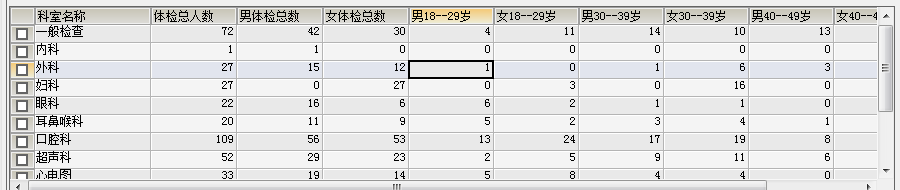
MySQL中auto_increment字段估計大家都經常用到,特別是innodb引擎。我也經常用,只知道mysql可以保證這個字段在多進程操作時的原子性,具體原理不甚了了,一次心血來潮,遂去查閱了MySQL手冊以及相關資料,了解了個大概。本文只探究了mysql5.5中innodb引擎auto_increment的問題,myisam引擎未測試,後續如果有時間我會補上。
傳統的auto_increment實現機制:mysql innodb引擎的表中的auto_increment字段是通過在內存中維護一個auto-increment計數器,來實現該字段的賦值,注意自增字段必須是索引,而且是索引的第一列,不一定要是主鍵。例如我現在在我的數據庫test中創建一個表t,語句如下:
CREATE TABLE t (a bigint unsigned auto_increment primary key) ENGINE=InnoDB;
則字段a為auto_increment類型,在mysql服務器啟動後,第一次插入數據到表t時,InnoDB引擎會執行等價於下面的語句:
SELECT MAX(a) FROM t FOR UPDATE;
Innodb獲取到當前表中a字段的最大值並將增加1(默認是增加1,如果要調整為增加其他數目,可以設置auto_increment_increment這個配置的設置)然後賦值給該列以及內存中該表對應的計數器。
如果表t為空,則InnoDB用來設置的值為為1.當然這個默認值夜可以通過 auto_increment_offset這個配置項來修改。
auto-increment計數器初始化以後,如果插入數據沒有指定auto_increment列的值,則Innodb直接增加auto-increment計數器的值並將增加後的值賦給新的列。如果插入數據指定了auto_increment列的值且這個值大於該表當前計數器的值,則該表計數器的值會被設置為該值。
插入數據時如果指定auto_increment列的值為NULL或者0,則和你沒有指定這個列的值一樣,mysql會從計數器中分配一個值給該列.而如果指定auto_increment列的值為負數或者超過該列所能存儲的最大數值,則該行為在mysql中沒有定義,可能會出現問題.根據我的測試來看,插入負值會有警告,不過最終存儲的數據還是正確的.如果是超過了比如上面定義的表t的bigint類型的最大值,同樣會有警告,而且插入的數值是bigint類型所能存儲的最大值18446744073709551615.
在傳統的auto_increment設置中,每次訪問auto-increment計數器的時候, INNODB都會加上一個名為AUTO-INC鎖直到該語句結束(注意鎖只持有到語句結束,不是事務結束).AUTO-INC鎖是一個特殊的表級別的鎖,用來提升包含auto_increment列的並發插入性能.因此,兩個事務不能同時獲取同一個表上面的AUTO-INC鎖,如果持有AUTO-INC鎖太長時間可能會影響到數據庫性能(比如INSERT INTO t1… SELECT … FROM t2這類語句).
2.改進的auto_increment鑒於傳統auto_increment機制要加AUTO-INC這種特殊的表級鎖,性能還是太差,於是在mysql5.1開始,新增加了一個配置項innodb_autoinc_lock_mode來設定auto_increment方式.可以設置的值為0,1,2.其中0就是第一節中描述的傳統auto_increment機制,而1和2則是新增加的模式,默認該值為1,可以中mysql配置文件中修改該值.這裡主要來看看這兩種新的方式的差別,在描述差別前需要先明確幾個插入類型:
1)simple inserts
simple inserts指的是那種能夠事先確定插入行數的語句,比如INSERT/REPLACE INTO 等插入單行或者多行的語句,語句中不包括嵌套子查詢。此外,INSERT INTO … ON DUPLICATE KEY UPDATE這類語句也要除外。
2)bulk inserts
bulk inserts指的是事先無法確定插入行數的語句,比如INSERT/REPLACE INTO … SELECT, LOAD DATA等。
3)mixed-mode inserts
指的是simple inserts類型中有些行指定了auto_increment列的值有些沒有指定,比如:
INSERT INTO t1 (c1,c2) VALUES (1,’a’), (NULL,’b’), (5,’c’), (NULL,’d’);
另外一種mixed-mode inserts是 INSERT … ON DUPLICATE KEY UPDATE這種語句,可能導致分配的auto_increment值沒有被使用。
下面看看設置innodb_autoinc_lock_mode為不同值時的情況:
innodb_autoinc_lock_mode=0(traditional lock mode)
傳統的auto_increment機制,詳見1.這種模式下所有針對auto_increment列的插入操作都會加AUTO-INC鎖,分配的值也是一個個分配,是連續的,正常情況下也不會有間隙(當然如果事務rollback了這個auto_increment值就會浪費掉,從而造成間隙)。
innodb_autoinc_lock_mode=1(consecutive lock mode)
這種情況下,針對bulk inserts才會采用AUTO-INC鎖這種方式,而針對simple inserts,則采用了一種新的輕量級的互斥鎖來分配auto_increment列的值。當然,如果其他事務已經持有了AUTO-INC鎖,則simple inserts需要等待.
需要注意的是,在innodb_autoinc_lock_mode=1時,語句之間是可能出現auto_increment值的間隔的。比如mixed-mode inserts以及bulk inserts中都有可能導致一些分配的auto_increment值被浪費掉從而導致間隙。後面會有例子。
innodb_autoinc_lock_mode=2(interleaved lock mode)
這種模式下任何類型的inserts都不會采用AUTO-INC鎖,性能最好,但是在同一條語句內部產生auto_increment值間隙。此外,這種模式對statement-based replication也不安全。
3.可能產生間隙原因總結經過上面的文檔分析,下面總結下針對auto_increment字段的各種類型的inserts語句可能出現間隙問題的原因:
simple inserts
針對innodb_autoinc_lock_mode=0,1,2,只有在一個有auto_increment列操作的事務出現回滾時,分配的auto_increment的值會丟棄不再使用,從而造成間隙。
bulk inserts(這裡就不考慮事務回滾的情況了,事務回滾是會造成間隙的)
innodb_autoinc_lock_mode=0,由於一直會持有AUTO-INC鎖直到語句結束,生成的值都是連續的,不會產生間隙。
innodb_autoinc_lock_mode=1,這時候一條語句內不會產生間隙,但是語句之間可能會產生間隙。後面會有例子說明。
innodb_autoinc_lock_mode=2,如果有並發的insert操作,那麼同一條語句內都可能產生間隙。
mixed-mode inserts
這種模式下針對innodb_autoinc_lock_mode的值配置不同,結果也會不同,當然innodb_autoinc_lock_mode=0時時不會產生間隙的,而innodb_autoinc_lock_mode=1以及innodb_autoinc_lock_mode=2是會產生間隙的。後面例子說明。
另外注意的一點是,在master-slave這種架構中,復制如果采用statement-based replication這種方式,則innodb_autoinc_lock_mode=0或1才是安全的。而如果是采用row-based replication或者mixed-based replication,則innodb_autoinc_lock_mode=0,1,2都是安全的。
4.實例測試的兩個表分別為t和t1,定義分別如下:
CREATE TABLE `t` (
`a` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`a`)
) ENGINE=InnoDB;
CREATE TABLE `t1` (
`c1` int(11) NOT NULL AUTO_INCREMENT,
`c2` varchar(10) DEFAULT NULL,
PRIMARY KEY (`c1`)
) ENGINE=InnoDB
首先在表t插入1-10000000共1千萬條數據,為了後面測試方便。開啟session1,執行下面語句:
insert into t1(c2) select * from t;
然後開啟session2,在t1中插入數據:
insert into t1(c2) values(400);
針對innodb_autoinc_lock_mode不同的情況,新插入的數據的c1的值也不同。
innodb_autoinc_lock_mode=0時,因為session1的語句都是加AUTO-INC鎖,因此,session1先開始的話,c1列的值都是1-10000000連續的值,由於在傳統機制下,auto_increment值都是一個個分配,因此session2插入的數據c1的值則是10000001。最終看到的就是有兩條這樣的數據(400,400),(10000001,400)。
innodb_autoinc_lock_mode=1時,同樣session1也會加AUTO-INC鎖,但是由於該模式下會預先分配auto_increment的值,所以可以看到在session2中插入的數據的c1值不會是10000001,但是不會是1-10000000這其中的數字,因為session1有加AUTO-INC鎖。最終的數據會是這樣兩條:(400,400), (10026856,400)。
innodb_autoinc_lock_mode=2時,session1不會加AUTO-INC鎖,因此雖然session2是後執行,但是並不影響auto_increment值分配,最終的值跟我們執行session2的時間有關,最終的值可能是這樣的:(400,400),(1235603,400)這樣的,會占用1-10000000之間的值。
5.另外幾點1)關於innodb_autoinc_lock_mode=1時,auto_increment預先分配策略可以參照參考資料2,假定表t中已經初始有一條記錄1,然後在表t中我們用`insert into t select NULL from t執行四次,可以看到表t中最終的記錄會是1,2,3,4,6,7,8,9,13,14,15,16,17,18,19,20,其中5,10,11,12都浪費掉了。參考資料1後面部分也有講到預分配問題。
2)INSERT INTO t1…SELECT … FROM t這類語句會對表t1加record lock,如果隔離級別是read committed,或者設置了innodb_locks_unsafe_for_binlog且隔離級別不是serialize,則不會對t加鎖,否則對t加shared next-key lock。