如果你也遇到了這個問題,咱先不談原因,在PC自帶的cmd中(或者是mysql安裝版安裝後的Command Line客戶端,又或者是工作用的SecureCRT)試試效果。進入mysql環境,從頭開始操作。假設你的客戶端編碼是gbk或者utf8(這麼說太不嚴謹了,怎麼能假設呢,但是一般來說假如安裝後沒動過,cmd是gbk編碼,mysql安裝後的Command Line客戶端沒裝不記得,CRT看看Session Options裡面的編碼設置,一般也會設置成utf8),執行一些語句:
1. 設置編碼客戶端、連接、返回結果的字符集,先設置成latin1,
2. 然後執行下面的看下各個字符是不是這樣的,
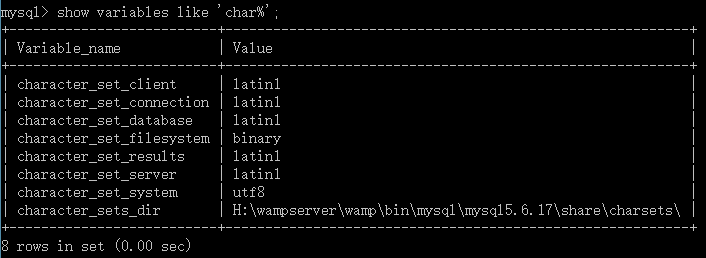
如果你的character_set_client、character_set_connection、character_set_results不是latin1,可以這樣執行,把他們單個分別設置成latin1,比如設character_set_client,其他兩個一樣,確保這三個均是latin1(第一步的sql語句實際做的就是這件事),
3. 單獨創建一個數據庫db_latin1,當然是很簡單的了,測試嘛,創建時就設置數據庫的編碼的為latin1,
4. 在它下面創建一張表tab_latin1,字符集也設置成latin1,這裡不設置字符也行,數據庫級已經設置了,這裡只創建一個name字段,

5. 插入一些中文字符到表中,先說明,本機的cmd編碼是gbk,查看方法是右鍵屬性->選項,看下當前代碼頁即可知道,

6. 查看下結果
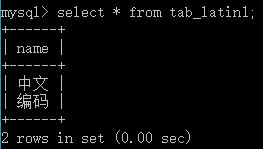
看吧,正常顯示中文了~~~
OK,都到這兒了你就不想知道“為什麼我那樣設置就是不行”麼,當然得往下看看是不。上圖:
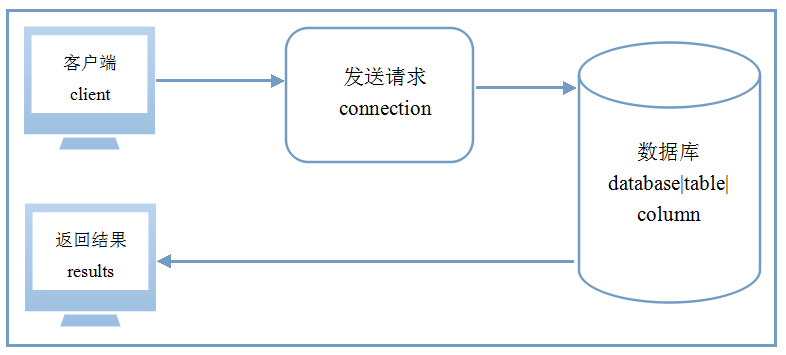
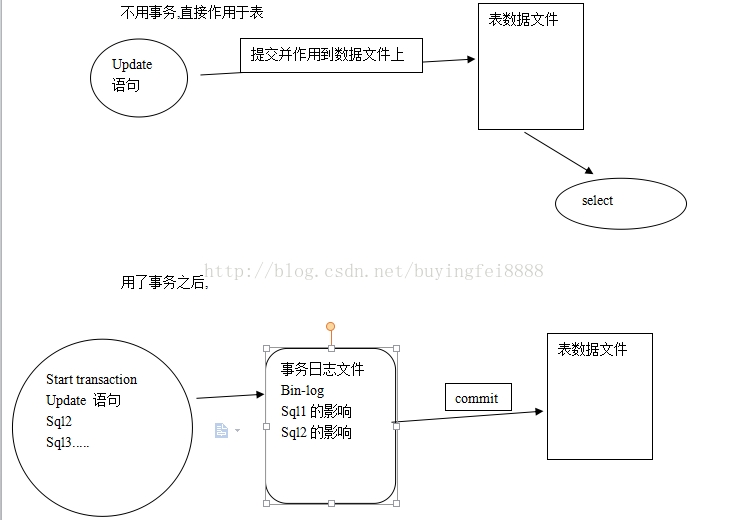
我們知道mysql是客戶端-服務器軟件,每次操作都是客戶端向服務端發送請求,然後可能會返回一些結果,這之間插入的字符經過了一系列轉換。首先供我們編輯的客戶端本身就有一種編碼,比如PC端的命令行默認是gbk,PC自帶notepad新建文本文件默認是ANSI,常用的文本編輯器如notepad++,我們可能會設置默認編碼為utf8,就是說在編輯器上編輯,你所看到的本身就是一種編碼了。
1. 在客戶端編輯後,首先轉化為client對應的字符集,即上面打印出的character_set_client變量指示的字符集;
2. 向數據庫服務發送請求,發送過程中,轉化為connection對應連接字符集,即character_set_connection變量對應字符集;
3. 存儲到數據庫中,轉化為數據庫存儲的字符集,可能是server級別(character_set_server)、database級別(character_set_database)或者表級別和列級別(這裡還要細說下);
4. 數據庫收到請求,執行查詢得到結果,再次轉化為results對應字符集,即character_set_results變量所指,該結果返回到客戶端上;
5. 結果來了,是按照results字符集編碼的,那我們讓這個結果顯示的客戶端工具它支持什麼樣的編碼也很重要,這決定了它如何去解碼結果。假如這個結果是utf8編碼,返回給某客戶端了,但這個客戶端只有ANSI編碼,那當然不能顯示正常,比如它返回到SecureCRT,結果顯示不正常,但是CRT支持多種編碼,我們手動將它調成utf8編碼,那它就又顯示正常了,所以嚴格來說這一步算不上,只是跟客戶端條件有關,畢竟當我們知道後將客戶端調整成正常的編碼或者本來就支持轉換results的編碼後,這一步就不存在了。
在上面的第3步中,從連接字符集編碼轉化為數據庫存儲使用的編碼時,要分幾種情況,一般我們在裝mysql時,特別是32位安裝版本時,中間有一個選擇編碼的步驟,大多會選擇utf8編碼,這時系統就可能會把一系列的字符集變量均設置成了utf8,比如character_set_server、character_set_connection、character_set_database等等。也就是說這個character_set_server變量在你啟動mysql服務的事先就被設置好了,我們可以稱它為服務器級編碼,那我們在建表前,先得創建數據庫,在創建數據庫時,我們知道可以顯式指定編碼的,比如最開頭時我創建時顯式指定采用latin1字符集,也可以不指定,如果不指定的話,它將采用服務器級的字符集,即character_set_server,同理在創建表時,也可不指定編碼,不指定的話,采用數據庫級編碼,級character_set_database,更加同理在創建表中列字段時也可指定編碼,不指定編碼的話將采用表級別字符集,因此有這麼一個繼承關系在這:
character_set_server => character_set_database => character set in table(無此變量) => character set column(無此變量)
mysql創建表可以細化到這四個層次,不是每一層都必須指定,默認使用上一級的字符集(字符校對規則也是這樣的,collation,稍後說明)。
那麼有沒有可能character_set_server沒有指定呢,如果任何地方都沒指定,特別是非安裝版中,如果忘了,mysql在編譯時默認采用latin1,為了應對這種情況,特別是非安裝版本中在配置mysql時,經常需要手動配置mysql配置文件mysql.ini,其中就有大概這麼一項:
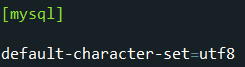
在配置文件中默認采用的字符集,因此如果指定了character_set_server默認就會采用它,這樣其他層次都不指定的話依次繼承。
其他的,character_set_filesystem:把操作系統上的字符轉換成此字符集,即把character_set_client轉換成character_set_filesystem,默認為binary則不轉換,character_set_system:此變量總是utf8,為存儲系統元字符的字符集,如表名、列名、用戶名等,character_set_dir:很明顯是指示一個目錄的變量,打開這個目錄,裡邊存放的是mysql的各種用於編碼字符集的xml格式文件。以上三個值在解決亂碼問題時基本可忽視。
好,轉換流程和各變量的含義清楚了,就要搞清楚哪些字符集編碼之間可以轉換,能轉換可能也是在一定編碼范圍內的字符能轉換,不至於出現亂碼甚至損壞。損壞了就再也無法正確顯示了,哪怕設置是正確的,還原是還原不回來的。當然關於字符之間的轉化情況很多,字符集有那麼多種,隨便兩個之間都可以轉換一下試試,不能一一列舉,可以參考這篇文章:http://www.imcjd.com/?p=1324,它針對經常用到的字符轉換作了一些轉換比較和測試。
其中,可以了解到,完全匹配的轉換是肯定沒有問題的,比如,gbk->gbk,utf8->utf8,latin1->latin1;轉換為單字節編碼的latin1也沒問題,比如gbk->latin1、utf8->latin1;單字節編碼(latin1)轉為其他在某些編碼某些范圍內可能會出現轉換不全,比如latin1->gbk(很特殊的中文),或者編碼長度改變,比如latin1->utf8,變為2、3等字節數。
下面引用另一篇文章(http://hi.baidu.com/cuttinger/item/f4e79726a60ab450c28d59da)中的一段。
【Latin1是一種很常見的字符集,這種字符集是單字節編碼,向下兼容ASCII,其編碼范圍是0x00-0xFF,0x00-0x7F之間完全和ASCII一致,0x80-0x9F之間是控制字符,0xA0-0xFF之間是文字符號。很明顯,Latin1覆蓋了所有的單字節,因此,可以將任意字符串保存在latin1字符集中,而不用擔心有內容不符合latin1的編碼規范而被拋棄。——gbk和utf8是多字節編碼,沒有這種特性。
mysql使用者經常利用Latin1的這種全覆蓋特性,將其它類型的字符串,gbk,utf8,big5等,保存在latin1列中。保存的過程中沒有數據丟失,只要原樣取出來,便又是合法的gbk/utf8/big字符串。如果將gbk字符串保存在utf8列中,則gbk字符串中那些不符合utf8編碼格式的內容,會被拋棄,保存的內容無法原樣取出,數據實際上遭到了破壞。
綜上,如果我們看到一個字段的字符集是latin1的,那麼,他保存的可能是任何編碼的字符串;而一個字段的字符集是utf8或者gbk的,那麼他保存的就應該是utf8或gbk的——除非數據庫的使用者用錯了。】
我沒有深入學習過utf8、gbk編碼的細節,極可能說的不准確,只知道簡單的ASCII編碼(-_-),但是可以了解個全局情況。從上面來看,latin1的單字節編碼方式很有用,其他的編碼可以轉換為它再轉回去而不至於丟失內容。所謂單字節編碼就是挨著一個個來,我理解是,比如聖誕節到了,你要送妹子一箱蘋果,為制造浪漫,商鋪提供兩種包裝方式,一是按個數來,即單個蘋果包裝進一個盒子,來一個包裝一個,這樣,妹子在拆完所有的盒子後完完整整的可以還原為一個個完整的和一箱完好無損的蘋果,二是按重量來,每個盒子限重2兩、3兩、6兩,這樣在包裝時,若剛好重3兩的當然可以完整的放進一個盒子,但是若不夠或者多了,勉不了要切開蘋果,或者再往盒子中添加其他的部分蘋果,這樣的話,妹子再無論怎樣拆開盒子,都會得到一箱殘缺不堪的蘋果了,因為你在按照這種包裝方式進行時,已經破壞了單個蘋果的完整性,現在還原不回來了~我們的字符集編碼轉換就是在做這種重新包裝的工作,latin1恰好就像單個蘋果包裝,而utf8就像第二種方式。
而剛才說的完全匹配的情況是,你去買一箱蘋果,箱子裡邊的所有蘋果重量已經恰好要麼是2兩,要麼是3兩或6兩的,這樣再按重量包裝時當然就恰好分配了,得到的仍然是完整的蘋果。
所以說白了,兩種可行的方式是:
1. 所有變量均設置成latin1(set names latin1;),這樣,即便我們所使用的編輯客戶端編碼多樣(gbk或utf8),最終可以得到正確結果;
2. 所有的設置成gbk或者gb2312(國標編碼,只用於簡體中文),采用完全匹配;
3. 針對中間的轉換過程,比如gbk輸入,將character_set_client、character_set_connection視為latin1,character_set_database設為gb2312,建表時定字符集為gb2312,character_set_results也可以定為gb2312,當然這只是雞肋,本質上還是用了latin1,gbk轉latin1再轉gb2312時只適用於簡體。
最後,關於字符集校對規則,只了解一點。在我們設置mysql字符集時,mysql會自動給一個對應的校對規則,比如設置charset為utf8,默認的collation就是utf8_general_ci,gb2312字符集對應gb2312_chinese_ci,mysql命令查看所有校對規則是show collation,查看某一對應字符集的校對規就是show collation like 'utf8%'了。
字符集校對是一種對使用當前字符集時采用的排序、對比方式,即便同一種字符集,在不同的地區也是不同的對比方式,所以才有校對這麼一說,比如utf8_general_ci,這個ci就是case insensitive,即大小寫不敏感,采用它校對時,查詢某字段值匹配時,大小寫的記錄都會出現,當然還有其他的規則,utf8打印出來一大坨,不細研究了~