【MySQL筆記】SQL優化利器-explain命令的輸出格式詳解
有MySQL使用經驗的同學在實際項目中可能會遇到SQL慢查詢的場景,有些場景很容易定位問題所在(如單表操作有慢查詢SQL時,仔細check SQL語句通常很容易定位索引問題),而有些復雜業務場景下(如多表聯合查詢幾十個字段並做group或sort等操作),人工check SQL語句通常很難發現SQL瓶頸根源。這個時候,MySQL提供的explain命令就派上用場了。
本筆記主要對explain的輸出結果做說明,並給出根據explain輸出對SQL做優化的思路。
1. EXPLAIN語法及用途
explain命令的語法說明見官網文檔,這裡略過。
該命令主要作用是輸出MySQL的optimizer對SQL的執行計劃,也即,MySQL會解釋如何處理輸入的SQL(是否使用索引,使用哪個索引,多表以什麼順序及什麼關聯字段做join)。
explain的提示可以幫助大家意識到哪些字段應該建索引,也可以幫大家確認SQL執行時optimizer是否會以合理的順序來join多張表。比如若有類似這樣的SQL語句:
select t1.id, t2.link, t3.detail from t1, t2, t3 where t1.id < 100 and t1.id = t2.base_id and t3.link_sign = t2.sign;
該語句執行時,optimizer不一定會以from列出的表順序來join這3張表,而表的join順序很可能會影響SQL性能。
這種場景下,如果想讓optimizer以from語句列出的表順序做join,有2種方法:
1) 在select關鍵字後添加STRAIGHT_JOIN來提示optimizer按from列出的表順序來join,具體語法見SELECT文檔
2) 調整sql where條件中各表關聯字段在等號前後的位置
本文下面的內容會說明如何通過explain輸出來確定多表join時optimizer對各表的執行次序,以及如何調整SQL來影響optimizer的執行計劃。
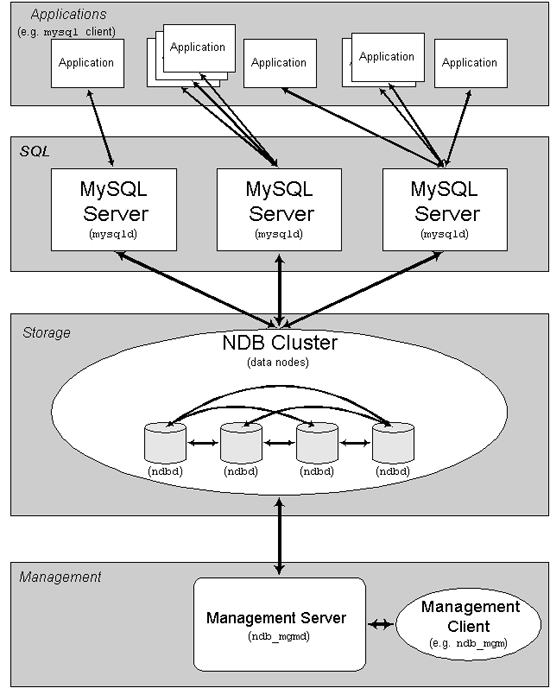
2. EXPLAIN輸出格式說明
explain命令會為SQL中出現的每張表返回一行信息來說明optimizer將會如何操作這張表,其輸出中列出的表次序也是MySQL實際執行SQL時對各表的處理順序。
MySQL以
nested-loop算法處理所有的join操作,算法原理說明在這裡,對認識join的行為有幫助,建議理解。
explain針對每張表輸出的每行記錄均包含下面幾個字段:
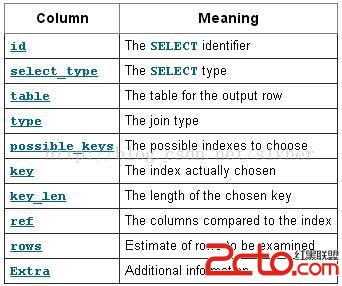
下面分別進行說明。
1) id
該字段標識select語句id,若SQL中只有1個select語句(即使是多表關聯查詢),則該值為1,否則依次遞增;若SQL是union的結果,則該值為NULL。
2) select_type
該字段說明select語句的類型,其可能的取值如下圖(來自官網文檔):

其中,simple是最常見的類型,表明SQL只包含1個select語句;derived表明該行代表的數據表(derived table)其實是from子句中包含的子查詢的輸出結果;其余類型較易理解,閱讀官方文檔即可,這裡不贅述。
3) table
該字段表明explain輸出的每行所代表的數據集來自哪張表,其值通常是具體的表名,當數據集是union的結果時,其值可能
是<unionM,N>,當數據集來自derived table時,其值可能是<derivedN>。這裡提到的M或N均是id字段的值。
4) type
該字段表明各表是如何被join的,其取值比較復雜,詳細可參考官網文檔。這裡只列出最常見的幾種取值。
a. system/const
const表明上述"table"字段代表的數據集中,最多只有1行記錄命中本步執行計劃的查詢條件,例如這步執行計劃的sql的where
子句以某張表的primary key或unique index與常數做比較時,該執行計劃對應的type字段取值就是const。
system只是const值的一個特例,它表示本步執行計劃要操作的數據集中只有1行記錄。
它們只可能出現在單表查詢SQL的type字段取值中。
b. eq_ref
該值表明本步執行計劃操作的數據集中關聯字段是索引字段且
只有1條記錄符合上步執行計劃操作的數據集的關聯條件。
這
是對多表做關聯查詢時,可能得到的最優的join類型(因為它通常表明關聯的字段是本步執行計劃要操作的表的primary key或unique index)。
c. ref
該值表明本步執行計劃操作的數據集中關聯字段是索引字段但
不只有1條記錄符合上步執行計劃操作的數據集的關聯條件。
符合關聯條件的記錄不只1條表明關聯字段非primary key或unique index,當符合關聯條件的記錄數比較少時,這種join_type='ref'的場景還是比較合理的,但它顯然不如join_type='eq_ref'高效。
d. ref_or_null
該join type類型與ref的場景類似,但它表明MySQL會對包含NULL值的字段做額外搜索。例如下面SQL的join type就是ref_or_null:
SELECT * FROM ref_table WHERE key_column=expr OR key_column IS NULL;
e. index_merge
該值表明MySQL會對本步執行計劃進行index merge優化,觸發index merge的SQL通常包含'or'操作,常見實例如下:
SELECT * FROM tbl_name WHERE key1 = 10 OR key2 = 20;
SELECT * FROM tbl_name WHERE (key1 = 10 OR key2 = 20) AND non_key=30;
SELECT * FROM t1, t2 WHERE (t1.key1 IN (1,2) OR t1.key2 LIKE 'value%') AND t2.key1=t1.some_col;
SELECT * FROM t1, t2 WHERE t1.key1=1 AND (t2.key1=t1.some_col OR t2.key2=t1.some_col2);
f. range
該值表明本步執行計劃
只操作單表且符合查詢條件的記錄不只1條,可能出現在有in或between操作的SQL中。
只限於單表操作場景也是其與前面提到的join_type取值為'ref'場景的區別,因為ref可能出現在單表/多表join操作場景下。
g. ALL
該值表明本步執行計劃會對數據集做全表掃描,這是必須做優化的場景。通常可以通過對某些字段合理建索引來避免全表掃描。
h. index
該值表明MySQL執行本步計劃時掃描的是index tree,而ALL則是掃全表。
它可能在兩種場景下出現:
case1. 本步計劃查詢數據集時select語句需要返回的字段是該數據集索引字段的最左前綴匹配集。如table A中已建立含2個字段的聯合索引(f1, f2),則select f1 from A where f2 = 'yyy'可能會觸發MySQL掃描index tree,這種情況下,執行計劃的Extra字段會包含"Using index"來表明它掃描的是index tree,因為f1是(f1, f2)最終前綴匹配集中的1個元素;而select f2 from A where f2 = 'yyy'則會掃描全表。
case2. 本步計劃按照索引順序進行全表掃描來查找符合條件的數據。這種情況下,執行計劃的Extra字段不會包含"Using index",這種全表掃描也是必須優化的場景。
5) possible_keys
該字段的值是可能被MySQL用作索引的字段,若值為NULL,則沒有字段會被用作索引,因此查詢效率不會高,這種情況下,需要優化數據表的索引結構。
6) key
該字段的值是MySQL真正用到的索引。
值得注意的是:該字段的值有可能不是possible_keys列出的候選索引字段,例如,當前查詢SQL要返回的字段是數據表某索引字段的最左前綴匹配字段,但SQL的where條件中沒有使用數據表的索引字段,則此時possible_keys可能為NULL,而key字段的值可能是那個能cover住待查詢字段的數據表索引字段,此時,MySQL會掃描索引樹,雖然低效,但比起掃描全表還是要快。這種場景也正是本文前面解釋join_type='index'時提到的case1。
此外,在select語句中借助"force index或"use index"可以強制MySQL使用possible_keys中列出的候選索引字段。
7) key_len
該字段的值表明上述key字段的length,當MySQL將某聯合索引字段作為SQL執行時用到的索引時,key_len字段可以暗示MySQL真正在什麼程度上(多長的最左前綴匹配字段)使用了該聯合索引。若key字段的值為NULL,則key_len字段值也為NULL。
8) ref
該字段的值表明數據表中的哪列或哪個constants會被用於與key字段指定的索引做比較。
9) rows
該字段的值表明MySQL執行該步計劃對應的query時必須掃描的行數。
這個值對於SQL優化非常具有參考意義,通常情況下,該值越小查詢效率越高。
10) Extra
該字段的值包含了MySQL執行query時的其它額外信息。該字段可能的取值情況較多,詳細情況可參考官網文檔的說明。
除explain外,MySQL還支持explain extended命令來分析optimizer的執行計劃,後者在輸出結果中多1個filtered字段,且可以用show warnings語句來分析輸出的extra信息。
3. 如何根據explain的輸出優化SQL
如果理解了explain輸出結果中每個字段背後的含義,則據此優化SQL性能會變得高效且有依據。
在工程實踐中利用explain來trouble shoot低效SQL的思路,跟工程師的經驗和能力有關,這裡推薦幾篇技術資料來拋磚引玉。
1) Oreilly官網中的一篇PDF分享:Explain Demystified
2) slideshare上的一篇分享文檔:Mysql Explain Explained,該文檔循序漸進地解釋了MySQL explain的輸出及據此優化SQL的典型思路,值得一讀。
3) 美團官方技術博客的一篇文章:MySQL索引原理及慢查詢優化,文中介紹了B+Tree的原理,並給出了幾個利用explain來優化SQL的工程場景,也值得精讀。