竟然都存進去了,這也就說明我們剛才定義的那個char(4)和varchar(4)中的4是字符數,而非字節數,這麼說來,那100就是可以存100個中文字符了,這不完全將剛才的那個結論顛覆了??可是這兩個結果都是對的啊,只是環境不同而已。
這樣的話,那我們以後定義char和varchar字段還要先判斷一下該環境下這個(n)到底代表的啥?是字節還是字符?
不甘心,想搞清楚原因,為何會出現這樣的差別?於是yu哥給我說了這樣一個命令
Show variable like ‘%char%’;
這下清晰了,linux下的和windows下的mysql相關變量編碼定義完美呈現

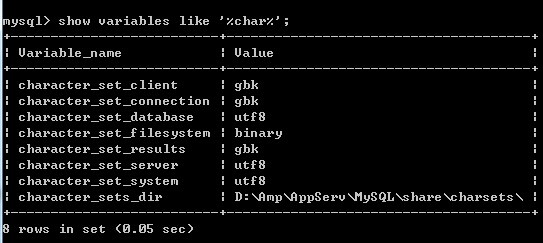
實際上,character_set_client、character_set_connection、character_set_results是可以改變的,這個可以使用set names gbk/utf8, 只是為了和客戶端編碼頁保持一致,不會亂碼,如果客戶端編輯頁設定的文檔是utf8,那麼我們自然要set names utf8了,gbk同理。這個命令只會改變顯示問題,底部的database的編碼還是不會因為這個命令而受到影響的。包括server、system也不會隨之改變,這時我們對比上下兩張表,他們的server和system以及database的編碼發現Linux下的都是Latin1,而windows下的這個都是utf8,
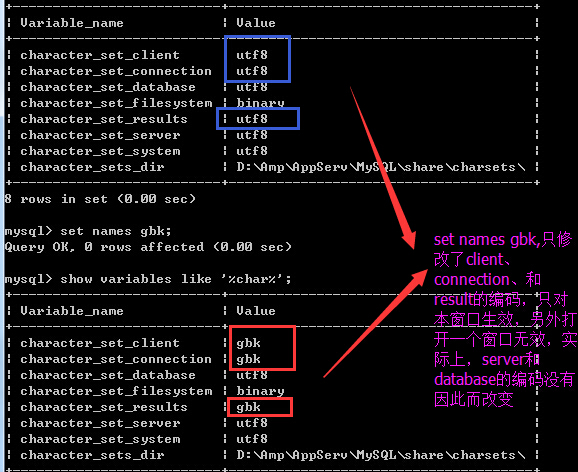
我們知道Latin1都是存儲字節為單位的字符比如數字、字母,一個Latin字符只占一個字節,而utf8存儲的種類繁多,字符所占的字節數也就不確定了,utf8具有統一功能,其實網上大多是說char(n)存的是n個字符,就是因為此處的編碼都是utf8的,utf8屏蔽了中文和英文和數字的顯示區別,他們都是一個字符,所以定義的時候那個n就代表了字符的個數,具體占多少個字節是根據他們自身字符串的長度定的,比如char(100)存儲100個中文,那麼占300個字節,存100個字母,就占100個字節。
但是這好像並不能說明這n代表的是字符而不是字節!
什麼情況下它代表字節,什麼情況下代表字符?這和我們剛才列出的那些變量的編碼有什麼關系?。。。。。。繼續探索中,求指點!
注:部分描述可能存在問題,望提出寶貴的意見和指導。
附:char與varchar的部分總結比較(與此文無關)