有這樣的一個需求:select count(distinct nick) from user_access_xx_xx;
這條sql用於統計用戶訪問的uv,由於單表的數據量在10G以上,即使在user_access_xx_xx上加上nick的索引,
通過查看執行計劃,也為全索引掃描,sql在執行的時候,會對整個服務器帶來抖動;
root@db 09:00:12>select count(distinct nick) from user_access; +———————-+ | count(distinct nick) | +———————-+ | 806934 | +———————-+ 1 row in set (52.78 sec)
執行一次sql需要花費52.78s,已經非常的慢了
現在需要換一種思路來解決該問題:
我們知道索引的值是按照索引字段升序的,比如我們對(nick,other_column)兩個字段做了索引,那麼在索引中的則是按照nick,other_column的升序排列:
我們現在的sql:select count(distinct nick) from user_access;則是直接從nick1開始一條條掃描下來,直到掃描到最後一個nick_n,
那麼中間過程會掃描很多重復的nick,如果我們能夠跳過中間重復的nick,則性能會優化非常多(在oracle中,這種掃描技術為loose index scan,但在5.1的版本中,mysql中還不能直接支持這種優化技術):
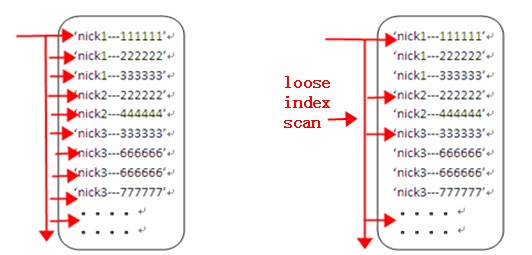
所以需要通過改寫sql來達到偽loose index scan:
root@db 09:41:30>select count(*) from ( select distinct(nick) from user_access)t ; | count(*) | +———-+ | 806934 | 1 row in set (5.81 sec)
Sql中先選出不同的nick,最後在外面套一層,就可以得到nick的distinct值總和;
最重要的是在子查詢中:select distinct(nick) 實現了上圖中的偽loose index scan,優化器在這個時候的執行計劃為Using index for group-by ,
需要注意的是mysql把distinct優化為group by,它首先利用索引來分組,然後掃描索引,對需要的nick只掃描一次;
兩個sql的執行計劃分別為:
優化寫法:
root@db 09:41:10>explain select distinct(nick) from user_access-> ; +—-+————-+——————————+——-+—————+————-| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +—-+————-+——————————+——-+—————+————- | 1 | SIMPLE | user_access | range | NULL | ind_user_access_nick | 67 | NULL | 2124695 | Using index for group-by | +—-+————-+——————————+——-+—————+————-
原始寫法:
root@db 09:42:55>explain select count(distinct nick) from user_access; +—-+————-+——————————+——-+—————+————- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +—-+————-+——————————+——-+—————+————- | 1 | SIMPLE | user_access | index | NULL | ind_user_access | 177 | NULL | 19546123 | Using index |