為什麼標題要起這個名字呢?commen sence指的是那些大家都應該知道的事情,但往往大家又會會略這些東西,或者對這些東西一知半解,今天我總結下自己在mysql中遇到的一些commen sense類型的問題。
1、varchar(5)可以存儲多少個漢字,多少個字母數字?
相信有好多人應該跟我一樣,對這個已經很熟悉了,根據經驗我們能很快的做出決定,比如說用varchar(200)去存儲url等等,但是,即使你用了很多次也很熟悉了,也有可能對上面的問題做出錯誤的回答。
這個問題我查了好多資料,有的人說是可以存儲5個字符,2.5個漢字(每個漢字占用兩個字節的話),有的人說這個要區分版本,5.0是個分界限,5.0之前是前面說的那樣,5.0之後是可以存儲5個“字”,不區分是數字、英文、漢字,果真是這樣嗎,我們來做個實驗:
復制代碼 代碼如下:
CREATE TABLE `test` (
`name` varchar(5) NOT NULL DEFAULT '',
`info` char(5) NOT NULL DEFAULT '',
PRIMARY KEY (`name`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
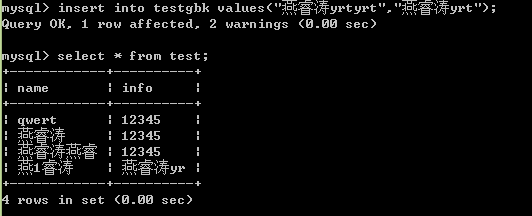
可以看出varchar(5)中的5代表的是5個“字”,而不是5個字節(bytes),當我們存儲長度超過制定長度的時候會將超過的部分“咔嚓”掉,我的mysql版本是5.6,字符集(charset)utf8和gbk是一樣的。

其他版本我電腦上沒有,去官方文檔看看有沒有什麼說明,在官方文檔中查了半天終於發現了點區別:
下面這段來自http://dev.mysql.com/doc/refman/4.1/en/char.html,是對mysq4.1的說明:
復制代碼 代碼如下:
The CHAR and VARCHAR types are declared with a length that indicates the maximum number of characters you want to store. For example, CHAR(30) can hold up to 30 characters. (Before MySQL 4.1, the length is interpreted as number of bytes.)
再看看其他版本的類似的說明:
復制代碼 代碼如下:
The CHAR and VARCHAR types are declared with a length that indicates the maximum number of characters you want to store. For example, CHAR(30) can hold up to 30 characters.
顯而易見了,官方文檔說了,mysql版本小於4.1的時候存儲的時候符合說法:varchar(5)保存5個bytes,及5個英文數字或者2.5個漢字(假設一個漢字2個字節);
mysql版本大於等於4.1的時候varchar(5)中的5不再是字節數了,應該理解為“字”這裡的字的意思是一個漢字和一個英文或者數字“相同對待”
2、mysql中的limit,你真的會用嗎?
你在項目中怎麼使用limit?limit num?還是limit num1,num2?還是其他的?要知道limit使用不同的形式性能差距很大的。
我自己測試了下,在一張innodb表中去使用limit,表中10000條數據,四個字段,id(int)、time(int)、title(varchar)、body(mediumtext),大小大約170M左右,首先關掉查詢緩存,免得查詢緩存對查詢時間有影響,這裡要注意time字段上面加了索引,
復制代碼 代碼如下:
SET @@query_cache_type=ON;
SET GLOBAL query_cache_size=0;
打開Query profiler來查看語句執行所花費的時間
復制代碼 代碼如下:
set profiling=1;
接下來對下面幾個語句進行執行
復制代碼 代碼如下:
a、SELECT id,TIME,title FROM cnblogs WHERE TIME>=1315646940 ORDER BY TIME ASC LIMIT 2000,10
b、SELECT id,TIME,title FROM cnblogs WHERE TIME>=1315646940 ORDER BY TIME ASC LIMIT 10
c、 SELECT id,TIME,title FROM cnblogs ORDER BY TIME ASC LIMIT 3000,10
執行順序a,b,c,a,b,c,c,a,a(這裡需要注意下,雖然我關閉了緩存,但是上一次的查詢還是會緩存,這個可以從Query profiler中看出來,所以進行交叉執行),使用下面的語句查看結果
復制代碼 代碼如下:
SHOW profiles;

從上面的語句執行時間分析可以看出,不考慮緩存因素,當使用limit的時候,"limit begin,num"這種形式比"limit num"這種形式效率低很多,因此,在使用的時候盡可能的使用第二種形式,比如說要循環獲取一個表裡面的數據,一次取出來內從放不下,這個時候就要按照id(或者其他排序字段)進行limit了,我們就可以通過獲取上次的該字段臨界值作為下次取數據的最小值,使用limit num這種形式效率會高很多。