今天一個朋友向我咨詢怎麼去優化 MySQL,我按著思維整理了一下,大概粗的可以分為21個方向。 還有一些細節東西(table cache, 表設計,索引設計,程序端緩存之類的)先不列了,對一個系統,初期能把下面做完也是一個不錯的系統。
1. 要確保有足夠的內存
數據庫能夠高效的運行,最關建的因素需要內存足更大了,能緩存住數據,更新也可以在內存先完成。但不同的業務對內存需要強度不一樣,一推薦內存要占到數據的15-25%的比例,特別的熱的數據,內存基本要達到數據庫的80%大小。
2. 需要更多更快的CPU
MySQL 5.6可以利用到64個核,而MySQL每個query只能運行在一個CPU上,所以要求更多的CPU,更快的CPU會更有利於並發。
3. 要選擇合適的操作系統
在官方建議估計最推薦的是Solaris, 從實際生產中看CentOS, REHL都是不錯的選擇,推薦使用CentOS, REHL 版本為6以後的,當然Oracle Linux也是一個不錯的選擇。雖然從MySQL 5.5後對Windows做了優化,但也不推薦在高並發環境中使用windows.
4. 合理的優化系統的參數
更改文件句柄 ulimit –n 默認1024 太小
進程數限制 ulimit –u 不同版本不一樣
禁掉NUMA numctl –interleave=all
5. 選擇合適的內存分配算法
默認的內存分配就是c的malloc 現在也出現許多優化的內存分配算法:
jemalloc and tcmalloc
從MySQL 5.5後支持聲明內存儲方法。
復制代碼 代碼如下:
[mysqld_safe]
malloc-lib = tcmalloc
或是直接指到so文件
復制代碼 代碼如下:
[mysqld_safe]
malloc-lib=/usr/local/lib/libtcmalloc_minimal.so
6. 使用更快的存儲設備ssd或是固態卡
存儲介質十分影響MySQL的隨機讀取,寫入更新速度。新一代存儲設備固態ssd及固態卡的出現也讓MySQL 大放異彩,也是淘寶在去IOE中干出了一個漂亮仗。
7. 選擇良好的文件系統
推薦XFS, Ext4,如果還在使用ext2,ext3的同學請盡快升級別。 推薦XFS,這個也是今後一段時間Linux會支持一個文件系統。
文件系統強烈推薦: XFS
8. 優化掛載文件系統的參數
掛載XFS參數:
復制代碼 代碼如下:(rw, noatime,nodiratime,nobarrier)
掛載ext4參數:
復制代碼 代碼如下:ext4 (rw,noatime,nodiratime,nobarrier,data=ordered)
如果使用SSD或是固態盤需要考慮:
• innodb_page_size = 4K
• Innodb_flush_neighbors = 0
9. 選擇適合的IO調度
正常請下請使用deadline 默認是noop
復制代碼 代碼如下:echo dealine >/sys/block/{DEV-NAME}/queue/scheduler
10. 選擇合適的Raid卡Cache策略
請使用帶電的Raid,啟用WriteBack, 對於加速redo log ,binary log, data file都有好處。
11. 禁用Query Cache
Query Cache在Innodb中有點雞肋,Innodb的數據本身可以在Innodb buffer pool中緩存,Query Cache屬於結果集緩存,如果開啟Query Cache更新寫入都要去檢查query cache反而增加了寫入的開銷。
在MySQL 5.6中Query cache是被禁掉了。
12. 使用Thread Pool
現在一個數據對應5個以上App場景比較,但MySQL有個特性隨著連接增多的情況下性能反而下降,所以對於連接超過200的以後場景請考慮使用thread pool. 這是一個偉大的發明。
13. 合理調整內存
13.1 減少連接的內存分配
連接可以用thread_cache_size緩存,觀查屬於比較屬不如thread pool給力。數據庫在連上分配的內存如下:
復制代碼 代碼如下:
max_used_connections * (
read_buffer_size +
read_rnd_buffer_size +
join_buffer_size +
sort_buffer_size +
binlog_cache_size +
thread_stack +
2 * net_buffer_length …
)
13.2 使較大的buffer pool
要把60-80%的內存分給innodb_buffer_pool_size. 這個不要超過數據大小了,另外也不要分配超過80%不然會利用到swap.
14. 合理選擇LOG刷新機制
Redo Logs:
復制代碼 代碼如下:
– innodb_flush_log_at_trx_commit = 1 // 最安全
– innodb_flush_log_at_trx_commit = 2 // 較好性能
– innodb_flush_log_at_trx_commit = 0 // 最好的情能
binlog :
binlog_sync = 1 需要group commit支持,如果沒這個功能可以考慮binlog_sync=0來獲得較佳性能。
數據文件:
復制代碼 代碼如下:innodb_flush_method = O_DIRECT
15. 請使用Innodb表
可以利用更多資源,在線alter操作有所提高。 目前也支持非中文的full text, 同時支持Memcache API訪問。目前也是MySQL最優秀的一個引擎。
如果你還在MyISAM請考慮快速轉換。
16. 設置較大的Redo log
以前Percona 5.5和官方MySQL 5.5比拼性能時,勝出的一個Tips就是分配了超過4G的Redo log ,而官方MySQL5.5 redo log不能超過4G. 從 MySQL 5.6後可以超過4G了,通常建Redo log加起來要超過500M。 可以通過觀查redo log產生量,分配Redo log大於一小時的量即可。
17. 優化磁盤的IO
innodb_io_capactiy 在sas 15000轉的下配置800就可以了,在ssd下面配置2000以上。
在MySQL 5.6:
復制代碼 代碼如下:
innodb_lru_scan_depth = innodb_io_capacity / innodb_buffer_pool_instances
innodb_io_capacity_max = min(2000, 2 * innodb_io_capacity)
18. 使用獨立表空間
目前來看新的特性都是獨立表空間支持:
truncate table 表空間回收
表空間傳輸
較好的去優化碎片等管理性能的增加,
整體上來看使用獨立表空間是沒用的。
19. 配置合理的並發
innodb_thread_concurrency =並發這個參數在Innodb中變化也是最頻繁的一個參數。不同的版本,有可能不同的小版本也有變動。一般推薦:
在使用thread pool 的情況下:
innodb_thread_concurrency = 0 就可以了。
如果在沒有thread pool的情況下:
5.5 推薦:innodb_thread_concurrency =16 – 32
5.6 推薦innodb_thread_concurrency = 36
20. 優化事務隔離級別
默認是 Repeatable read
推薦使用Read committed binlog格式使用mixed或是Row
較低的隔離級別 = 較好的性能
21. 注重監控
任環境離不開監控,如果少了監控,有可能就會陷入盲人摸象。 推薦zabbix+mpm構建監控。
1、選取最適用的字段屬性
MySQL 可以很好的支持大數據量的存取,但是一般說來,數據庫中的表越小,在它上面執行的查詢也就會越快。因此,在創建表的時候,為了獲得更好的性能,我們可以將表中字段的寬度設得盡可能小。例如,在定義郵政編碼這個字段時,如果將其設置為CHAR(255),顯然給數據庫增加了不必要的空間,甚至使用VARCHAR這種類型也是多余的,因為CHAR(6)就可以很好的完成任務了。同樣的,如果可以的話,我們應該使用MEDIUMINT而不是BIGIN來定義整型字段。
另外一個提高效率的方法是在可能的情況下,應該盡量把字段設置為NOT NULL,這樣在將來執行查詢的時候,數據庫不用去比較NULL值。
對於某些文本字段,例如“省份”或者“性別”,我們可以將它們定義為ENUM類型。因為在MySQL中,ENUM類型被當作數值型數據來處理,而數值型數據被處理起來的速度要比文本類型快得多。這樣,我們又可以提高數據庫的性能。
2、使用連接(JOIN)來代替子查詢(Sub-Queries)
MySQL 從4.1開始支持SQL的子查詢。這個技術可以使用SELECT語句來創建一個單列的查詢結果,然後把這個結果作為過濾條件用在另一個查詢中。例如,我們要將客戶基本信息表中沒有任何訂單的客戶刪除掉,就可以利用子查詢先從銷售信息表中將所有發出訂單的客戶ID取出來,然後將結果傳遞給主查詢,如下所示:
DELETE FROM customerinfo
WHERE CustomerID NOT in (SELECT CustomerID FROM salesinfo )
使用子查詢可以一次性的完成很多邏輯上需要多個步驟才能完成的SQL操作,同時也可以避免事務或者表鎖死,並且寫起來也很容易。但是,有些情況下,子查詢可以被更有效率的連接(JOIN).. 替代。例如,假設我們要將所有沒有訂單記錄的用戶取出來,可以用下面這個查詢完成:
SELECT * FROM customerinfo
WHERE CustomerID NOT in (SELECT CustomerID FROM salesinfo )
如果使用連接(JOIN).. 來完成這個查詢工作,速度將會快很多。尤其是當salesinfo表中對CustomerID建有索引的話,性能將會更好,查詢如下:
SELECT * FROM customerinfo
LEFT JOIN salesinfoON customerinfo.CustomerID=salesinfo.
CustomerID
WHERE salesinfo.CustomerID IS NULL
連接(JOIN).. 之所以更有效率一些,是因為 MySQL不需要在內存中創建臨時表來完成這個邏輯上的需要兩個步驟的查詢工作。
3、使用聯合(UNION)來代替手動創建的臨時表
MySQL 從 4.0 的版本開始支持 UNION 查詢,它可以把需要使用臨時表的兩條或更多的 SELECT 查詢合並的一個查詢中。在客戶端的查詢會話結束的時候,臨時表會被自動刪除,從而保證數據庫整齊、高效。使用 UNION 來創建查詢的時候,我們只需要用 UNION作為關鍵字把多個 SELECT 語句連接起來就可以了,要注意的是所有 SELECT 語句中的字段數目要想同。下面的例子就演示了一個使用 UNION的查詢。
SELECT Name, Phone FROM client
UNION
SELECT Name, BirthDate FROM author......余下全文>>
優化器的作用在於統計表信息,定制最優查詢方案,達到提高查詢效率的作用,
通過優化器分析後的sql語句是不會有變化的,但是內部的執行計劃會根據實際情況改變
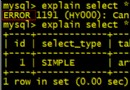
查看sql執行計劃的命令:
explain sql
例:
explain select * from test;