MySQL系列:innodb引擎分析之基礎數據結構
近一年來一直在分析關於數據庫相關的源碼,前段時間分析了levelDB的實現和BeansDB的實現,這兩個數據庫網絡上分析的文章很多,也都比較分析的比較深,所以也就沒有太多必要重復勞動。最近開始關注關系數據庫和MYSQL,當然主要還是數據庫存儲引擎,首先我還是從innodb這個最流行的開源關系數據庫引擎著手來逐步分析和理解。我一般分析源碼的時候都是從基礎的數據結構和算法逐步往上分析,遇到不明白的地方,自己按照源碼重新輸入一遍並做對應的單元測試,這樣便於理解。對於Innodb這樣的大項目,也應該如此,以後我會逐步將具體的細節和實現寫到BLOG上。我分析Innodb是以MySQL-3.23為藍本作為分析對象,然後再去比較5.6版本的改動來做分析的。這樣做有個好處就是先理解相對基礎的代碼容易,在有了基本概念後再去理解最新的改動。以下是我對innodb基礎的數據結構和算法的理解。
1.vector
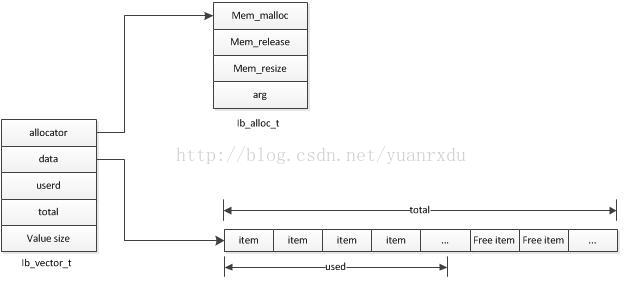
innodb的vector是個動態數組的數據結構,和c++的STL用法相似,值得一提的是vector的內存分配可以通過函數指針來指定是從heap內存池堆上分配內存還是用OS自帶的malloc來分配內存。內存分配器的結構為:
struct ib_alloc_t {
ib_mem_alloc_t mem_malloc; //分配器的malloc函數指針
ib_mem_free_t mem_release; //分配器的free函數指針
ib_mem_resize_t mem_resize; //分配器的重新定義堆大小指針
void* arg; //堆句柄,如果是系統的malloc方式,這個值為NULL
<span style="white-space:pre"> </span>};vector內部集成了排序功能函數,其排序的算法是通過qsort(快速)來進行排序。
vector內存結構:
2.內存list
innodb的list數據結構是個標准的雙向鏈表結構,ib_list_node_t當中有指向前一個node的prev和指向後一個
node的next,list的內存分配可以通過heap內存堆來分配,也可以通過系統的malloc來分配。就看是采用
ib_list_create_heap來創建list愛是永ib_list_create來創建list。但是內部的ib_list_node_t的內存分配是通過
heap來分配的。
ist的內存結構:
3.FIFO-queue
innodb的FIFO queue是個多線程的消息隊列,可以有多個線程向queue中添加消息,可有多個線程同時讀取queue中的消息並進行處理。queue的mutex是保證同時只有一個線程在操作(讀或者寫)queue的items鏈表,Z喎?http://www.Bkjia.com/kf/ware/vc/" target="_blank" class="keylink">vc19ldmVudMrH0LTP37PMzeqzybrzzajWqsv509C2wc/fs8y/ydLUvfjQ0HF1ZXVltcS2wcrCvP6jrNKyvs3Kx8u1o6zWu9PQz/JxdWV1ZdC0zeqzydK7uPbP+8+io6yyxbvht6LLzWV2ZW500MW6xbj4tsHP37PMoaNxdWV1ZbXEz/vPoru6s+XH+MrHssnTw2liX2xpc3RfdMC01/a05rSitcSjrNK7sOPQtLXEyrG68tC01NpsaXN0tcTX7rrzo6y2+LbB19zKx7bByKFsaXN0tcS12tK7uPaho3F1ZXVltKbA7czhuanSu9axtsHIobW9z/vPos6q1rm1xLe9t6jS1M3io6zSsszhuanX7rOktci0/bbByKHP+8+itcS3vbeoo6zV4tH5tsHIoc/fs8zDu9PQsdjSqtK71rG1yLT9z/vPoqOsv8nS1NTatci0/dK7ts7KsbzkuvPIpbSmwO3G5Mv7tcTIzs7xoaPG5EO94bm5tqjS5cjnz8I6CjxwcmUgY2xhc3M9"brush:sql;">struct ib_wqueue_t
{
ib_mutex_t mutex; /*互斥量*/
ib_list_t* items; /*用list作為queue的載體*/
os_event_t event; /*信號量*/
};
4.哈希表
innodb中的哈希表的基本構造和傳統的哈希表的構造是相似的,不同的就是innodb的哈希表采用的是自定義鏈式桶結構,而沒有采用每個桶單元用傳統的list來做碰撞管理。由於這個特性,innodb中的哈希表操作采用了一系列操作宏來做操作,這樣做的目的是為了能泛型的對哈希表做操作,因為在innodb中,除了操作內存中的數據以外,還會操作隱射硬盤中的數據。以下是innodb的操作宏:
HASH_INSERT 插入操作
HASH_DELETE 刪除操作
HASH_GET_FIRST 獲取指定HASH key對應cell的第一個數據單元
HASH_GET_NEXT 獲取cell_node對應的下一個單元
HASH_SEARCH 查找對應key的值
HASH_SEARCH_ALL 遍歷整個hash table並將每個數據單元為參數執行ASSERTION操作
HASH_DELETE_AND_COMPACT 刪除操作並且優化和調整heap堆上的內存分配布局,使得heap效率更高
HASH_MIGRATE 將OLD_TABLE的數據單元合並到NEW_TABLE當中
這些宏在調用的時候都會指定數據的類型和Next函數名。
innodb的哈希表在多線程並發模式下也提供cell級粒度的鎖,有mutex類型的鎖,也有rw_lock類型的鎖。在hash_create_sync_obj_func函數調用過程中,會創建一個n_sync_obj的鎖數據單元,n_sync_obj必須是2的N次方。也就是說如果n_sync_obj
= 8, 哈希表的n_cells = 19,那就至少兩個cell公用一個鎖。這是其他哈希表無法比擬的。
以下是hash table的結構定義:
struct hash_table_t
{
enum hash_table_sync_t type; /*hash table的同步類型*/
ulint n_cells; /*hash桶個數*/
hash_cell_t* array; /*hash桶數組*/
#ifndef UNIV_HOTBACKUP
ulint n_sync_obj;
union{ /*同步鎖*/
ib_mutex_t* mutexes;
rw_lock_t* rw_locks;
}sync_obj;
/*heaps的單元個數和n_sync_obj一樣*/
mem_heap_t** heaps;
#endif
mem_heap_t* heap;
ulint magic_n; /*校驗魔法字*/
#endif
};
5.小結
Innodb還有其他的一些數據結構,例如最小堆,這些都是通用的封裝,也就不做過多的描述,在可以去看看innodb的源碼相關就可以。innodb在定義數據結構的時候做了特殊的處理,例如對線程並發的控制,對內存分配的控制。這樣做的目的是為了統一的管理。innodb的代碼是C的,但支持C++。裡面並沒有使用STL這種傳統的數據結構和算法,很大程度上是適合性的問題。據說MYSQL 5.7開始大量使用boost 和STL。個人感覺STL還勉強,使用boost有點步子邁大了的感覺。