一、存儲過程
存儲過程(Stored Procedure)是在大型數據庫系統中,一組為了完成特定功能的SQL語句集,經編譯後存儲在數據庫中,用戶
通過指定存儲過程的名字並給出參數(如果該存儲過程帶有參數)來執行它。而我們常用的操作數據庫語言SQL語句在執行的時
候需要要先編譯,然後執行,所以執行的效率沒有存儲過程高。
存儲過程優點如下:
重復使用。存儲過程可以重復使用,從而可以減少數據庫開發人員的工作量。提高性能。存儲過程在創建的時候在進行了編譯,將來使用的時候不再重新翻譯。一般的SQL語句每執行一次就需要編譯一次,所以使用存儲過程提高了效率。減少網絡流量。存儲過程位於服務器上,調用的時候只需要傳遞存儲過程的名稱以及參數就可以了,因此降低了網絡傳輸的數據量。安全性。參數化的存儲過程可以防止SQL注入式攻擊,而且可以將Grant、Deny以及Revoke權限應用於存儲過程。
存儲過程簡單語法:
CREATE PROCEDURE 存儲過程名稱( 輸入輸出類型 變量名稱 類型, 輸入輸出類型 變量名稱 類型 ) BEGIN -- 聲明, 語句要完成的操作,增刪改查。。。 END
二、實例
例子中的存儲過程均使用mysql作為例子。
表結構如下:
DROP TABLE IF EXISTS `person`;
CREATE TABLE `person` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`password` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8;
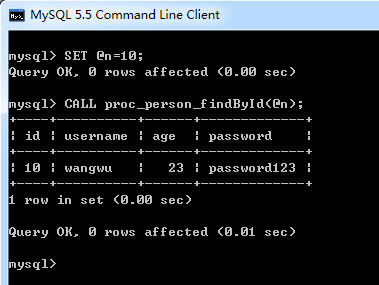
1、只帶IN(輸入參數)的存儲過程
表示該參數的值必須在調用存儲過程時指定,在存儲過程中修改該參數的值不能被返回,為默認值.
DROP PROCEDURE IF EXISTS proc_person_findById;
-- 創建存儲過程
CREATE PROCEDURE proc_person_findById(
in n int
)
BEGIN
SELECT * FROM person where id=n;
END
-- 定義變量
SET @n=2;
-- 調用存儲過程
CALL proc_person_findById(@n);
調用結果如下:
2、只帶OUT(輸出參數)的存儲過程
該值可在存儲過程內部被改變,並可返回。
DROP PROCEDURE IF EXISTS proc_person_getCount
-- 創建存儲過程
CREATE PROCEDURE proc_person_getCount(
out n int(11)
)
BEGIN
SELECT COUNT(*) INTO n FROM person ;
END
-- 調用存儲過程
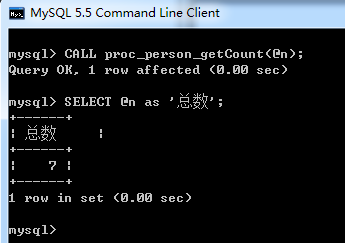
CALL proc_person_getCount(@n);
SELECT @n as '總數';
調用結果如下:
3、帶IN(輸入參數)和OUT(輸出參數)的
調用時指定,並且可被改變和返回
DROP PROCEDURE IF EXISTS proc_person_findInfoById;
-- 創建存儲過程
CREATE PROCEDURE proc_person_findInfoById(
IN n INT(11),
OUT pusername VARCHAR(255),
OUT page INT(11)
)
BEGIN
SELECT username, age INTO pusername, page FROM person WHERE id=n;
END
-- 定義變量
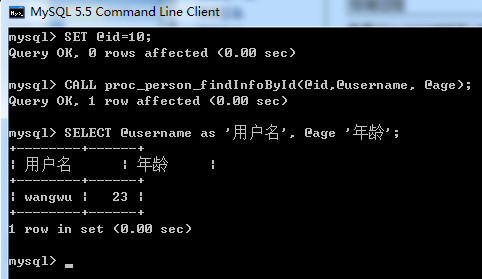
SET @id=2;
-- 調用存儲過程
CALL proc_person_findInfoById(@id,@username, @age);
SELECT @username as '用戶名', @age '年齡';
調用結果如下:
4、帶INOUT(輸入輸出)參數的存儲過程
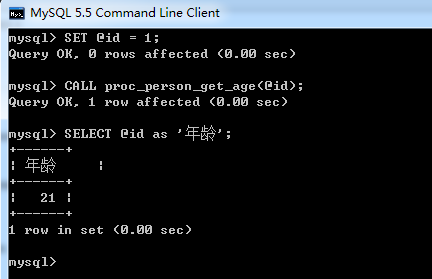
-- 輸入輸出DROP PROCEDURE IF EXISTS proc_person_get_age;-- 創建存儲過程CREATE PROCEDURE proc_person_get_age( INOUT n INT(11))BEGIN SELECT age INTO N FROM person WHERE id=n;ENDSET @id = 1;CALL proc_person_get_age(@id); SELECT @id;
調用結果如下:
5、 關於輸入輸出參數
IN為輸入, 定義參數時,可以不加,不加則默認為輸入參數。OUT為輸出,定義參數時,必須加上。INOUT為輸入和輸出,必須加上。表示該參數可以輸入也可在處理後存放結果進行輸出。
1 用mysql客戶端登入
2 選擇數據庫
mysql>use test
3 查詢當前數據庫有哪些存儲過程
mysql>show procedure status where Db='test'
4 創建一個簡單的存儲過程
mysql>create procedure hi() select 'hello';
5 存儲過程創建完畢,看怎麼調用它
mysql>call hi();
顯示結果 mysql> call hi();
+-------+
| hello |
+-------+
| hello |
+-------+
1 row in set (0.00 sec) Query OK, 0 rows affected (0.01 sec)
6 一個簡單的儲存過程就成功了
建立存儲過程
Create procedure、Create function
下面是它們的格式:
Create proceduresp_Name ([proc_parameter ])
routine_body
這裡的參數類型可以是 IN OUT INOUTT ,意思和單詞的意思是一樣的,IN 表示是傳進來的參數,
OUT 是表示傳出去的參數,INOUT 是表示傳進來但最終傳回的參數。
Create functionsp_Name ([func_parameter ])
Returns type
Routine_body
Returns type 指定了返回的類型,這裡給定的類型與返回值的類型要是一樣的,否則會報錯。
下面給出兩個簡單的例子來說明:
1、 顯示 Mysql 當前版本
執行結果
mysql> use welefen;
Database changed
mysql> delimiter // #定義//作為結束標記符號
mysql> create procedure getversion(out param1 varchar(50)) #param1為傳出參數
-> begin
-> select version() into param1; #將版本的信息賦值給 param1
-> end
-> //
Query OK, 0 rows affected (0.00 sec)
mysql> call getversion(@a); #調用getversion()這個存儲過程
-> //
Query OK, 0 rows affected (0.00 sec)
mysql> select @a;
-> //
+--------------------------+
| @a |
+--------------------------+
| 5.1.14-beta-community-nt |
+--------------------------+
1 row in set (0.00 sec)
2、 顯示”hello world”
執行結果
mysql> delimiter //
mysql> create function display(w varchar(20)) returns varchar(50)
-> begin
-> return concat('hello ‘,w);
-> end
......余下全文>>