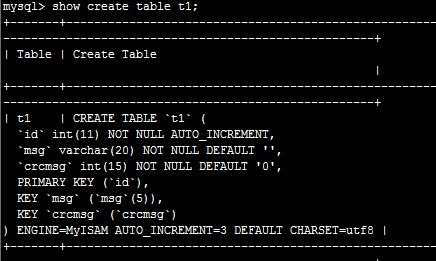
創建表
CREATE TABLE `t1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`msg` varchar(20) NOT NULL DEFAULT '',
`crcmsg` int(15) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=3 DEFAULT CHARSET=utf8
//插入數據
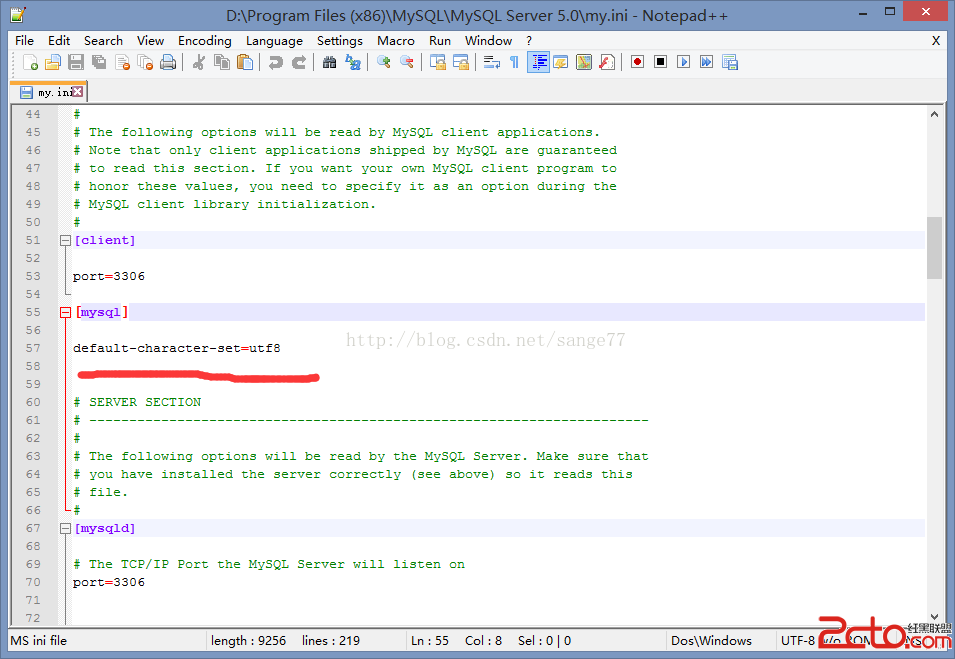
insert into t1 (msg) values('www.baidu.com'),('www.sina.com');
分別給msg, crcmsg 字段添加索引
alter table t1 add index msg(msg(5));
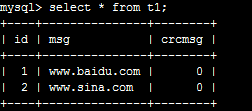
update t1 set crcmsg=crc32(msg);
alter table t1 add index crcmsg(crcmsg);
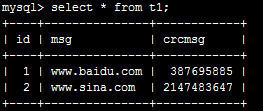
開始做測試
最後數據表結構
根據key_len的長度的大小從而給數據庫查詢提高速度。
自己做的小測試,希望能夠給您帶來收獲,祝您工作愉快。
索引用於快速找到特定一些值的記錄。如果沒有索引,MySQL就必須從第一行記錄開始讀取整個表來檢索記錄。表越大,資源消耗越大。如果在字段上有索引的話,MySQL就能很快決定該從數據文件的哪個位置開始搜索記錄,而無須查找所有的數據。如果表中有1000條記錄的話,那麼這至少比順序地讀取數據快100倍。注意,如果需要存取幾乎全部1000條記錄的話,那麼順序讀取就更快了,因為這樣會使磁盤搜索最少。
大部分MySQL索引(PRIMARY KEY, UNIQUE,INDEX 和 FULLTEXT)都是以B樹方式存儲。只有空間類型的字段使用R樹存儲,MEMORY (HEAP)表支持哈希索引。
字符串默認都是自動壓縮前綴和後綴中的空格。
通常,如下所述幾種情況下可以使用索引。哈希索引(用於 MEMORY 表)的獨特之處在後面會討論到。
想要盡快找到匹配 WHERE 子句的記錄。
根據條件排除記錄。如果有多個索引可共選擇的話,MySQL通常選擇能找到最少記錄的那個索引。
做表連接查詢時從其他表中檢索記錄。
想要在指定的索引字段 key_col 上找到它的 MIN() 或 MAX() 值。優化程序會在檢查索引的
key_col 字段前就先檢查其他索引部分是否使用了 WHERE key_part_# = constant 子句。這樣的話,
MySQL會為 MIN() 或 MAX() 表達式分別單獨做一次索引查找,並且將它替換成常數。當所有的表達式都被替換成常數後,查詢就立刻返回。如下:
SELECT MIN(key_part2),MAX(key_part2) FROM tbl_name WHERE key_part1=10;
對表作排序或分組,當在一個可用的最左前綴索引上做分組或排序時(如 ORDER
BY key_part1, key_part2)。如果所有的索引部分都按照 DESC 排序,索引就按倒序排序。
有些時候,查詢可以優化使得無需計算數據就能直接取得結果。當查詢使用表中的一個數字型字段,且這個字段是索引的最左部分,則可能從索引樹中能很快就取得結果:
SELECTkey_part3FROMtbl_nameWHEREkey_part1=1
假設有如下 SELECT 語句:
如果在 col1 和 col2 上有一個多字段索引的話,就能直接取得對應的記錄了。
貌似 HASH索引只能用在MEMORY/HEAP類型表裡,這種格式的沒用過