更新數據後,會將dirty page放到innodb buffer cache中。此時頁的checksum值會發生變化。
頁的頭部fileheader部分有checksum項,名為file_page_space_or_checksum。
頁的尾部filetailer部分也有用來比較checksum的項,名為file_page_end_lsn。
它們使用特殊的checksum函數來比較,以此來驗證頁的完整性。
這裡我們簡單的理解為等值比較。

這個時候執行刷新磁盤操作,16KB的頁,如果只寫了其中的8KB,這時候發生了意外狀況,服務器掉電、MySQL示例突然停掉。這時候就會發生partial page write的問題,即只有頁的部分數據同步到了磁盤上面。
checksum無法通過。
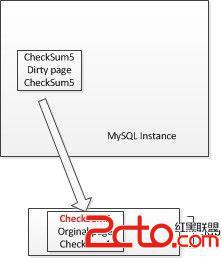
其實MySQL的Innodb以及Oracle數據庫的redo log,不是記錄純物理的操作,而是物理和邏輯結合的日志。(這樣可以減少redo的生成)
物理到page,也就是page具體在硬盤上的具體位置。
後面對於page的操作,則是根據自己的格式邏輯存儲的(應用的時候需要通過特定的解析函數),比如說向page裡面插入一條記錄。
當然Oracle數據庫也是類似的,物理,只到block級別。
所以說,當page 損壞之後,其實應用redo是沒有意義的。
這時候無法使用redo來恢復,因為原始頁已經損壞了.
會發生數據丟失。
寫髒數據到磁盤的時候,會先通過memcpy函數將dirty page拷貝到大小為2MB 的double write buffer內存區域中。
然後double write buffer第一步先將這2MB的數據每次1MB寫入到共享表空間中分配的double write區域中。
第二步才將數據頁寫到數據文件中去。
當第二步過程中發生故障,也就是發生partial page write的問題。
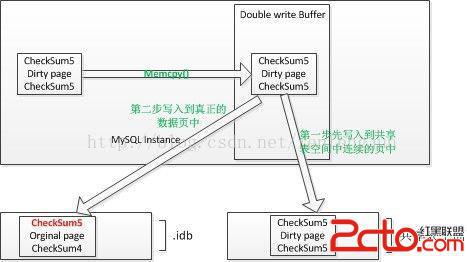
先檢查頁內的checksum是否相同。
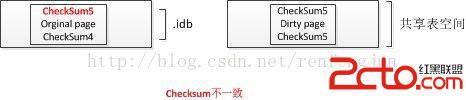
不一致,則直接從doublewrite中恢復。

當然,如果頁的checksum通過,但是與doublewrite中的checksum不同,則可以直接應用redo log來執行恢復操作。
本文只介紹關於double write相關的內容,崩潰恢復的過程要復雜的多,想要了解更多可以到下面的鏈接中找到答案。