前情提要 : 需求就是一個普通的兩個表連接從而查詢出詳細信息。其中A表是大表, 測試數據都有數萬條; B表是小表大概1000多條數據。
1. 為了趕工寫出的未優化SQL(為突出主題, 返回字段用 * 代替不寫出詳細字段, WHERE條件也去掉了):
SELECT
*
FROM
A a
LEFT JOIN
B b
ON
a.JOB_ID = b.ID
耗時:3.712s

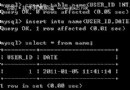
rows字段代表這個步驟相對上一步結果每一行需要掃描的行數,可以看到這個sql需要掃描的行數為22711*1230, 這幾乎是兩個表做笛卡爾積的開銷了(select * from a, b)。
MySQL對JOIN的處理采用了一種叫做BLOCK Nested-Loop 的算法。 Block Nested-Loop 算法是通過驅動表(可以簡單理解為前面的表)的結果集作為循環基礎數據, 然後一條一條的通過該結果集中的數據作為過濾條件到下一個表中查詢數據,然後合並結果。 如果還有第三個參與 JOIN, 則再通過前面兩個表的 JOIN 結果集作為JOIN的基礎數據,再一次通過循環查詢條件到第三個表中查詢數據。 結論: 驅動表(前面表)的數據量決定了總掃描數。
2. 從業務上
都是全表掃描, 然後我發現左表數據在業務上如果右表為NULL就沒意義了, 然後改為INNER JOIN。
耗時: 2.745s

3. 可以看到上面的type都是ALL
system/const/eq_ref/ref/range/index/ALL ---- 從左到右效率遞減
都是type都是ALL考慮到連接的條件是否可以為主鍵, 有主鍵的話MySQL可以使用索引查詢, 效率會提升很多。
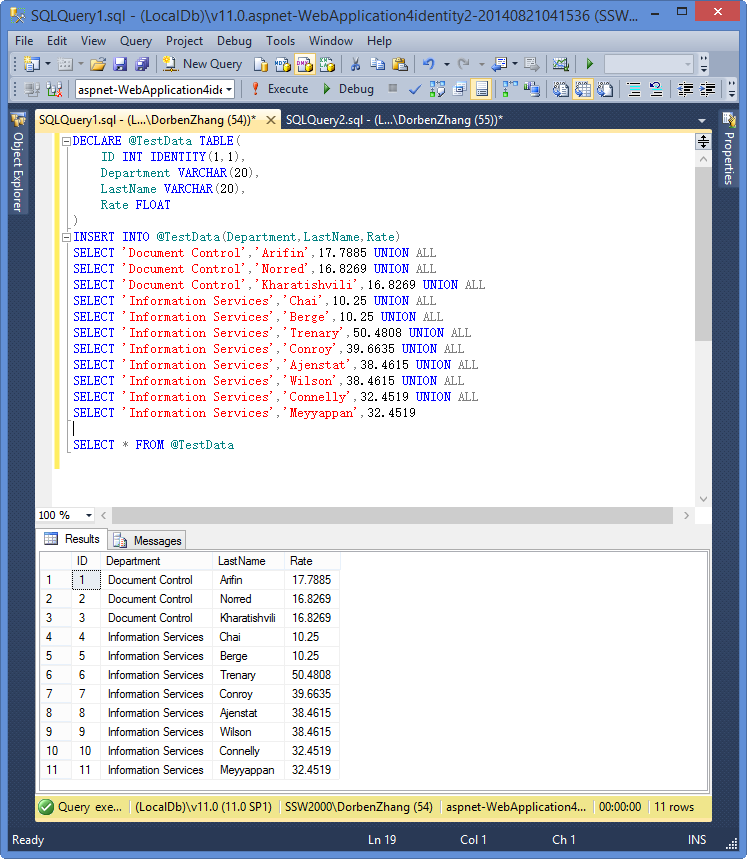
由於A表是歷史表做鏈接的字段不是主鍵, 所以只能在B表把這個字段加上主鍵。
耗時: 2.672s

還是很慢, 因為還沒建立索引, 現在對B表ID字段加上索引, 結果如下:
耗時:0.109s