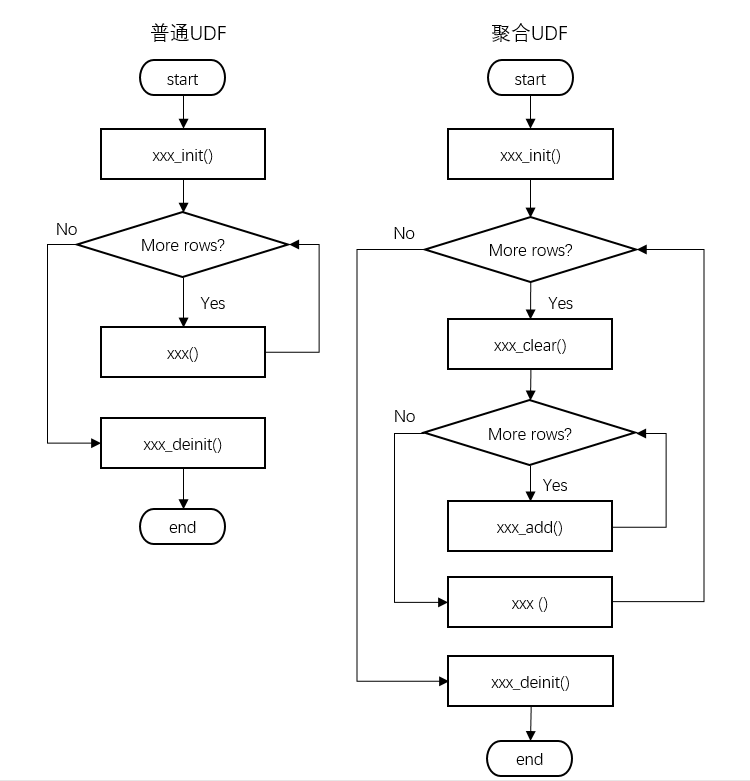
一:MySQL數據庫優化考量標准
1.數據庫設計(表設計合理)三范式(規范的模式)
三范式包括:
第一范式:1NF是對屬性的原子性的約束,要求屬性具有原子性,不可再分解。(只要是關系型數據庫都滿足)
第二范式:2NF是記錄的唯一性約束,要求記錄有唯一標識,即實體的唯一性。(設立主鍵)
第三范式:3NF是對字段冗余性約束,即任何字段不能由其他字段派生出來,要求字段沒有冗余。(通過表外鍵)
逆范式(適當的冗余):提高查詢效率。PS:冗余應當放在記錄盡量少的表上,避免造成空間浪費。.
2.sql語句優化
3.數據庫參數的配置(緩存大小)
4.恰當的硬件資源和操作系統
二:sql語句優化步驟
1.通過show status命令了解各種sql的執行效率
show status命令可以顯示你的MySQL數據庫的當前狀態。關心"Com_"打頭的數據語句。
顯示當前控制台的MySQL情況:
show status like "Com%" ; <=> show session status like "Com%";
顯示數據庫從啟動到此時的情況:
show global status like "Com%";
顯示連接數據庫的次數:
show status like "Connections";
顯示服務器工作了的時間:
show status like "Uptime";
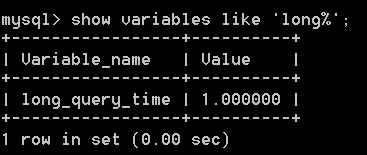
顯示慢查詢的次數(默認是10s):
show status like "slow_queries";
顯示慢查詢時間:
show variables like "long_query_time"
設置慢查詢時間(2s):
set long_query_time=2;
2.定位到執行效率較低的sql語句
MySQL數據庫支持將慢查詢語句記錄到日志中,供程序猿分析(默認情況下不啟動日志功能)。啟動:進入到MySQL的安裝目錄bin下
mysqld.exe --slow-query-log. //以日志功能方式啟功MySQL
3.通過explain 分析低效率的sql語句的執行情況
explain一款非常重要的工具。這個分析工具可以對sql語句進行分析可以預測sql的執行效率。
4.確定問題並提供相應的優化措施
三:sql語句的幾種類型
ddl(數據庫定義語言):create,alter,drop
dml(數據庫操作語言):insert,delete,update
select
dtl(數據庫事務語言):commit,rollback,savepoint
dcl(數據庫控制語言):grant,revoke
四:數據庫存儲引擎MyISAM和InnoDB比較
1.MyISAM既不支持外鍵也不支持事務。InnoDB都支持。
2.如果存儲引擎是MyISAM的,則當創建一個表後有三個文件:
*.frm(記錄表結構),*.myd(記錄數據),*.myI(記錄索引)
InnoDB只對應一個文件*.frm。數據存儲在ibdata1文件中。
3.對於MyISAM存儲引擎數據庫要定時清理:
執行命令:optimize table 表名;
五:sql語句優化之添加索引
索引的原理:對於MyISAM存儲引擎,索引是添加在.myI文件中。數據庫系統還維護著滿足特定查找算法的數據結構,這些數據結構以某種方式引用(指向)數據,這樣就可以在這些數據結構上實現高級查找算法。這種數據結構,就是索引。再次查詢速度將明顯變快,但是犧牲了刪除,修改,添加表數據的代價。
索引的類型:
1.主鍵索引。主鍵自動的為主索引(類型為Primary)主鍵自帶索引
2.唯一索引(UNIQUE)。唯一性同時又是索引
3.普通索引(Index)
4.全文索引(FULLTEXT)。只有MyISAM存儲引擎支持
5.復合索引(多列和在一起)。create index 索引名 on 表名 (列1,列2);
創建索引:
1.create [UNIQUE / FULLTEXT] index 索引名 on 表名 (列名...);
2.alter table 表名 add index 索引名 (列名...);
3.如果添加主鍵索引:alter table 表名 add primary key(列名);
刪除索引:
1.drop index 索引名 on 表名;
2.alter table 表名 drop index 索引名;
3.如果刪除主鍵索引:alter table 表名 drop primary key;
查看某表的所有索引:
1.show indexes from 表名;
2.show keys from 表名;
3.desc 表名;
!!!PS!!!下列表查詢將不使用索引:
1.如果查詢條件中有or,即使其中有索引也不會使用(or指令要少用)。
2.對於使用多列索引的表,只有最左邊的列才能使用到索引,其余列則不會使用索引。
3.對於使用like查詢,查詢如果是"%aaa"不會使用到索引,"aaa%"則會使用到索引。
4.如果列類型是字符串,那一定要在條件中將數據使用引號引用起來,否則不會使用索引。
5.如果MySQL估計使用全表掃描要比使用索引快,則不使用索引。
查看索引的使用情況:
show status like "Handler_read%";
注意結果:Handler_read_key:這個值越高越好,越高表示使用索引查詢到的次數。Handler_read_rnd_next:這個值越高,說明查詢低效。
六:explain對sql語句的分析
例如:explain select * from emp where empno=2000\G;
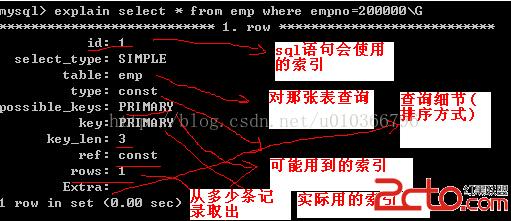
會產生以下信息:
select_type:表示查詢的類型。
table:對哪張表查詢。
type:表示表的連接類型。
possible_keys:表示查詢時,可能使用的索引類型。
key:表示實際使用的索引類型。
key_len:索引的字段長度。
rows:掃描的行數。
Extra:執行情況的描述和說明。
Type的三種類型:
1.ALL:完整的表掃描,通常不好。eg:explain select * from emp\G;
2.system:表僅有一行,這是const連接類型的特例。
3.const:表最多有一個匹配行。
Extra分析:
Notables:不存在表。
Using filesort:當Query中包含ORDER BY操作,而且無法利用索引進行排序。
Using temporary:某些操作必須使用臨時表,常見GROUP BY,ORDER BY。
Using where:不用讀取表中所有信息,僅通過索引就能獲取所需信息。
七:常見sql優化
1.大批量插入數據:
對於MyISAM存儲引擎:
alter table 表名 disable keys; //避免建立大量索引
loading data;
alter table 表名 enable keys;
對於InnoDB存儲引擎:
1.將要導入的數據按照主鍵排序
2.set unique_checks=0; 關閉唯一性校驗
3.set autocommit=0; 關閉自動提交
2.優化group by語句
默認情況,MySQL對所有的group by列進行排序,這與在查詢中指定order by列類似。如果在查詢中包括group by但用戶想要避免查詢結果的消耗,則可以使用order by null禁止排序
eg: select * from dept group by ename order by null;
3.如果在含有or的查詢語句中利用索引,則or之間的每個條件列都必須用到索引,如果沒有索引,則應該考慮增加索引。
4.在精度要求高的應用中,建議使用定點數(decimal)來存儲數值,不使用浮點數(float),以保證結果的准確性。
5.對於MyISAM的存儲引擎的數據庫,如果經常做刪除和修改記錄的操作,要定時執行optimize table 表名;對表進行碎片整理。
6.日期類型要根據實際需要選擇最小存儲的類型(timestamp:4個字節,datetime:8個字節)。