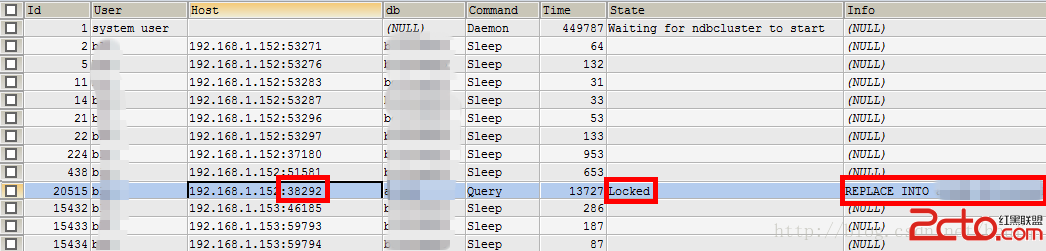
在我們做開發的中效率一直是個問題,特別是對於很多大數據量操作,今天我們碰到一個要隨機查詢數據,一開始我們可能想到最簡單的order by rand() 來操作但效率不敢恭維啊
最近由於需要大概研究了一下MYSQL的隨機抽取實現方法。舉個例子,要從tablename表中隨機提取一條記錄,大家一般的寫法就是:SELECT * FROM tablename ORDER BY RAND() LIMIT 1。
有兩個方法可以達成以上效果.
1.新建一個表,裡面存著 -5 至 5 之間的數.再利用order by rand()得到隨機數.
#建立指定范圍數據表
#auther: 小強(占卜師) #date: 2008-03-31 create table randnumber select -1 as number union select -2 union select -3 union select -4 union select -5 union select 0 union select 1 union select 2 union select 3 union select 4 union select 5 #得到隨機數 #auther: 小強(占卜師) #date: 2008-03-31 select number from randnumber order by rand() limit 1
#一句sql語句搞定 #auther: 小強(占卜師) #date: 2008-03-31 復制代碼 代碼如下: SELECT ROUND((0.5-RAND())*2*5) #注釋 #0.5-rand()可以得到-0.5 至 +0.5的隨機數 #(0.5-rand())*2可以得到-1 至 +1的隨機數 #(0.5-rand())*2*5可以得到-5 至 +5的隨機數 #ROUND((0.5-RAND())*2*5)可以得到-5 至 +5的隨機整數
SELECT * FROM `table` WHERE id >= (SELECT floor(RAND() * (SELECT MAX(id) FROM `table`))) ORDER BY id LIMIT 1;
SELECT * FROM `table` WHERE id >= (SELECT floor( RAND() * ((SELECT MAX(id) FROM `table`)-(SELECT MIN(id) FROM `table`)) + (SELECT MIN(id) FROM `table`))) ORDER BY id LIMIT 1; SELECT * FROM `table` AS t1 JOIN (SELECT ROUND(RAND() * ((SELECT MAX(id) FROM `table`)-(SELECT MIN(id) FROM `table`))+(SELECT MIN(id) FROM `table`)) AS id) AS t2 WHERE t1.id >= t2.id ORDER BY t1.id LIMIT 1;