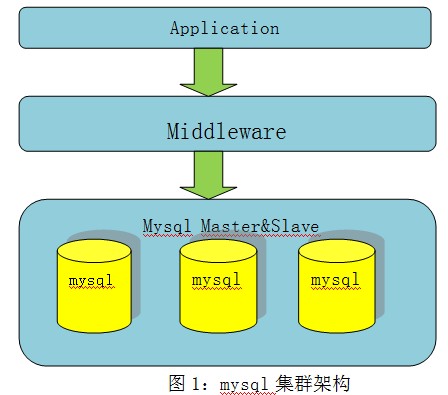
互聯網網站應用大多采用mysql作為DB存儲,限於mysql單機性能的瓶頸,為了支撐更大容量和更大的訪問量,dba一般通過建立分布式集群,讓多個mysql共同提供服務。所謂的mysql分布式集群,實質就是將原有的數據拆成多份,放在多個mysql數據庫上存儲,應用通過中間層路由到對應的數據庫分片,訪問所需要數據,基本架構如圖1所示。這裡的關鍵點就是“拆”,如何拆庫,根據業務場景,一般可以采取水平拆分和垂直拆分。所謂水平拆分是指,將一個大表按一定的規則分片,分布在多個mysql數據庫中;垂直拆分則是指根據業務模塊劃分,將不同模塊分布在不同的mysql數據庫中。無論是水平拆分,還是垂直拆分,對於底層運維人員來說,遷移擴容的本質是一樣的。本文會結合一個具體的例子,詳細講解mysql拆庫的具體步驟。
前提:mysq集群部署采用MM架構,Master與Slave采用雙向復制,Master對外提供服務,Slave作為熱備。
假設:實例上有庫A和庫B,目前受限於單機mysql的性能瓶頸,需要擴容。
目的:將庫B拆出來,使得庫A和庫B分別單獨占用物理機,如圖2所示
實施步驟:
1.搭建備庫
Mysql搭建備庫主要有兩種方式,邏輯備份(mysqldump)或物理備份(extrabackup)。由於我們需要將其中一個庫拆出來,選擇mysqldump會比較合適。
mysqldump -uxxx -pxxx –h ip_addr -P port --databases B mysql --master-data=2 --single-transaction --default-character-set=xxx > /u01/bak/B_dump.sql 2>/u01/bak/B_dump.log &
說明:
1) 參數
--master-data=2,--single-transaction這兩個參數一起使用,全局讀鎖只會在dump開始的時候加一小段時間,通過設置repeatable read隔離級別,保證讀取事務開始時的數據,獲取一致性數據,並且在備份文件開頭處顯示位點(File,Position)。
2) 為什麼要備份mysql庫
這裡是因為數據庫的元數據信息都存儲在mysql中,比如表定義,用戶信息等,因此需要一起備份過去。
2.檢查備份是否成功
查看/u01/bak/B_dump.sql的結尾是否有dump complete
查看/u01/bak/B_dump.log文件是否異常輸出
3.導入備份到新機器
Mysql –uroot</u01/bak/B_dump.sql>B_import.log 2>&1 &
4.導入增量
1) 由於老庫上面有A,B兩個庫,新庫只有B庫,通過復制獲取增量時,必然會導致報錯,因此在導入前需要對新庫設置復制過濾參數,replicate-do-db
replicate-do-db=mysql
replicate-do-db=B
2) 新庫與老庫建立復制關系,這裡需要用到步驟1獲取的位點信息(File,Position)
CHANGE master TO master_host=xxx, master_port=xxx,master_user='slave',master_password='slave',
master_log_file=File,master_log_pos=Position;
5. 等待新庫與老庫同步,至此新庫與老庫復制結構如下圖

6. 切換
1) 將New M設置為可寫狀態,並將Old M與New M構成雙M架構

備注:紅色代表本次操作的復制變動
2) 通知應用將B庫流量切換到New Master,由於這裡設置到中間件的細節,不同公司采用的中間件不一樣,這裡不作說明
3) B庫流量全部切換到New Master 後,檢查Old Master是否還有B庫流量訪問,確定沒有,調整復制結構

備注:檢查是否還有流量,可以通過show processlist看看是否還有連接來驗證。
7.切換完畢,斷開New Master 和Old Master的復制

8.善後
清理Old Master的B庫數據,釋放磁盤空間。
直接到mysql的數據庫目錄下。
linux 下是 mysql/var/數據庫名稱/表名稱.*
windows下是mysql\data\數據庫名稱\表名稱。*
拷出去就可以了,當然最好是先中斷mysql的運行。
這個是韓老師將的玩轉oracle
www.ixueyun.com/...4.html