MySQL的cluster方案有很多官方和第三方的選擇,選擇多就是一種煩惱,因此,我們考慮MySQL數據庫滿足下三點需求,考察市面上可行的解決方案:
高可用性:主服務器故障後可自動切換到後備服務器可伸縮性:可方便通過腳本增加DB服務器負載均衡:支持手動把某公司的數據請求切換到另外的服務器,可配置哪些公司的數據服務訪問哪個服務器需要選用一種方案滿足以上需求。在MySQL官方網站上參考了幾種解決方案的優缺點:
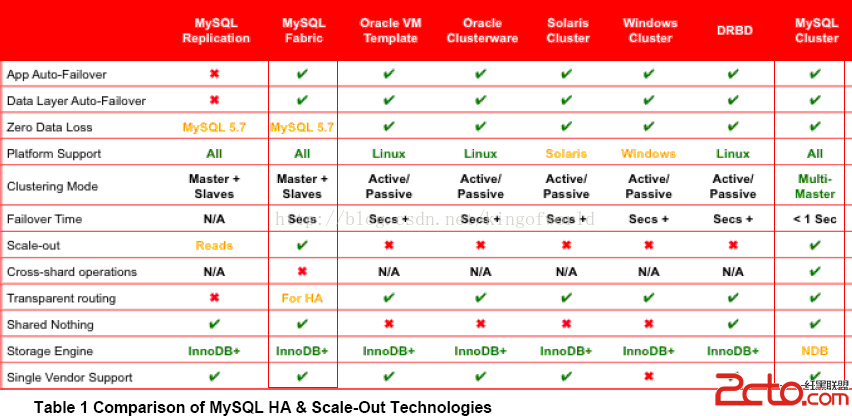
綜合考慮,決定采用MySQL Fabric和MySQL Cluster方案,以及另外一種較成熟的集群方案Galera Cluster進行預研。
簡介:
MySQL Cluster 是MySQL 官方集群部署方案,它的歷史較久。支持通過自動分片支持讀寫擴展,通過實時備份冗余數據,是可用性最高的方案,聲稱可做到99.999%的可用性。
架構及實現原理:
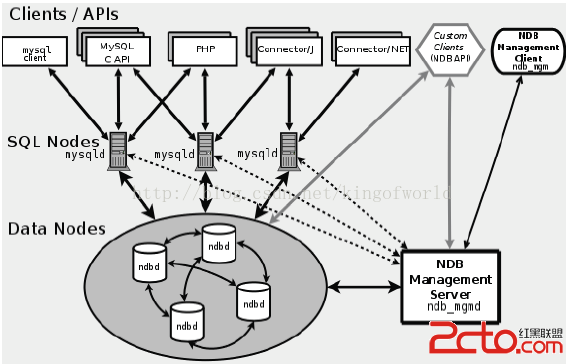
MySQL cluster主要由三種類型的服務組成:
NDB Management Server:管理服務器主要用於管理cluster中的其他類型節點(Data Node和SQL Node),通過它可以配置Node信息,啟動和停止Node。 SQL Node:在MySQL Cluster中,一個SQL Node就是一個使用NDB引擎的mysql server進程,用於供外部應用提供集群數據的訪問入口。Data Node:用於存儲集群數據;系統會盡量將數據放在內存中。
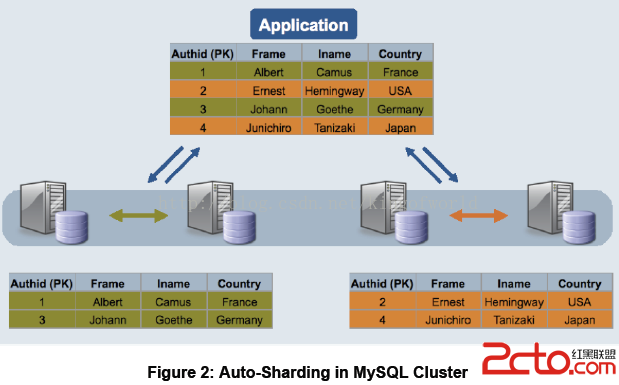
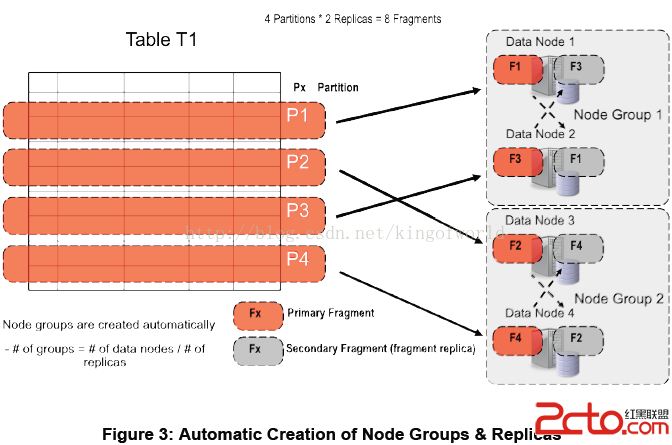
缺點及限制:
對需要進行分片的表需要修改引擎Innodb為NDB,不需要分片的可以不修改。NDB的事務隔離級別只支持Read Committed,即一個事務在提交前,查詢不到在事務內所做的修改;而Innodb支持所有的事務隔離級別,默認使用Repeatable Read,不存在這個問題。外鍵支持:雖然最新的Cluster版本已經支持外鍵,但性能有問題(因為外鍵所關聯的記錄可能在別的分片節點中),所以建議去掉所有外鍵。Data Node節點數據會被盡量放在內存中,對內存要求大。
數據庫系統提供了四種事務隔離級別:
A.Serializable(串行化):一個事務在執行過程中完全看不到其他事務對數據庫所做的更新(事務執行的時候不允許別的事務並發執行。事務串行化執行,事務只能一個接著一個地執行,而不能並發執行。)。
B.Repeatable Read(可重復讀):一個事務在執行過程中可以看到其他事務已經提交的新插入的記錄,但是不能看到其他其他事務對已有記錄的更新。
C.Read Commited(讀已提交數據):一個事務在執行過程中可以看到其他事務已經提交的新插入的記錄,而且能看到其他事務已經提交的對已有記錄的更新。
D.Read Uncommitted(讀未提交數據):一個事務在執行過程中可以看到其他事務沒有提交的新插入的記錄,而且能看到其他事務沒有提交的對已有記錄的更新。
簡介:
為了實現和方便管理MySQL 分片以及實現高可用部署,Oracle在2014年5月推出了一套為各方寄予厚望的MySQL產品 -- MySQL Fabric, 用來管理MySQL 服務,提供擴展性和容易使用的系統,Fabric當前實現了兩個特性:高可用和使用數據分片實現可擴展性和負載均衡,這兩個特性能單獨使用或結合使用。
MySQL Fabric 使用了一系列的python腳本實現。
應用案例:由於該方案在去年才推出,目前在網上暫時沒搜索到有大公司的應用案例。
架構及實現原理:
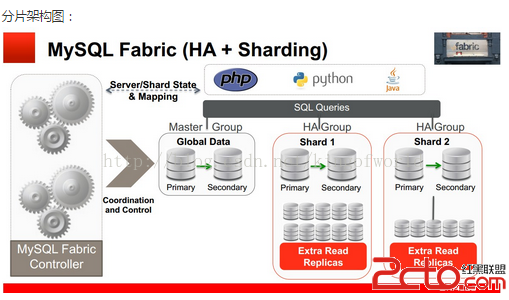
Fabric支持實現高可用性的架構圖如下:
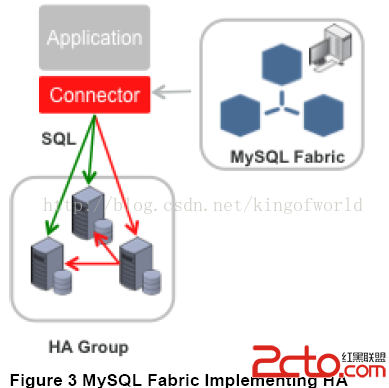
Fabric使用HA組實現高可用性,其中一台是主服務器,其他是備份服務器, 備份服務器通過同步復制實現數據冗余。應用程序使用特定的驅動,連接到Fabric 的Connector組件,當主服務器發生故障後,Connector自動升級其中一個備份服務器為主服務器,應用程序無需修改。
Fabric支持可擴展性及負載均衡的架構如下:
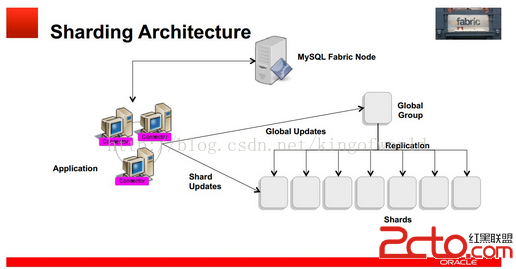
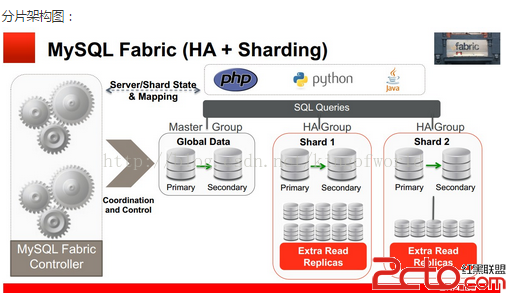
使用多個HA 組實現分片,每個組之間分擔不同的分片數據(組內的數據是冗余的,這個在高可用性中已經提到)
應用程序只需向connector發送query和insert等語句,Connector通過MasterGroup自動分配這些數據到各個組,或從各個組中組合符合條件的數據,返回給應用程序。
缺點及限制:
影響比較大的兩個限制是:

測試高可用性
服務器架構:
功能
IP
Port
Backing store(保存各服務器配置信息)
200.200.168.24
3306
Fabric 管理進程(Connector)
200.200.168.24
32274
HA Group 1 -- Master
200.200.168.23
3306
HA Group 1 -- Slave
200.200.168.25
3306
安裝過程省略,下面講述如何設置高可用組、添加備份服務器等過程
首先,創建高可用組,例如組名group_id-1,命令:
mysqlfabric group create group_id-1
往組內group_id-1添加機器200.200.168.25和200.200.168.23:
mysqlfabric group add group_id-1 200.200.168.25:3306
mysqlfabric group add group_id-1 200.200.168.23:3306
然後查看組內機器狀態:
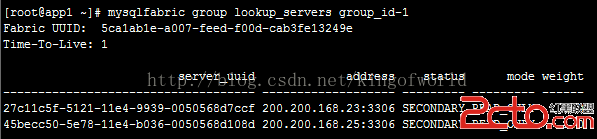
由於未設置主服務器,兩個服務的狀態都是SECONDARY
提升其中一個為主服務器:
mysqlfabric group promote group_id-1 --slave_id 00f9831f-d602-11e3-b65e-0800271119cb
然後再查看狀態:
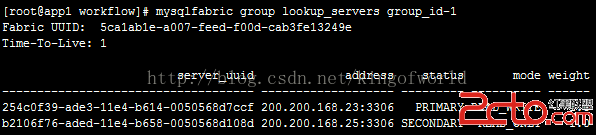
設置成主服務器的服務已經變成Primary。
另外,mode屬性表示該服務器是可讀寫(READ_WRITE),或只讀(READ_ONLY),只讀表示可以分攤查詢數據的壓力;只有主服務器能設置成可讀寫(READ_WRITE)。
這時檢查25服務器的slave狀態:
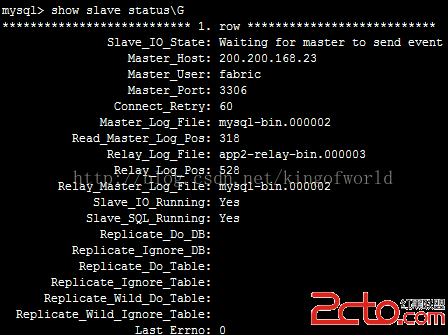
可以看到它的主服務器已經指向23
然後激活故障自動切換功能:
mysqlfabric group activate group_id-1
激活後即可測試服務的高可以性
首先,進行狀態測試:
停止主服務器23

然後查看狀態:
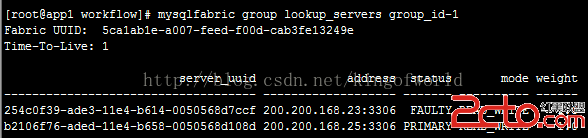
可以看到,這時將25自動提升為主服務器。
但如果將23恢復起來後,需要手動重新設置23為主服務器。
實時性測試:
目的:測試在主服務更新數據後,備份服務器多久才顯示這些數據
測試案例:使用java代碼建連接,往某張表插入100條記錄,看備份服務器多久才能同步這100條數據
測試結果:
表中原來有101條數據,運行程序後,查看主服務器的數據條數:
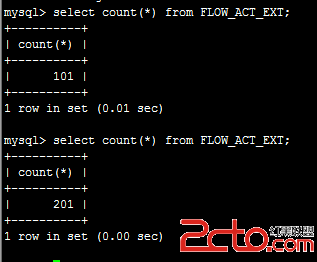
可見主服務器當然立即得到更新。
查看備份服務器的數據條數:
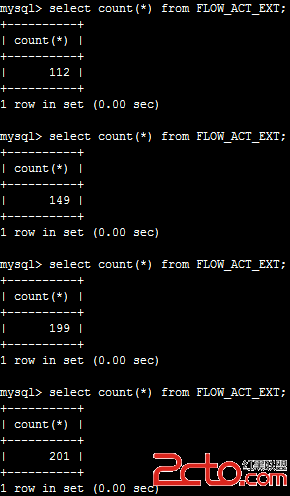
但備份服務器等待了1-2分鐘才同步完成(可以看到fabric使用的是異步復制,這是默認方式,性能較好,主服務器不用等待備份服務器返回,但同步速度較慢)
對於從服務器同步數據穩定性問題,有以下解決方案:
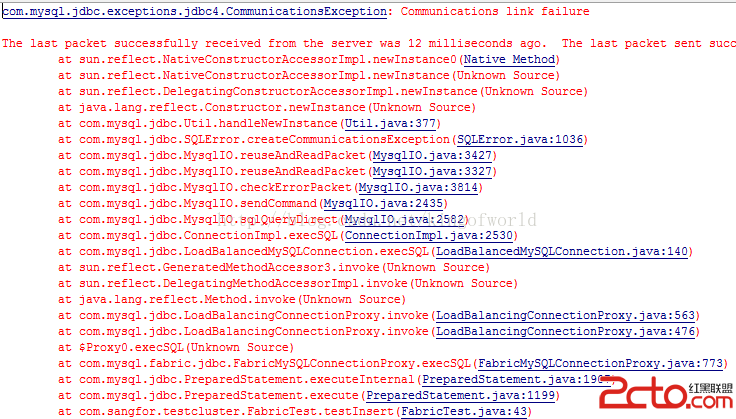
但這時再次發送sql命令,可以成功返回。證明只是當時的事務失敗了。連接切換到了備份服務器,仍然可用。
翻閱了mysql文檔,有章節說明了這個問題:

裡面提到:當主服務器當機時,我們的應用程序雖然是不需做任何修改的,但在主服務器被備份服務器替換前,某些事務會丟失,這些可以作為正常的mysql錯誤來處理。
數據完整性校驗:
測試主服務器停止後,備份服務器是否能夠同步所有數據。
重啟了剛才停止主服務器後,查看記錄數
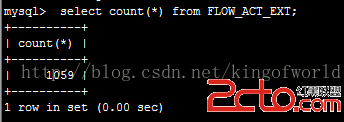
可以看到在插入1059條記錄後被停止了。
現在看看備份服務器的記錄數是多少,看看在主服務器當機後是否所有數據都能同步過來
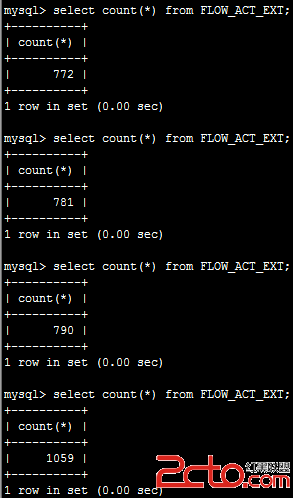
大約經過了幾十秒,才同步完,數據雖然不是立即同步過來,但沒有丟失。
1.2、分片:如何支持可擴展性和負載均衡
fabric分片簡介:當一台機器或一個組承受不了服務壓力後,可以添加服務器分攤讀寫壓力,通過Fabirc的分片功能可以將某些表中數據分散存儲到不同服務器。我們可以設定分配數據存儲的規則,通過在表中設置分片key設置分配的規則。另外,有些表的數據可能並不需要分片存儲,需要將整張表存儲在同一個服務器中,可以將設置一個全局組(Global Group)用於存儲這些數據,存儲到全局組的數據會自動拷貝到其他所有的分片組中。
簡介:
Galera Cluster號稱是世界上最先進的開源數據庫集群方案

主要優點及特性:
真正的多主服務模式:多個服務能同時被讀寫,不像Fabric那樣某些服務只能作備份用同步復制:無延遲復制,不會產生數據丟失熱備用:當某台服務器當機後,備用服務器會自動接管,不會產生任何當機時間自動擴展節點:新增服務器時,不需手工復制數據庫到新的節點支持InnoDB引擎對應用程序透明:應用程序不需作修改

架構及實現原理:
首先,我們看看傳統的基於mysql Replication(復制)的架構圖:
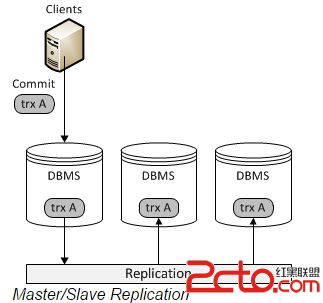
Replication方式是通過啟動復制線程從主服務器上拷貝更新日志,讓後傳送到備份服務器上執行,這種方式存在事務丟失及同步不及時的風險。Fabric以及傳統的主從復制都是使用這種實現方式。
而Galera則采用以下架構保證事務在所有機器的一致性:
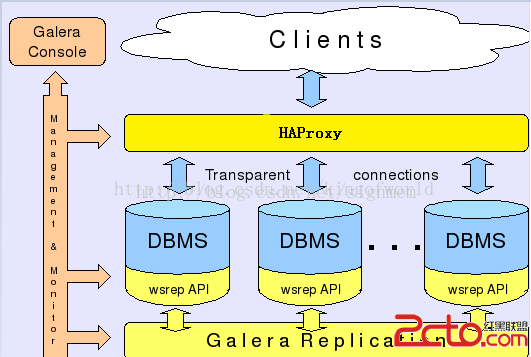
客戶端通過Galera Load Balancer訪問數據庫,提交的每個事務都會通過wsrep API 在所有服務器中執行,要不所有服務器都執行成功,要不就所有都回滾,保證所有服務的數據一致性,而且所有服務器同步實時更新。
缺點及限制:
包括:

集群部署架構:
功能
IP
Port
Backing store(保存各服務器配置信息)
200.200.168.24
3306
Fabric 管理進程(Connector)
200.200.168.24
32274
HA Master 1
200.200.168.24
3306
HA Master 2
200.200.168.25
3306
HA Master 3
200.200.168.23
3306
4.1、測試數據同步
在機器24上創建一個表:
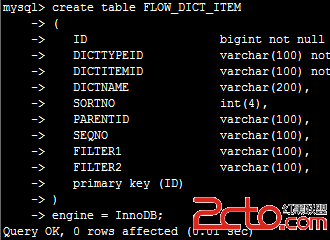
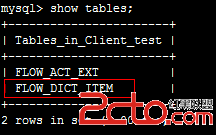
立即在25 中查看,可見已被同步創建
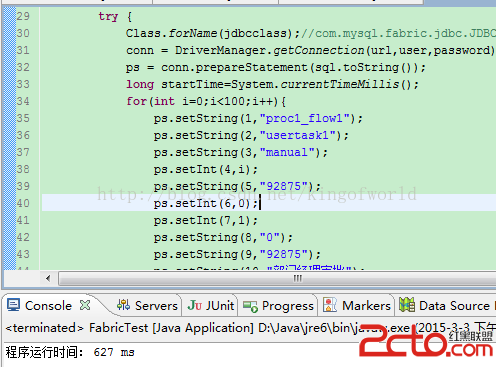
使用Java代碼在24服務器上插入100條記錄
立即在25服務器上查看記錄數
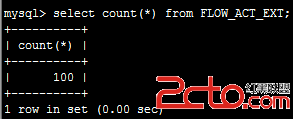
可見數據同步是立即生效的。
4.2、測試添加集群節點
添加一個集群節點的步驟很簡單,只要在新加入的機器上部署好Percona XtraDB Cluster,然後啟動,系統將自動將現存集群中的數據同步到新的機器上。
現在為了測試,先將其中一個節點服務停止:

然後使用java代碼在集群上插入100W數據
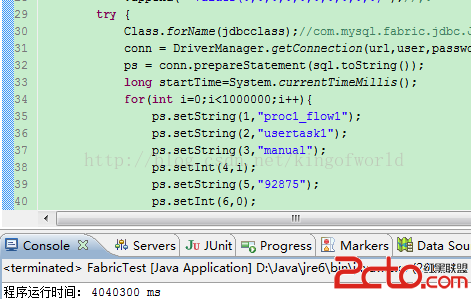
查看100w數據的數據庫大小:
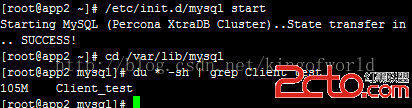
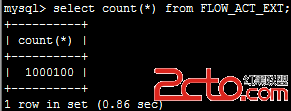
這時啟動另外一個節點,啟動時即會自動同步集群的數據:
啟動只需20秒左右,查看數據大小一致,查看表記錄數,也已經同步過來
MySQL Fabric
Galera Cluster
使用案例
2014年5月才推出,目前在網上暫時沒搜索到有大公司的應用案例
方案較成熟,外國多家互聯網公司使用
數據備份的實時性
由於使用異步復制,一般延時幾十秒,但數據不會丟失。
實時同步,數據不會丟失
數據冗余
使用分片,通過設置分片key規則可以將同一張表的不同數據分散在多台機器中
每個節點全冗余,沒有分片
高可用性
通過Fabric Connector實現主服務器當機後的自動切換,但由於備份延遲,切換後可能不能立即查詢數據
使用HAProxy實現。由於實時同步,切換的可用性更高。
可伸縮性
添加節點後,需要先手工復制集群數據
擴展節點十分方便,啟動節點時自動同步集群數據,100w數據(100M)只需20秒左右
負載均衡
通過HASharding實現
使用HAProxy實現負載均衡
程序修改
需要切換成jdbc:mysql:fabric的jdbc類和url
程序無需修改
性能對比
使用java直接用jdbc插入100條記錄,大概2000+ms
跟直接操作mysql一樣,直接用jdbc插入100條記錄,大概600ms
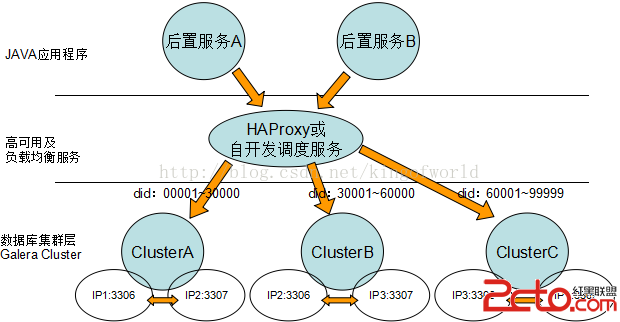
綜合考慮上面方案的優缺點,我們比較偏向選擇Galera 如果只有兩台數據庫服務器,考慮采用以下數據庫架構實現高可用性、負載均衡和動態擴展:
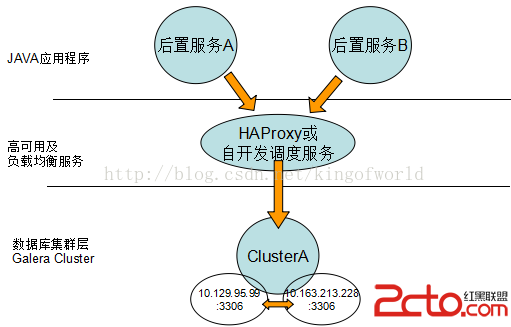
如果三台機器可以考慮: