同樣的,只會講解跟SQLSERVER不同的地方
插入
將多行查詢結果插入到表中
語法
INSERT INTO table_name1(column_list1) SELECT (column_list2) FROM table_name2 WHERE (condition)
INSERT INTO SELECT 在SQLSERVER裡也是支持的
table_name1指定待插入數據的表;column_list1指定待插入表中要插入數據的哪些列;table_name2指定插入數據是從
哪個表中查詢出來的;column_list2指定數據來源表的查詢列,該列表必須和column_list1列表中的字段個數相同,數據類型相同;
condition指定SELECT語句的查詢條件
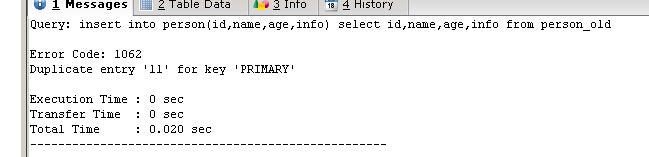
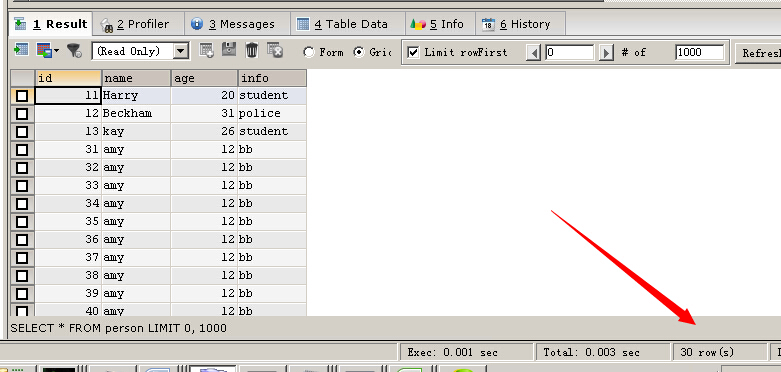
從person_old表中查詢所有的記錄,並將其插入到person表
CREATE TABLE person ( id INT UNSIGNED NOT NULL AUTO_INCREMENT, NAME CHAR(40) NOT NULL DEFAULT '', age INT NOT NULL DEFAULT 0, info CHAR(50) NULL, PRIMARY KEY (id) ) CREATE TABLE person_old ( id INT UNSIGNED NOT NULL AUTO_INCREMENT, NAME CHAR(40) NOT NULL DEFAULT '', age INT NOT NULL DEFAULT 0, info CHAR(50) NULL, PRIMARY KEY (id) ) INSERT INTO person_old VALUES (11,'Harry',20,'student'),(12,'Beckham',31,'police') SELECT * FROM person_old
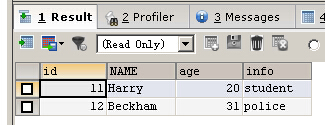
可以看到,插入記錄成功,person_old表現在有兩條記錄。接下來將person_oldperson_old表中的所有記錄插入到person表
INSERT INTO person(id,NAME,age,info) SELECT id,NAME,age,info FROM person_old; SELECT * FROM person
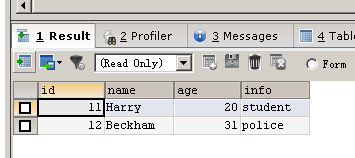
可以看到數據轉移成功,這裡的id字段為自增的主鍵,在插入時要保證該字段值的唯一性,如果不能確定,可以插入的時候忽略該字段,
只插入其他字段的值
如果再執行一次就會出錯
MYSQL和SQLSERVER的區別:
區別一
當要導入的數據中有重復值的時候,MYSQL會有三種方案
方案一:使用 ignore 關鍵字
方案二:使用 replace into
方案三:ON DUPLICATE KEY UPDATE
第二和第三種方案這裡不作介紹,因為比較復雜,而且不符合要求,這裡只講第一種方案
TRUNCATE TABLE person TRUNCATE TABLE persona_old INSERT INTO person_old VALUES (11,'Harry',20,'student'),(12,'Beckham',31,'police') ##注意下面這條insert語句是沒有ignore關鍵字的 INSERT INTO person(id,NAME,age,info) SELECT id,NAME,age,info FROM person_old; INSERT INTO person_old VALUES (13,'kay',26,'student') ##注意下面這條insert語句是有ignore關鍵字的 INSERT IGNORE INTO person(id,NAME,age,info) SELECT id,NAME,age,info FROM person_old;
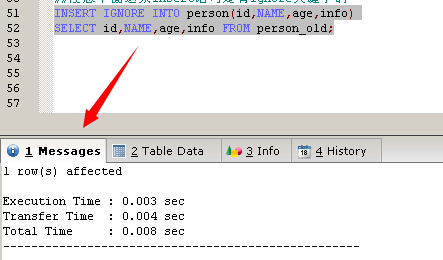
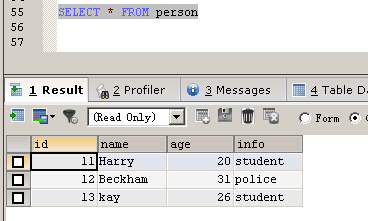
可以看到插入成功
SQLSERVER
在SQLSERVER這邊,如果要忽略重復鍵,需要在建表的時候指定 WITH (IGNORE_DUP_KEY = ON) ON [PRIMARY]
這樣在插入重復值的時候,SQLSERVER第一次會保留值,第二次發現有重復值的時候,SQLSERVER就會忽略掉
區別二
插入自增列時的區別
SQLSERVER需要使用 SET IDENTITY_INSERT 表名 ON 才能把自增字段的值插入到表中,如果不加 SET IDENTITY_INSERT 表名 ON
則在插入數據到表中時,不能指定自增字段的值,則id字段不能指定值,SQLSERVER會自動幫你自動增加一
INSERTINTO person(NAME,age,info) VALUES ('feicy',33,'student')
而MYSQL則不需要,而且自由度非常大
你可以將id字段的值指定為NULL,MYSQL會自動幫你增一
INSERTINTO person(id,NAME,age,info) VALUES (NULL,'feicy',33,'student')
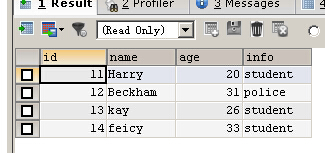
也可以指定值
INSERT IGNORE INTO person(id,NAME,age,info) VALUES (16,'tom',88,'student')
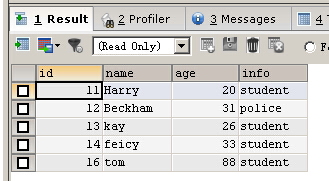
也可以不寫id的值,MYSQL會自動幫你增一
INSERT IGNORE INTO person(NAME,age,info) VALUES ('amy',12,'bb')
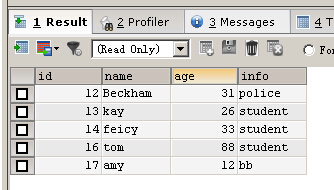
你可以指定id字段的值也可以不指定,指定的時候只要當前id字段列沒有你正在插入的那個值就可以,即沒有重復值就可以
自由度非常大,而且無須指定 SET IDENTITY_INSERT 表名 ON 選項
區別三
唯一索引的NULL值重復問題
MYSQL
在MYSQL中UNIQUE 索引將會對null字段失效
insert into test(a) values(null) insert into test(a) values(null)
上面的插入語句是可以重復插入的(聯合唯一索引也一樣)
SQLSERVER
SQLSERVER則不行
CREATE TABLE person (
id INT NOT NULL IDENTITY(1,1),
NAME CHAR(40) NULL DEFAULT '',
age INT NOT NULL DEFAULT 0,
info CHAR(50) NULL,
PRIMARY KEY (id)
)
CREATE UNIQUE INDEX IX_person_unique ON [dbo].[person](name)
INSERT INTO [dbo].[person]
( [NAME], [age], [info] )
VALUES ( NULL, -- NAME - char(40)
1, -- age - int
'aa' -- info - char(50)
),
( NULL, -- NAME - char(40)
2, -- age - int
'bb' -- info - char(50)
)
消息 2601,級別 14,狀態 1,第 1 行 不能在具有唯一索引“IX_person_unique”的對象“dbo.person”中插入重復鍵的行。重復鍵值為 (<NULL>)。 語句已終止。
更新
更新比較簡單,就不多說了
UPDATE person SET info ='police' WHERE id BETWEEN 14 AND 17 SELECT * FROM person
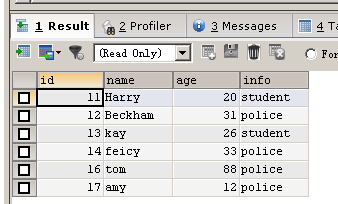
刪除
刪除person表中一定范圍的數據
DELETE FROM person WHERE id BETWEEN 14 AND 17 SELECT * FROM person
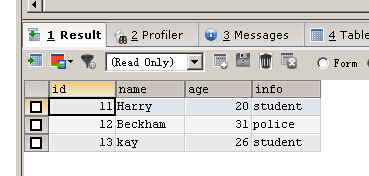
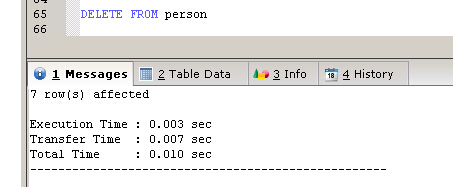
如果要刪除表的所有記錄可以使用下面的兩種方法
##方法一
DELETE FROM person
##方法二
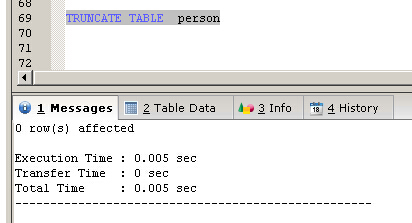
TRUNCATE TABLE person
跟SQLSERVER一樣,TRUNCATE TABLE會比DELETE FROM TABLE 快
MYISAM引擎下的測試結果,30行記錄
跟SQLSERVER一樣,執行完TRUNCATE TABLE後,自增字段重新從一開始。
################################
INSERT IGNORE INTO person(id,NAME,age,info)
SELECT id,NAME,age,info FROM person_old;
SELECT * FROM person
TRUNCATE TABLE person
INSERT IGNORE INTO person(NAME,age,info) VALUES ('amy',12,'bb')
SELECT * FROM person
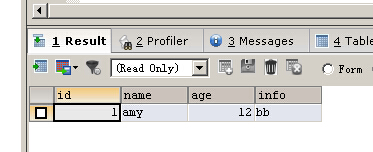
當你剛剛truncate了表之後執行下面語句就會看到重新從一開始
SHOW TABLE STATUS LIKE 'person'
總結
這一節介紹了MYSQL裡的的插入、更新和刪除,並且比較了與SQLSERVER的區別,特別是MYSQL裡插入語句的靈活性
剛剛開始從SQLSERVER轉過來可能會有一些不適應
如有不對的地方,歡迎大家拍磚o(∩_∩)o
mssql和mysql的區別
mssql 是微軟的那個 SQL Server,運行於windows 2000,2003等平台
mysql 是個開源的數據庫Server,可運行在windows平台、unix\\linux平台,其標准版是免費的,可以到www.mysql.com 看看
asp\\php只是一種解釋語言,不一定mssql不能用php,也不一定mysql非得用php,只不過asp-mssql,php-mysql是一種常用的組合
SQL數據庫完全手冊_1
SQL是Structured Quevy Language(結構化查詢語言)的縮寫。SQL是專為數據庫而建立的操作命令集,是一種功能齊全的數據庫語言。在使用它時,只需要發出“做什麼”的命令,“怎麼做”是不用使用者考慮的。SQL功能強大、簡單易學、使用方便,已經成為了數據庫操作的基礎,並且現在幾乎所有的數據庫均支持SQL。
##1 二、SQL數據庫數據體系結構
SQL數據庫的數據體系結構基本上是***結構,但使用術語與傳統關系模型術語不同。在SQL中,關系模式(模式)稱為“基本表”(base table);存儲模式(內模式)稱為“存儲文件”(stored file);子模式(外模式)稱為“視圖”(view);元組稱為“行”(row);屬性稱為“列”(column)。名稱對稱如^00100009a^:
##1 三、SQL語言的組成
在正式學習SQL語言之前,首先讓我們對SQL語言有一個基本認識,介紹一下SQL語言的組成:
1.一個SQL數據庫是表(Table)的集合,它由一個或多個SQL模式定義。
2.一個SQL表由行集構成,一行是列的序列(集合),每列與行對應一個數據項。
3.一個表或者是一個基本表或者是一個視圖。基本表是實際存儲在數據庫的表,而視圖是由若干基本表或其他視圖構成的表的定義。
4.一個基本表可以跨一個或多個存儲文件,一個存儲文件也可存放一個或多個基本表。每個存儲文件與外部存儲上一個物理文件對應。
5.用戶可以用SQL語句對視圖和基本表進行查詢等操作。在用戶角度來看,視圖和基本表是一樣的,沒有區別,都是關系(表格)。
6.SQL用戶可以是應用程序,也可以是終端用戶。SQL語句可嵌入在宿主語言的程序中使用,宿主語言有FORTRAN,COBOL,PASCAL,PL/I,C和Ada語言等。SQL用戶也能作為獨立的用戶接口,供交互環境下的終端用戶使用。
##1 四、對數據庫進行操作
SQL包括了所有對數據庫的操作,主要是由4個部分組成:
1.數據定義:這一部分又稱為“SQL DDL”,定義數據庫的邏輯結構,包括定義數據庫、基本表、視圖和索引4部分。
2.數據操縱:這一部分又稱為“SQL DML”,其中包括數據查詢和數據更新兩大類操作,其中數據更新又包括插入、刪除和更新三種操作。
3.數據控制:對用戶訪問數據的控制有基本表和視圖的授權、完整性規則的描述,事務控制語句等。
4.嵌入式SQL語言的使用規定:規定SQL語句在宿主語言的程序中使用的規則。
下面我們將分別介紹:
##2 (一)數據定義
SQL數據定義功能包括定義數據庫、基本......余下全文>>
還是更新好一些,每刪除再插入,主鍵就會增加一個數字,而且刪除和插入,是要對數據庫做兩次操作,而update只做一次