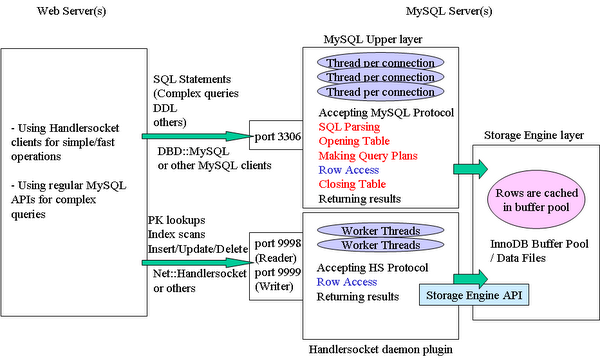
為什麼要分表和分區?
日常開發中我們經常會遇到大表的情況,所謂的大表是指存儲了百萬級乃至千萬級條記錄的表。這樣的表過於龐大,導致數據庫在查詢和插入的時候耗時太長,性能低下,如果涉及聯合查詢的情況,性能會更加糟糕。分表和表分區的目的就是減少數據庫的負擔,提高數據庫的效率,通常點來講就是提高表的增刪改查效率。
什麼是分表?
分表是將一個大表按照一定的規則分解成多張具有獨立存儲空間的實體表,我們可以稱為子表,每個表都對應三個文件,MYD數據文件,.MYI索引文件,.frm表結構文件。這些子表可以分布在同一塊磁盤上,也可以在不同的機器上。app讀寫的時候根據事先定義好的規則得到對應的子表名,然後去操作它。
什麼是分區?
分區和分表相似,都是按照規則分解表。不同在於分表將大表分解為若干個獨立的實體表,而分區是將數據分段劃分在多個位置存放,可以是同一塊磁盤也可以在不同的機器。分區後,表面上還是一張表,但數據散列到多個位置了。app讀寫的時候操作的還是大表名字,db自動去組織分區的數據。
mysql分表和分區有什麼聯系呢?
1.都能提高mysql的性高,在高並發狀態下都有一個良好的表現。
2.分表和分區不矛盾,可以相互配合的,對於那些大訪問量,並且表數據比較多的表,我們可以采取分表和分區結合的方式(如果merge這種分表方式,不能和分區配合的話,可以用其他的分表試),訪問量不大,但是表數據很多的表,我們可以采取分區的方式等。
3.分表技術是比較麻煩的,需要手動去創建子表,app服務端讀寫時候需要計算子表名。采用merge好一些,但也要創建子表和配置子表間的union關系。
4.表分區相對於分表,操作方便,不需要創建子表。
分表的幾種方式:
1、mysql集群
它並不是分表,但起到了和分表相同的作用。集群可分擔數據庫的操作次數,將任務分擔到多台數據庫上。集群可以讀寫分離,減少讀寫壓力。從而提升數據庫性能。
2、自定義規則分表
大表可以按照業務的規則來分解為多個子表。通常為以下幾種類型,也可自己定義規則。
Range(范圍)–這種模式允許將數據劃分不同范圍。例如可以將一個表通過年份劃分成若干個分區。 Hash(哈希)–這中模式允許通過對表的一個或多個列的Hash Key進行計算,最後通過這個Hash碼不同數值對應的數據區域進行分區。例如可以建立一個對表主鍵進行分區的表。 Key(鍵值)-上面Hash模式的一種延伸,這裡的Hash Key是MySQL系統產生的。 List(預定義列表)–這種模式允許系統通過預定義的列表的值來對數據進行分割。 Composite(復合模式) –以上模式的組合使用分表規則與分區規則一樣,在分區模塊詳細介紹。
下面以Range簡單介紹下如何分表(按照年份表)。
假設表結構有4個字段:自增id,姓名,存款金額,存款日期
把存款日期作為規則分表,分別創建幾個表
2011年:account_2011
2012年:account_2012
……
2015年:account_2015
app在讀寫的時候根據日期來查找對應的表名,需要手動來判定。
var getTableName = function() {
var data = {
name: 'tom',
money: 2800.00,
date: '201410013059'
};
var tablename = 'account_';
var year = parseInt(data.date.substring(0, 4));
if (year < 2012) {
tablename += 2011; // account_2011
} else if (year < 2013) {
tablename += 2012; // account_2012
} else if (year < 2014) {
tablename += 2013; // account_2013
} else if (year < 2015) {
tablename += 2014; // account_2014
} else {
tablename += 2015; // account_2015
}
return tablename;
}
3、利用merge存儲引擎來實現分表
merge分表,分為主表和子表,主表類似於一個殼子,邏輯上封裝了子表,實際上數據都是存儲在子表中的。
我們可以通過主表插入和查詢數據,如果清楚分表規律,也可以直接操作子表。
子表2011年
CREATE TABLE `account_2011` ( `id` int(11) NOT NULL AUTO_INCREMENT , `name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL , `money` float NOT NULL , `tradeDate` datetime NOT NULL PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARACTER SET=utf8 COLLATE=utf8_general_ci AUTO_INCREMENT=2 CHECKSUM=0 ROW_FORMAT=DYNAMIC DELAY_KEY_WRITE=0 ;
子表2012年
CREATE TABLE `account_2012` ( `id` int(11) NOT NULL AUTO_INCREMENT , `name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL , `money` float NOT NULL , `tradeDate` datetime NOT NULL PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARACTER SET=utf8 COLLATE=utf8_general_ci AUTO_INCREMENT=2 CHECKSUM=0 ROW_FORMAT=DYNAMIC DELAY_KEY_WRITE=0 ;
主表,所有年
CREATE TABLE `account_all` ( `id` int(11) NOT NULL AUTO_INCREMENT , `name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL , `money` float NOT NULL , `tradeDate` datetime NOT NULL PRIMARY KEY (`id`) ) ENGINE=MRG_MYISAM DEFAULT CHARACTER SET=utf8 COLLATE=utf8_general_ci UNION=(`account_2011`,`account_2012`) INSERT_METHOD=LAST ROW_FORMAT=DYNAMIC ;
創建主表的時候有個INSERT_METHOD,指明插入方式,取值可以是:0 不允許插入;FIRST 插入到UNION中的第一個表; LAST 插入到UNION中的最後一個表。
通過主表查詢的時候,相當於將所有子表合在一起查詢。這樣並不能體現分表的優勢,建議還是查詢子表。
分區的幾種方式
Range:
create table range( id int(11), money int(11) unsigned not null, date datetime )partition by range(year(date))( partition p2007 values less than (2008), partition p2008 values less than (2009), partition p2009 values less than (2010) partition p2010 values less than maxvalue );
List:
create table list( a int(11), b int(11) )(partition by list (b) partition p0 values in (1,3,5,7,9), partition p1 values in (2,4,6,8,0) );
Hash:
create table hash( a int(11), b datetime )partition by hash (YEAR(b) partitions 4;
Key:
create table t_key( a int(11), b datetime) partition by key (b) partitions 4;
新增分區
ALTER TABLE sale_data ADD PARTITION (PARTITION p201010 VALUES LESS THAN (201011));
刪除分區
--當刪除了一個分區,也同時刪除了該分區中所有的數據。
ALTER TABLE sale_data DROP PARTITION p201010;
分區的合並
下面的SQL,將p201001 - p201009 合並為3個分區p2010Q1 - p2010Q3
ALTER TABLE sale_data REORGANIZE PARTITION p201001,p201002,p201003, p201004,p201005,p201006, p201007,p201008,p201009 INTO ( PARTITION p2010Q1 VALUES LESS THAN (201004), PARTITION p2010Q2 VALUES LESS THAN (201007), PARTITION p2010Q3 VALUES LESS THAN (201010) );