 結果字段解釋:
vcmRlcj0="1" cellpadding="2" cellspacing="0">
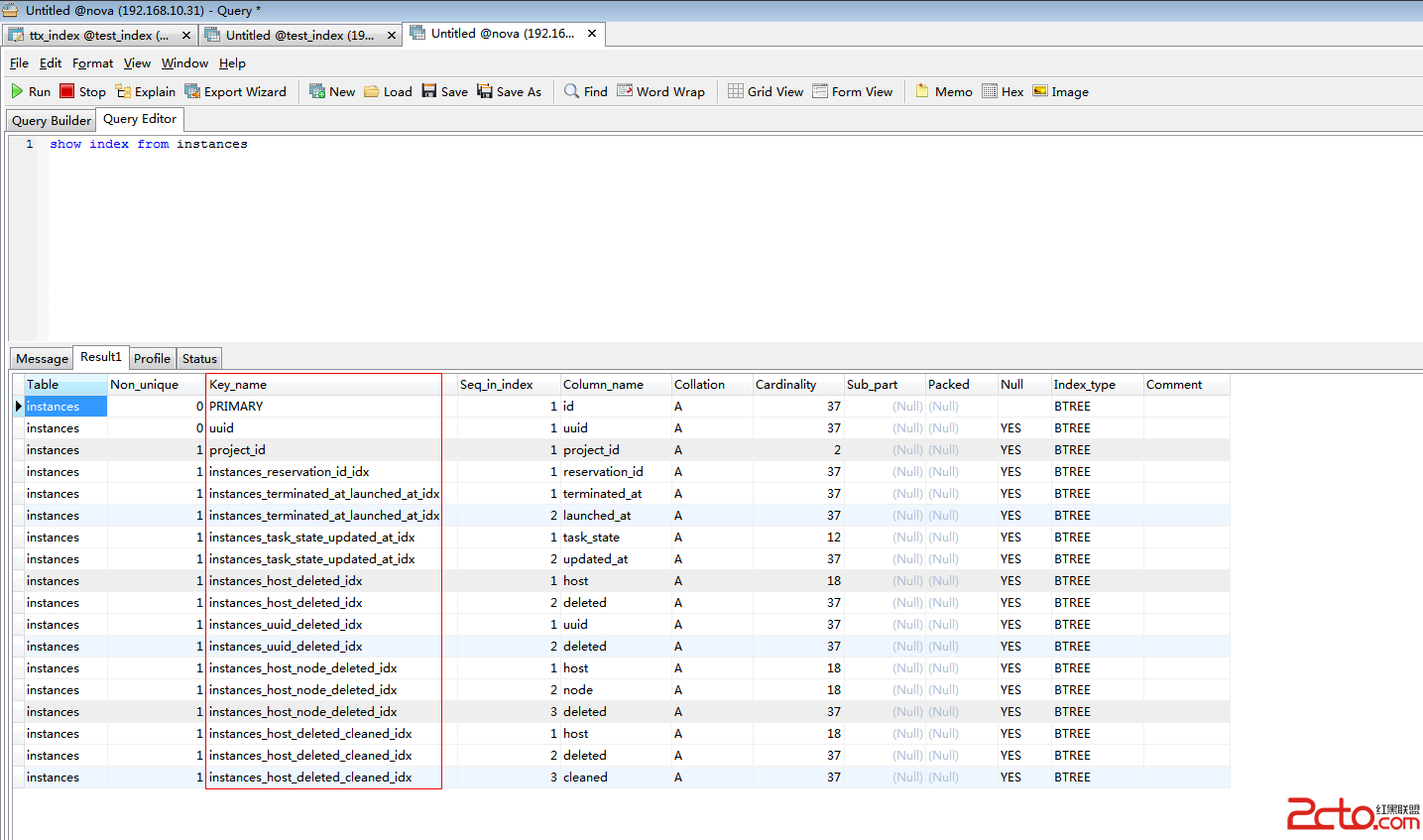
Table:數據庫表名
Non_unique:索引不能包括重復詞,則為0。可以,則為1。
Key_name:索引的名稱。
結果字段解釋:
vcmRlcj0="1" cellpadding="2" cellspacing="0">
Table:數據庫表名
Non_unique:索引不能包括重復詞,則為0。可以,則為1。
Key_name:索引的名稱。 查詢索引:
查詢索引:
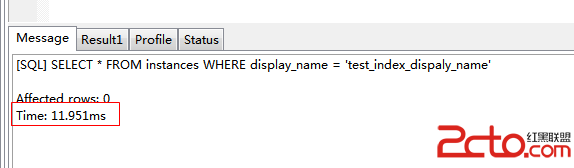
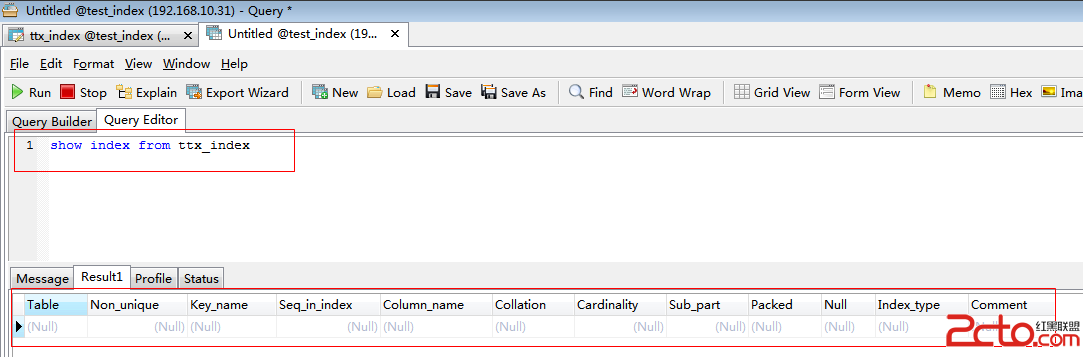 結果顯示沒有索引。
結果顯示沒有索引。
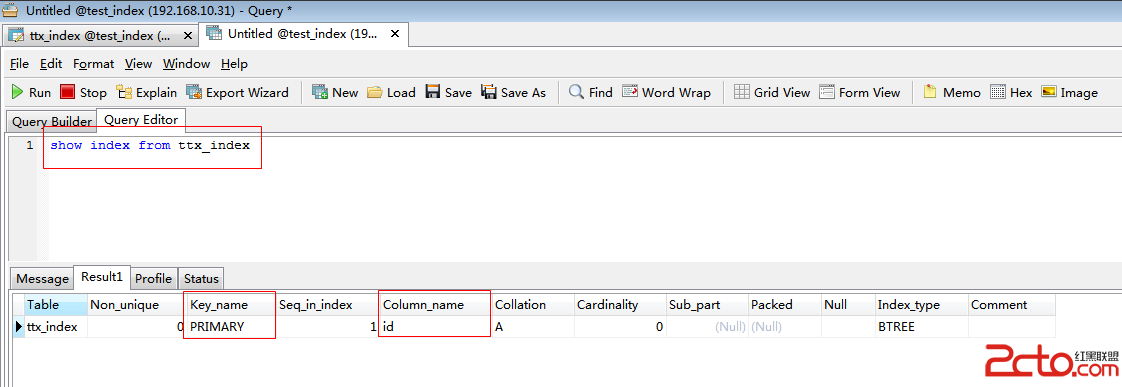
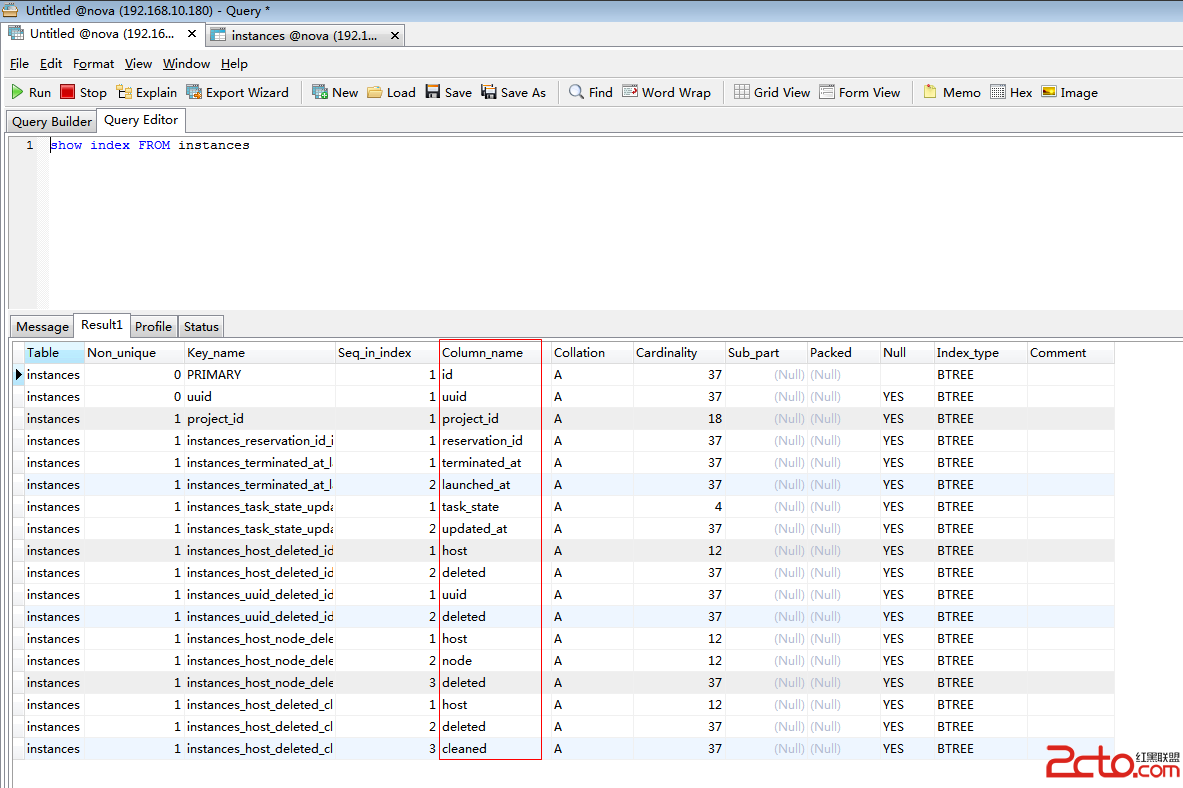
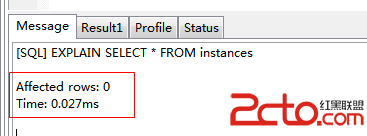
 根據上述結果,可以此查詢花了0.027ms,沒有可用的索引。
根據上述結果,可以此查詢花了0.027ms,沒有可用的索引。
table:顯示這一行的數據是關於哪張表的
type:這是重要的列,顯示連接使用了何種類型。從最好到最差的連接類型為const、eq_reg、ref、range、indexhe和ALL
possible_keys:顯示可能應用在這張表中的索引。如果為空,沒有可能的索引。可以為相關的域從WHERE語句中選擇一個合適的語句
key: 實際使用的索引。如果為NULL,則沒有使用索引。很少的情況下,MYSQL會選擇優化不足的索引。這種情況下,可以在SELECT語句中使用USE INDEX(indexname)來強制使用一個索引或者用IGNORE INDEX(indexname)來強制MYSQL忽略索引
key_len:使用的索引的長度。在不損失精確性的情況下,長度越短越好
ref:顯示索引的哪一列被使用了,如果可能的話,是一個常數
rows:MYSQL認為必須檢查的用來返回請求數據的行數
Extra:關於MYSQL如何解析查詢的額外信息。將在下表中討論,但這裡可以看到的壞的例子是Using temporary和Using filesort,意思MYSQL根本不能使用索引,結果是檢索會很慢
extra列返回的描述的意義:
Distinct:一旦MYSQL找到了與行相聯合匹配的行,就不再搜索了
Not exists: MYSQL優化了LEFT JOIN,一旦它找到了匹配LEFT JOIN標准的行,就不再搜索了
Range checked for each Record(index map:#):沒有找到理想的索引,因此對於從前面表中來的每一個行組合,MYSQL檢查使用哪個索引,並用它來從表中返回行。這是使用索引的最慢的連接之一
Using filesort: 看到這個的時候,查詢就需要優化了。MYSQL需要進行額外的步驟來發現如何對返回的行排序。它根據連接類型以及存儲排序鍵值和匹配條件的全部行的行指針來排序全部行
Using index: 列數據是從僅僅使用了索引中的信息而沒有讀取實際的行動的表返回的,這發生在對表的全部的請求列都是同一個索引的部分的時候
Using temporary 看到這個的時候,查詢需要優化了。這裡,MYSQL需要創建一個臨時表來存儲結果,這通常發生在對不同的列集進行ORDER BY上,而不是GROUP BY上
Where used 使用了WHERE從句來限制哪些行將與下一張表匹配或者是返回給用戶。如果不想返回表中的全部行,並且連接類型ALL或index,這就會發生,或者是查詢有問題不同連接類型的解釋(按照效率高低的順序排序)
system 表只有一行:system表。這是const連接類型的特殊情況
const:表中的一個記錄的最大值能夠匹配這個查詢(索引可以是主鍵或惟一索引)。因為只有一行,這個值實際就是常數,因為MYSQL先讀這個值然後把它當做常數來對待
eq_ref:在連接中,MYSQL在查詢時,從前面的表中,對每一個記錄的聯合都從表中讀取一個記錄,它在查詢使用了索引為主鍵或惟一鍵的全部時使用
ref:這個連接類型只有在查詢使用了不是惟一或主鍵的鍵或者是這些類型的部分(比如,利用最左邊前綴)時發生。對於之前的表的每一個行聯合,全部記錄都將從表中讀出。這個類型嚴重依賴於根據索引匹配的記錄多少—越少越好
range:這個連接類型使用索引返回一個范圍中的行,比如使用>或<查找東西時發生的情況
index: 這個連接類型對前面的表中的每一個記錄聯合進行完全掃描(比ALL更好,因為索引一般小於表數據)
ALL:這個連接類型對於前面的每一個記錄聯合進行完全掃描,這一般比較糟糕,應該盡量避免
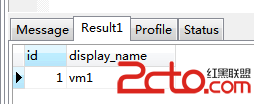
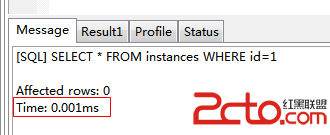
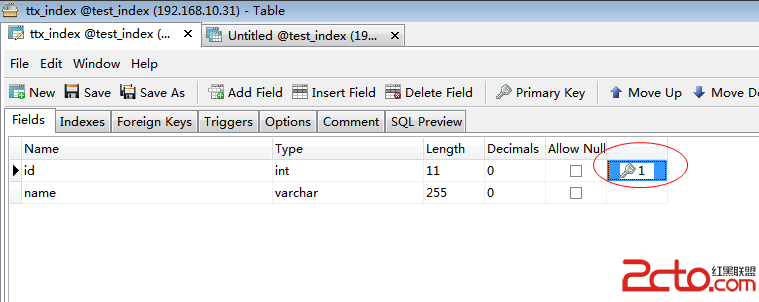
 從上圖可以,該sql語句走了索引。因為該表中id為主鍵,mysql會自動創建索引,因此當將id作為where條件查詢時,數據庫會自動走索引。
從上圖可以,該sql語句走了索引。因為該表中id為主鍵,mysql會自動創建索引,因此當將id作為where條件查詢時,數據庫會自動走索引。